机器学习学习笔记(一)
题外话---------------------
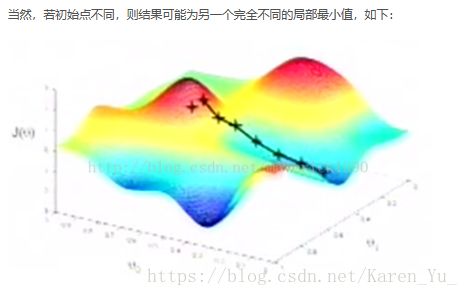
好像很久没有更新了,这学期事比较多,然后之前的几篇博客写的也不是很好的样子,会尽量在假期整理一下。
写在前面------------------
言归正传,这个学习笔记会长期更新,具体内容以及图片之类的来源主要依赖于同类型的博客以及正在听的B站上的公开课(地址如下:https://www.bilibili.com/video/av14111147?from=search&seid=1948962273802098210 )
会依据b站分p来整理
牵涉到matlab以及线代等等的知识可能会备注,也可能直接放链接酱紫。
然后可能会写一些自己的理解,会用斜体标出,但是因为刚刚接触可能不具有参考性,如果有问题,请大家不吝珠玉在评论区之处,十分感谢。
因为是照着我的纸质笔记打的,听课的时候又查了很多资料,一个字一个字打时间代价太高,就会复制粘贴别人的博客,但是都会注明出处
---------------------------------------------------------------------------
P1 机器学习的动因及应用
学习前要求掌握:
1.计算机科学基本知识&基本技能及原理
2.O
3.数据结构(队列、栈、二叉树)
4、基本的概率统计
5、线性代数
definition:
(1959)Field of study that gives computers the ability to learn withoutbeing explicitly programmed.
(1998)A computer program is said to learn from experience E,with respect to some task T and some performance measure P,if its performance on T,as measured by P, improves with experience E.
定义,简而言之,就是让机器学习。
这里提到了:①监督学习(Supervised Learning)②学习理论(Learning Theory)
③无监督学习(Unsupervised Learning)④强化学习(Reinforcement Learning)
视频在这里举了几个例子来说明这四种算法,都很有意思。记得比较清楚的是鸡尾酒会问题(可参见https://www.jianshu.com/p/94ed7e6c67ed),还有就是图像处理等等。
P2 监督学习应用与梯度下降
首先是本课程贯穿始终的几个标记符:
m:训练样本的数量(就是给机器学习的信息的数量)
x:输入变量(查询)
y:输出变量或称目标变量(由既定模型推导出的结果)
(x,y):一个样本(从这里可以看出,一个样本就是一个条件+一个结论)
(x(i),y(i)):第i个样本(注:这里的(i)是上标)
注:当然,x可以不止一个,毕竟生活中影响因素是有很多的
监督学习:告诉算法每个样本的正确答案,学习后的算法对新的输入也能输入正确的答案。监督指的是在训练样本答案的监督下。
(也就是说,每一个问题都有其标准答案)

(也就是训练集通过算法得到函数h,输入x,x经过h的作用得到y)
在上节课提到了一个关于房子的面积和价格的例子,数据如下:

监督学习过程:
1) 将训练样本提供给学习算法
2) 算法生成一个输出函数(一般用h表示,成为假设)
3) 这个函数接收输入,输出结果。(本例中为,接收房屋面积,输出房价)将x映射到y。

因为式子很难打出来,所以就用了截屏,来源:https://blog.csdn.net/crcr/article/details/39481307
关于梯度下降,就要先提一下梯度,这个在高数里有提到过(梯度的本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。)
(和高数那个感觉很像,就是容易联想到地理中学过的等高线,然后就想地理老师教我们怎么找山脊(好像是这么叫的),就是沿着等高线下降的方向这样去找)
梯度下降算法的思想是,我们要选取一个初使点,可能是0向量,也可能是一个随机生成的点。想象看到的图形是一个三维地表:
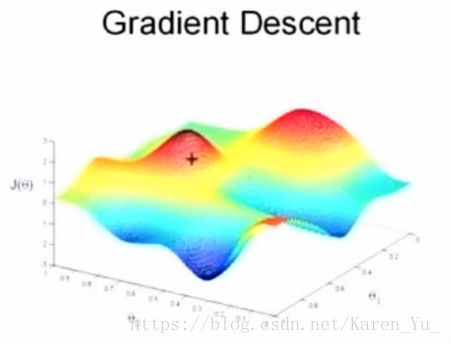
想象这个图描述的是你所处的环境,你的周围有很多小山。你站在其中一点,转一圈,然后选择下山最快的路,走一步,继续转一圈,再选择下山最快的路,再走一步。事实上这个下山最快的方向正是梯度的方向,直到你达到了这个山的最低点,也就是这个函数的一个局部最小值。
这里有学生提问,如何让机器环顾四周(笑),老师给的回答是,通过计算偏导数(总之和高数讲梯度的那里高度一致啦)



回归在数学上来说是给定一个点集,能够用一条曲线去拟合之,如果这个曲线是一条直线,那就被称为线性回归,如果曲线是一条二次曲线,就被称为二次回归,回归还有很多的变种,如locally weighted回归,logistic回归,等等。
用一个很简单的例子来说明回归,大概就是,做一个房屋价值的评估系统,一个房屋的价值来自很多地方,比如说面积、房间的数量(几室几厅)、地 段、朝向等等,这些影响房屋价值的变量被称为特征(feature)
假设有一个房屋销售的数据如下:
面积(m^2) 销售价钱(万元)
123 250
150 320
87 160
102 220
… …
这个表类似于帝都5环左右的房屋价钱,我们可以做出一个图,x轴是房屋的面积。y轴是房屋的售价,如下:

如果来了一个新的面积,假设在销售价钱的记录中没有的,我们怎么办呢?
我们可以用一条曲线去尽量准的拟合这些数据,然后如果有新的输入过来,我们可以在将曲线上这个点对应的值返回。如果用一条直线去拟合,可能是下面的样子:

绿色的点就是我们想要预测的点。
首先给出一些概念和常用的符号,在不同的机器学习书籍中可能有一定的差别。
房屋销售记录表 - 训练集(training set)或者训练数据(training data), 是我们流程中的输入数据,一般称为x
房屋销售价钱 - 输出数据,一般称为y
拟合的函数(或者称为假设或者模型),一般写做 y = h(x)
训练数据的条目数(#training set), 一条训练数据是由一对输入数据和输出数据组成的
输入数据的维度(特征的个数,#features),n
下面是一个典型的机器学习的过程,首先给出一个输入数据,我们的算法会通过一系列的过程得到一个估计的函数,这个函数有能力对没有见过的新数据给出一个新的估计,也被称为构建一个模型。就如同上面的线性回归函数。

我们用X1,X2..Xn 去描述feature里面的分量,比如x1=房间的面积,x2=房间的朝向,等等,我们可以做出一个估计函数:
![]()
θ在这儿称为参数,在这儿的意思是调整feature中每个分量的影响力,就是到底是房屋的面积更重要还是房屋的地段更重要。为了如果我们令X0 = 1,就可以用向量的方式来表示了:
![]()
我们程序也需要一个机制去评估我们θ是否比较好,所以说需要对我们做出的h函数进行评估,一般这个函数称为损失函数(loss function)或者错误函数(error function),描述h函数不好的程度,在下面,我们称这个函数为J函数
在这儿我们可以做出下面的一个错误函数:

这个错误估计函数是去对x(i)的估计值与真实值y(i)差的平方和作为错误估计函数,前面乘上的1/2是为了在求导的时候,这个系数就不见了。
(引用自https://www.cnblogs.com/ECJTUACM-873284962/p/8620058.html)
(1) 批梯度下降算法:
上述为处理一个训练样本的公式,将其派生成包含m个训练样本的算法,循环下式直至收敛:
![]()
复杂度分析:
对于每个![]() 的每次迭代,即上式所示,时间为O(m)
的每次迭代,即上式所示,时间为O(m)
每次迭代(走一步)需要计算n个特征的梯度值,复杂度为O(mn)
一般来说,这种二次函数的![]() 的三维图形为一个碗状,有一个唯一的全局最小值。其等高线为一个套一个的椭圆形,运用梯度下降会快速收敛到圆心。
的三维图形为一个碗状,有一个唯一的全局最小值。其等高线为一个套一个的椭圆形,运用梯度下降会快速收敛到圆心。

梯度下降性质:接近收敛时,每次的步子会越来越小。其原因是每次减去![]() 乘以梯度,但是梯度会越来越小,所以步子会越来越小。
乘以梯度,但是梯度会越来越小,所以步子会越来越小。
下图为使用梯度下降拟合的上例房屋大小和价格的曲线

检测是否收敛的方法:
1) 检测两次迭代![]() 的改变量,若不再变化,则判定收敛
的改变量,若不再变化,则判定收敛
2) 更常用的方法:检验![]() ,若不再变化,判定收敛
,若不再变化,判定收敛
批梯度下降算法的优点是能找到局部最优解,但是若训练样本m很大的话,其每次迭代都要计算所有样本的偏导数的和,当训练集合数据量大时效率比较低,需要的时间比较长,于是采用下述另一种梯度下降方法。
(2) 随机梯度下降算法(增量梯度下降算法):

每次计算![]() 不需要再遍历所有数据,而是只需计算样本i即可。
不需要再遍历所有数据,而是只需计算样本i即可。
即批梯度下降中,走一步为考虑m个样本;随机梯度下降中,走一步只考虑1个样本。
每次迭代复杂度为O(n)。当m个样本用完时,继续循环到第1个样本。
增量梯度下降算法可以减少大训练集收敛的时间(比批量梯度下降快很多),但可能会不精确收敛于最小值而是接近最小值。
上述使用了迭代的方法求最小值,实际上对于这类特定的最小二乘回归问题,或者普通最小二乘问题,存在其他方法给出最小值,接下来这种方法可以给出参数向量的解析表达式,如此一来就不需要迭代求解了。
正规方程组
给定一个函数J,J是一个关于参数数组的函数,定义J的梯度关于的导数,它自己也是一个向量。向量大小为n+1维(从0到n),如下:

所以,梯度下降算法可写成:![]()
J:关于参数数组的函数;
下三角:梯度
更普遍的讲,对于一个函数f,f的功能是将一个m*n的矩阵映射到实数空间上,即:![]()
假设输入为m*n大小的矩阵A,定义f关于矩阵A的导数为:

导数本身也是个矩阵,包含了f关于A的每个元素的偏导数。
如果A是一个方阵,即n*n的矩阵,则将A的迹定义为A的对角元素之和,即:

trA即为tr(A)的简化。迹是一个实数。
一些关于迹运算符和导数的定理:
1) trAB = trBA
2) trABC = trCAB = trBCA
3) ![]()
4) ![]()
5) 若![]() ,tra = a
,tra = a
6) ![]()
有了上述性质,可以开始推导了:
定义矩阵X,称为设计矩阵,包含了训练集中所有输入的矩阵,第i行为第i组输入数据,即:

则由于![]() ,所以可得:
,所以可得:
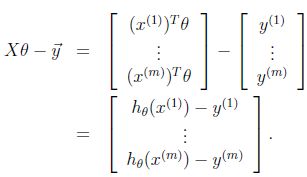
又因为对于向量z,有![]() ,则有:
,则有:
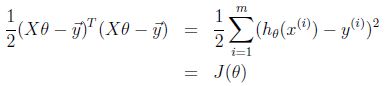
由上述最后一个性质可得:![]()
通过上述6个性质,推导:

倒数第三行中,运用最后一个性质
将![]() 置为0,则有:
置为0,则有:![]()
称为正规方程组
可得:![]()
结束P2之前再安利一个博客:https://blog.csdn.net/xiazdong/article/details/7950084
还有就是有关线性代数的内容,如果时间足够而且还想顺便练英语的话,安利http://open.163.com/special/opencourse/daishu.html
如果没时间的话,可以先简要了解一下相关的计算方法:
①逆矩阵https://jingyan.baidu.com/article/925f8cb8a74919c0dde056e7.html
②特征方程https://jingyan.baidu.com/article/6fb756ec6f8624241858fbda.html
③矩阵的迹https://blog.csdn.net/caimouse/article/details/59697453
P3 欠拟合与过拟合概念
(所谓欠拟合,就是特征集过少导致模型过于简单,简而言之就是可能误差较大;所谓过拟合就是特征集过大导致模型过于复杂,简而言之就是不具有代表性)
一下内容来自https://blog.csdn.net/maverick1990/article/details/11721453
复习:
![]() –第i个训练样本
–第i个训练样本
令![]() ,以参数向量
,以参数向量![]() 为条件,对于输入x,输出为:
为条件,对于输入x,输出为:
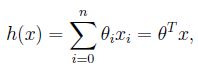
n为特征数量
定义成本函数J,定义为:

m为训练样本
通过正规方程组推导的结论:
![]()
1、 过拟合与欠拟合
通常,你选择交给学习算法处理的特征的方式对算法的工作过程有很大影响。
例:上次课的例子中,用x1表示房间大小。通过线性回归,在横轴为房间大小,纵轴为价格的图中,画出拟合曲线。回归的曲线方程为:![]()
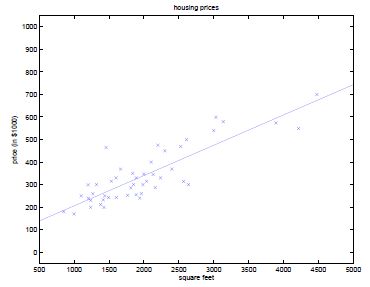
若定义特征集合为:x1表示房子大小,x2表示房子大小的平方,使用相同的算法,拟合得到一个二次函数,在图中即为一个抛物线,即:![]()
以此类推,若训练集有7个数据,则可拟合出最高6次的多项式,可以找到一条完美的曲线,该曲线经过每个数据点。但是这样的模型又过于复杂,拟合结果仅仅反映了所给的特定数据的特质,不具有通过房屋大小来估计房价的普遍性。而线性回归的结果可能无法捕获所有训练集的信息。
所以,对于一个监督学习模型来说,过小的特征集合使得模型过于简单,过大的特征集合使得模型过于复杂。
对于特征集过小的情况,称之为欠拟合(underfitting);
对于特征集过大的情况,称之为过拟合(overfitting)
解决此类学习问题的方法:
1) 特征选择算法:一类自动化算法,在这类回归问题中选择用到的特征
2) 非参数学习算法:缓解对于选取特征的需求,引出局部加权回归
参数学习算法(parametric learning algorithm)
定义:参数学习算法是一类有固定数目参数,以用来进行数据拟合的算法。设该固定的参数集合为![]() 。线性回归即使参数学习算法的一个例子
。线性回归即使参数学习算法的一个例子
非参数学习算法(Non-parametric learning algorithm)
定义:一个参数数量会随m(训练集大小)增长的算法。通常定义为参数数量虽m线性增长。换句话说,就是算法所需要的东西会随着训练集合线性增长,算法的维持是基于整个训练集合的,即使是在学习以后。
2、 局部加权回归(Locally Weighted Regression)
一种特定的非参数学习算法。也称作Loess。
算法思想:
假设对于一个确定的查询点x,在x处对你的假设h(x)求值。
对于线性回归,步骤如下:
1) 拟合出![]() ,使
,使![]() 最小
最小
2) 返回![]()
对于局部加权回归,当要处理x时:
1) 检查数据集合,并且只考虑位于x周围的固定区域内的数据点
2) 对这个区域内的点做线性回归,拟合出一条直线
3) 根据这条拟合直线对x的输出,作为算法返回的结果
用数学语言描述即:
1) 拟合出![]() ,使
,使![]() 最小
最小
2) w为权值,有很多可能的选择,比如:

- 其意义在于,所选取的x(i)越接近x,相应的w(i)越接近1;x(i)越远离x,w(i)越接近0。直观的说,就是离得近的点权值大,离得远的点权值小。
- 这个衰减函数比较具有普遍意义,虽然它的曲线是钟形的,但不是高斯分布。
- ![]() 被称作波长函数,它控制了权值随距离下降的速率。它越小,钟形越窄,w衰减的很快;它越大,衰减的就越慢。
被称作波长函数,它控制了权值随距离下降的速率。它越小,钟形越窄,w衰减的很快;它越大,衰减的就越慢。
3) 返回![]()
总结:对于局部加权回归,每进行一次预测,都要重新拟合一条曲线。但如果沿着x轴对每个点都进行同样的操作,你会得到对于这个数据集的局部加权回归预测结果,追踪到一条非线性曲线。
*局部加权回归的问题:
由于每次进行预测都要根据训练集拟合曲线,若训练集太大,每次进行预测的用到的训练集就会变得很大,有方法可以让局部加权回归对于大型数据集更高效,详情参见Andrew Moore的关于KD-tree的工作。
3、 概率解释
概率解释所解决的问题:
在线性回归中,为什么选择最小二乘作为计算参数的指标,使得假设预测出的值和真正y值之间面积的平方最小化?
我们提供一组假设,证明在这组假设下最小二乘是有意义的,但是这组假设不唯一,还有其他很多方法可以证明其有意义。
(1) 假设1:
假设输入与输出为线性函数关系,表示为:![]()
其中,![]() 为误差项,这个参数可以理解为对未建模效应的捕获,如果还有其他特征,这个误差项表示了一种我们没有捕获的特征,或者看成一种随机的噪声。
为误差项,这个参数可以理解为对未建模效应的捕获,如果还有其他特征,这个误差项表示了一种我们没有捕获的特征,或者看成一种随机的噪声。
假设![]() 服从某个概率分布,如高斯分布(正态分布):
服从某个概率分布,如高斯分布(正态分布):![]() ,表示一个均值是0,方差是
,表示一个均值是0,方差是![]() 的高斯分布。
的高斯分布。
高斯分布的概率密度函数:
![]()
根据上述两式可得:

即,在给定了特征与参数之后,输出是一个服从高斯分布的随机变量,可描述为:![]()
*为什么选取高斯分布?
1) 便于数学处理
2) 对绝大多数问题,如果使用了线性回归模型,然后测量误差分布,通常会发现误差是高斯分布的。
3) 中心极限定律:若干独立的随机变量之和趋向于服从高斯分布。若误差有多个因素导致,这些因素造成的效应的总和接近服从高斯分布。
注意:![]() 并不是一个随机变量,而是一个尝试估计的值,就是说它本身是一个常量,只不过我们不知道它的值,所以上式中用分号表示。分号应读作“以…作为参数”,上式读作“给定x(i)以为参数的y(i)的概率服从高斯分布”。
并不是一个随机变量,而是一个尝试估计的值,就是说它本身是一个常量,只不过我们不知道它的值,所以上式中用分号表示。分号应读作“以…作为参数”,上式读作“给定x(i)以为参数的y(i)的概率服从高斯分布”。
假设每个 为IID(independently and identically distributed)独立同分布
即误差项彼此之间是独立的,并且他们服从均值和方差相同的高斯分布
(2) 假设2:
设![]() 的似然性为(即给定x(i)以为参数的y(i)的概率):
的似然性为(即给定x(i)以为参数的y(i)的概率):![]()
由于![]() 是独立同分布,所以上式可写成所有分布的乘积:
是独立同分布,所以上式可写成所有分布的乘积:
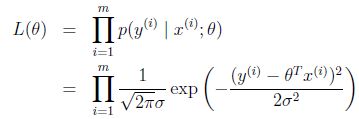
(3)假设3:
极大似然估计:选取![]() 使似然性
使似然性![]() 最大化(数据出现的可能性尽可能大)
最大化(数据出现的可能性尽可能大)
定义对数似然函数为![]() :
:
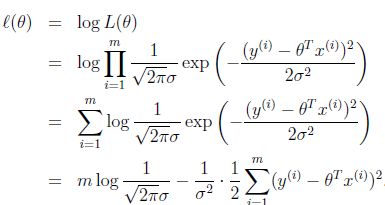
上式两个加项,前一项为常数。所以,使似然函数最大,就是使后一项最小,即:

这一项就是之前的![]() ,由此得证,即之前的最小二乘法计算参数,实际上是假设了误差项满足高斯分布,且独立同分布的情况,使似然最大化来计算参数。
,由此得证,即之前的最小二乘法计算参数,实际上是假设了误差项满足高斯分布,且独立同分布的情况,使似然最大化来计算参数。
注意:高斯分布的方差对最终结果没有影响,由于方差一定为正数,所以无论取什么值,最后结果都相同。这个性质会在下节课讲到。
4、 Logistic回归
这是我们要学习的第一个分类算法。之前的回归问题尝试预测的变量y是连续变量,在这个分类算法中,变量y是离散的,y只取{0,1}两个值。
一般这种离散二值分类问题用线性回归效果不好。比如x<=3,y=0;x>3,y=1,那么当x>3的样本占得比例很大是,线性回归的直线斜率就会越来越小,y=0.5时对应的x判决点就会比3大,造成预测错误。
若y取值{0,1},首先改变假设的形式,使假设得到的值总在[0,1]之间,即:![]()
所以,选取如下函数:
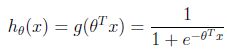
其中:
![]()
g函数一般被称为logistic函数,图像如下:

z很小时,g(z)趋于0,z很大时,g(z)趋于1,z=0时,g(z)=0.5
对假设的概率解释:
假设给定x以为参数的y=1和y=0的概率:
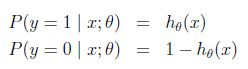
可以简写成:![]()
参数的似然性:

求对数似然性:

为了使似然性最大化,类似于线性回归使用梯度下降的方法,求对数似然性对![]() 的偏导,即:
的偏导,即:
![]()
因为求最大值,此时为梯度上升。
偏导数展开:

则:
![]()
即类似上节课的随机梯度上升算法,形式上和线性回归是相同的,只是符号相反,![]() 为logistic函数,但实质上和线性回归是不同的学习算法。
为logistic函数,但实质上和线性回归是不同的学习算法。
5、 感知器算法
在logistic方法中,g(z)会生成[0,1]之间的小数,但如何是g(z)只生成0或1?
所以,感知器算法将g(z)定义如下:

同样令![]() ,和logistic回归的梯度上升算法类似,学习规则如下:
,和logistic回归的梯度上升算法类似,学习规则如下:
![]()
尽管看起来和之前的学习算法类似,但感知器算法是一种非常简便的学习算法,临界值和输出只能是0或1,是比logistic更简单的算法。后续讲到学习理论是,会将其作为基本的构造步骤。
(想简要谈一下个人的看法,单单从前三节课的内容来看,还不是很能理解机器学习到底如何操作,不过可以看出来的是,无论是梯度下降还是梯度上升包括后面会提到的牛顿方法,都是在解决如何处理数据使得数据能代表普遍情况,以便做出预测或者说决策。当然这是个人的观点)
还有就是关于课程内容的注释:
①高斯分布的概率密度函数(高斯分布就是大家熟悉的正态分布):
高斯分布(Gaussian Distribution)的概率密度函数(probability density function)
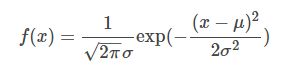 (看百度百科的意思是这个是一维情况,然而我也不是很确定百度百科的正确性)
(看百度百科的意思是这个是一维情况,然而我也不是很确定百度百科的正确性)
然后这个是维基的链接https://en.m.wikipedia.org/wiki/Normal_distribution个人觉得写的还不错
②似然性https://blog.csdn.net/lwq1026/article/details/70161857原来是数理里的概念,还没学难怪听课的时候一直听不明白,不过这个没有关系,很初步的概念和高中关系挺大的,可以回忆一下
在开始P4之前,再安利一个博客https://www.cnblogs.com/shixiangwan/p/7532830.html
P4 牛顿方法
第一遍听课的时候就听懂了几点:1.牛顿方法很快……2.牛顿方法与前面的各种梯度的区别还有这个是二阶收敛。3.牛顿方法大概在计算上比较麻烦?
(私以为可以理解为就像一次函数和二次函数的区别那样。二次函数比一次函数增长的速度快,但是同样的在计算上就没有一阶线性那么美好了。就像解题的各种方法里,最快的、或者说最美的,可能思维量最大、或者说往往需要另辟蹊径……扯远了)
(啊啊啊,好不容易编完的东西又不见了,是不是又有bug了)
引用自:http://www.cnblogs.com/BYRans/p/4720436.html
逻辑回归中利用Sigmoid函数g(z)和梯度上升来最大化ℓ(θ)。现在我们讨论另一个最大化ℓ(θ)的算法----牛顿方法。
牛顿方法是使用迭代的方法寻找使f(θ)=0的θ值,在这里θ是一个真实的值,不是一个参数,只不过θ的真正取值不确定。牛顿方法数学表达式为:

牛顿方法简单的理解方式为:先随机选一个点,然后求出f在该点的切线,即f在该点的导数。该切线等于0的点,即该切线与x轴相交的点为下一次迭代的值。直至逼近f等于0的点。过程如下图:

牛顿方法最大化Likelihood
牛顿方法提供了一种寻找f(θ)=0的θ值的方法。怎么用于最大化似然函数ℓ (θ)呢?ℓ的最大值对应点处的一阶导数ℓ'(θ)为零。所以让f(θ) = ℓ'(θ),最大化ℓ (θ)就可以转化为:用牛顿方法求ℓ'(θ)=0的θ的问题。由牛顿方法的表达式,θ的迭代更新公式为:

牛顿-拉夫森迭代法(Newton-Raphson method)
逻辑回归中θ是一个向量,所以我们把上面的表达式推广到多维的情况就是牛顿-拉夫森迭代法(Newton-Raphson method),表达式如下:
![]()
表达式中![]() 表示的ℓ(θ)对
表示的ℓ(θ)对![]() 的偏导数;H是一个n*n的矩阵,称为Hessian矩阵。Hessian矩阵的表达式为:
的偏导数;H是一个n*n的矩阵,称为Hessian矩阵。Hessian矩阵的表达式为:

牛顿方法VS梯度下降
如下图是一个最小化一个目标方程的例子,红色曲线是利用牛顿法迭代求解,绿色曲线是利用梯度下降法求解:
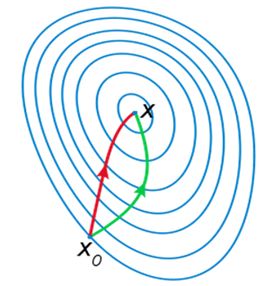
牛顿方法通常比梯度下降收敛速度快,迭代次数也少。
但因为要计算Hessian矩阵的逆,所以每次迭代计算量比较大。当Hessian矩阵不是很大时牛顿方法要优于梯度下降。
注:老师在课堂上回答学生问题的时候提到牛顿方法并不适用所有的函数,要求f必须满足一定的条件(但是老师并没有提到是什么条件,也可能是我上课走神了……)
softmax回归被普遍认为是logistic回归的推广
小结
已经写到P4了,希望可以继续坚持下去。
在这里小结一下到目前为止老师在课堂上提到的各种分布:高斯分布、伯努利分布、泊松分布、伽马分布、β分布、Wishart分布、Dirichlet分布……
(本来在这里还有各种分布的中文版介绍,但是不晓得为啥被吞了,实在没力气写了,就放在下面翻译的内容里吧)
介于个人比较喜欢维基百科英文版的介绍,觉得比较看得懂,所以就在之后放上一些摘录,希望在自己做笔记的同时也可以帮大家更好得理解。
高斯分布
In probability theory, the normal (or Gaussian or Gauss or Laplace–Gauss) distribution is a very common continuous probability distribution. Normal distributions are important in statistics and are often used in the natural and social sciences to represent real-valued random variables whose distributions are not known.[1][2] A random variable with a Gaussian distribution is said to be normally distributed and is called a normal deviate.
(抓狂!!每次都吞我的内容)
伯努利分布
In probability theory and statistics, the Bernoulli distribution, named after Swiss mathematician Jacob Bernoulli,[1] is the discrete probability distribution of a random variable which takes the value 1 with probability p {\displaystyle p} and the value 0 with probability q = 1 − p {\displaystyle q=1-p} , that is, the probability distribution of any single experiment that asks a yes–no question; the question results in a boolean-valued outcome, a single bit of information whose value is success/yes/true/one with probability p and failure/no/false/zero with probability q. It can be used to represent a coin toss where 1 and 0 would represent "head" and "tail" (or vice versa), respectively. In particular, unfair coins would have p ≠ 0.5 {\displaystyle p\neq 0.5} .
The Bernoulli distribution is a special case of the binomial distribution where a single experiment/trial is conducted (n=1). It is also a special case of the two-point distribution, for which the outcome need not be a bit, i.e., the two possible outcomes need not be 0 and 1.
| Parameters | 0 < p < 1 , p ∈ R {\displaystyle 0 |
|---|---|
| Support | k ∈ { 0 , 1 } {\displaystyle k\in \{0,1\}\,} |
| pmf | { q = ( 1 − p ) for k = 0 p for k = 1 {\displaystyle {\begin{cases}q=(1-p)&{\text{for }}k=0\\p&{\text{for }}k=1\end{cases}}} |
| CDF | { 0 for k < 0 1 − p for 0 ≤ k < 1 1 for k ≥ 1 {\displaystyle {\begin{cases}0&{\text{for }}k<0\\1-p&{\text{for }}0\leq k<1\\1&{\text{for }}k\geq 1\end{cases}}} |
| Mean | p {\displaystyle p\,} |
| Median | { 0 if q > p 0.5 if q = p 1 if q < p {\displaystyle {\begin{cases}0&{\text{if }}q>p\\0.5&{\text{if }}q=p\\1&{\text{if }}q |
| Mode | { 0 if q > p 0 , 1 if q = p 1 if q < p {\displaystyle {\begin{cases}0&{\text{if }}q>p\\0,1&{\text{if }}q=p\\1&{\text{if }}q |
| Variance | p ( 1 − p ) ( = p q ) {\displaystyle p(1-p)(=pq)\,} |
| Skewness | 1 − 2 p p q {\displaystyle {\frac {1-2p}{\sqrt {pq}}}} |
| Ex. kurtosis | 1 − 6 p q p q {\displaystyle {\frac {1-6pq}{pq}}} |
| Entropy | − q ln ( q ) − p ln ( p ) {\displaystyle -q\ln(q)-p\ln(p)\,} |
| MGF | q + p e t {\displaystyle q+pe^{t}\,} |
| CF | q + p e i t {\displaystyle q+pe^{it}\,} |
| PGF | q + p z {\displaystyle q+pz\,} |
| Fisher information | 1 p ( 1 − p ) {\displaystyle {\frac {1}{p(1-p)}}} |
泊松分布
In probability theory and statistics, the Poisson distribution (French pronunciation: [pwasɔ̃]; in English often rendered /ˈpwɑːsɒn/), named after French mathematician Siméon Denis Poisson, is a discrete probability distribution that expresses the probability of a given number of events occurring in a fixed interval of time or space if these events occur with a known constant rate and independently of the time since the last event.[1] The Poisson distribution can also be used for the number of events in other specified intervals such as distance, area or volume.
For instance, an individual keeping track of the amount of mail they receive each day may notice that they receive an average number of 4 letters per day. If receiving any particular piece of mail does not affect the arrival times of future pieces of mail, i.e., if pieces of mail from a wide range of sources arrive independently of one another, then a reasonable assumption is that the number of pieces of mail received in a day obeys a Poisson distribution.[2] Other examples that may follow a Poisson include the number of phone calls received by a call center per hour and the number of decay events per second from a radioactive source.
Examples[edit]
The Poisson distribution may be useful to model events such as
- The number of meteorites greater than 1 meter diameter that strike Earth in a year
- The number of patients arriving in an emergency room between 10 and 11 pm
| Probability mass function 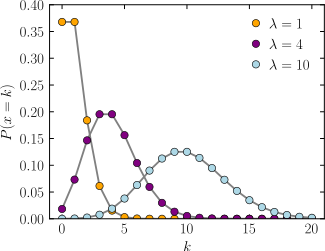 The horizontal axis is the index k, the number of occurrences. λ is the expected number of occurrences. The vertical axis is the probability of k occurrences given λ. The function is defined only at integer values of k. The connecting lines are only guides for the eye. |
|
| Cumulative distribution function 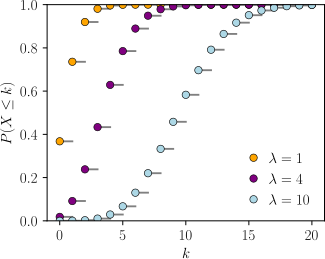 The horizontal axis is the index k, the number of occurrences. The CDF is discontinuous at the integers of k and flat everywhere else because a variable that is Poisson distributed takes on only integer values. |
|
| Parameters | λ > 0 (real) — rate |
|---|---|
| Support | k ∈ N ∪ { 0 } {\displaystyle k\in \mathbb {N} \cup \{0\}} |
| pmf | λ k e − λ k ! {\displaystyle {\frac {\lambda ^{k}e^{-\lambda }}{k!}}} |
| CDF | Γ ( ⌊ k + 1 ⌋ , λ ) ⌊ k ⌋ ! {\displaystyle {\frac {\Gamma (\lfloor k+1\rfloor ,\lambda )}{\lfloor k\rfloor !}}} , or e − λ ∑ i = 0 ⌊ k ⌋ λ i i ! {\displaystyle e^{-\lambda }\sum _{i=0}^{\lfloor k\rfloor }{\frac {\lambda ^{i}}{i!}}\ } , or Q ( ⌊ k + 1 ⌋ , λ ) {\displaystyle Q(\lfloor k+1\rfloor ,\lambda )} (for k ≥ 0 {\displaystyle k\geq 0} , where Γ ( x , y ) {\displaystyle \Gamma (x,y)} is the upper incomplete gamma function, ⌊ k ⌋ {\displaystyle \lfloor k\rfloor } is the floor function, and Q is the regularized gamma function) |
| Mean | λ {\displaystyle \lambda } |
| Median | ≈ ⌊ λ + 1 / 3 − 0.02 / λ ⌋ {\displaystyle \approx \lfloor \lambda +1/3-0.02/\lambda \rfloor } |
| Mode | ⌈ λ ⌉ − 1 , ⌊ λ ⌋ {\displaystyle \lceil \lambda \rceil -1,\lfloor \lambda \rfloor } |
| Variance | λ {\displaystyle \lambda } |
| Skewness | λ − 1 / 2 {\displaystyle \lambda ^{-1/2}} |
| Ex. kurtosis | λ − 1 {\displaystyle \lambda ^{-1}} |
| Entropy | λ [ 1 − log ( λ ) ] + e − λ ∑ k = 0 ∞ λ k log ( k ! ) k ! {\displaystyle \lambda [1-\log(\lambda )]+e^{-\lambda }\sum _{k=0}^{\infty }{\frac {\lambda ^{k}\log(k!)}{k!}}} (for large λ {\displaystyle \lambda } ) 1 2 log ( 2 π e λ ) − 1 12 λ − 1 24 λ 2 − {\displaystyle {\frac {1}{2}}\log(2\pi e\lambda )-{\frac {1}{12\lambda }}-{\frac {1}{24\lambda ^{2}}}-{}}19 360 λ 3 + O ( 1 λ 4 ) {\displaystyle \qquad {\frac {19}{360\lambda ^{3}}}+O\left({\frac {1}{\lambda ^{4}}}\right)} |
| MGF | exp ( λ ( e t − 1 ) ) {\displaystyle \exp(\lambda (e^{t}-1))} |
| CF | exp ( λ ( e i t − 1 ) ) {\displaystyle \exp(\lambda (e^{it}-1))} |
| PGF | exp ( λ ( z − 1 ) ) {\displaystyle \exp(\lambda (z-1))} |
| Fisher information | 1 λ {\displaystyle {\frac {1}{\lambda }}} |
有关分布的一篇:https://blog.csdn.net/lv_tianxiaomiao/article/details/69389761
P5 生成学习算法
(摘自:https://blog.csdn.net/andrewseu/article/details/46789121)
本讲大纲:
1.生成学习算法(Generative learning algorithm)
2.高斯判别分析(GDA,Gaussian Discriminant Analysis)
3.朴素贝叶斯(Naive Bayes)
4.拉普拉斯平滑(Laplace smoothing)
1.生成学习算法
判别学习算法(discriminative learning algorithm):直接学习p(y|x)(比如说logistic回归)或者说是从输入直接映射到{0,1}.
生成学习算法(generative learning algorithm):对p(x|y)(和p(y))进行建模.
简单的来说,判别学习算法的模型是通过一条分隔线把两种类别区分开,而生成学习算法是对两种可能的结果分别进行建模,然后分别和输入进行比对,计算出相应的概率。
比如说良性肿瘤和恶性肿瘤的问题,对良性肿瘤建立model1(y=0),对恶性肿瘤建立model2(y=1),p(x|y=0)表示是良性肿瘤的概率,p(x|y=1)表示是恶性肿瘤的概率.
根据贝叶斯公式(Bayes rule)推导出y在给定x的概率为:
2.高斯判别分析
GDA是我们要学习的第一个生成学习算法.
GDA的两个假设:
- 假设输入特征x∈Rn,并且是连续值;
- p(x|y)是多维正态分布(multivariate normal distribution);
2.1 多维正态分布
若x服从多维正态分布(也叫多维高斯分布),均值向量(mean vector)![]() ,协方差矩阵(convariance matrix)
,协方差矩阵(convariance matrix)![]() ,写成x~
,写成x~![]() , 其密度函数为:
, 其密度函数为: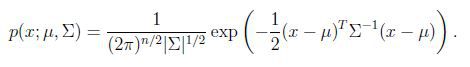
![]() 表示行列式(determinant).
表示行列式(determinant).
均值:
协方差Cov(Z)=![]() =
=![]() = ∑
= ∑
高斯分布的一些例子:
左图均值为零(2*1的零向量),协方差矩阵为单位矩阵I(2*2)(成为标准正态分布).
中图协方差矩阵为0.6I,
右图协方差矩阵为2I

均值为0,方差分别为:
2.2 高斯判别分析模型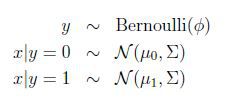
写出概率分布:
模型的参数为φ,μ0,μ1,∑,对数似然性为: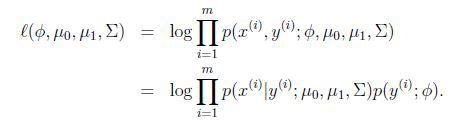
求出最大似然估计为:
结果如图所示:
1.3 讨论GDA和logistic回归
GDA模型和logistic回归有一个很有意思的关系.
如果把![]() 看做是x的函数,则有:
看做是x的函数,则有:
其中![]() 是
是![]() 的函数,这正是logistic回归的形式.
的函数,这正是logistic回归的形式.
关于模型的选择:
刚才说到如果p(x|y)是一个多维的高斯分布,那么p(y|x)必然能推出一个logistic函数;反之则不正确,p(y|x)是一个logistic函数并不能推出p(x|y)服从高斯分布.这说明GDA比logistic回归做了更强的模型假设.
- 如果p(x|y)真的服从或者趋近于服从高斯分布,则GDA比logistic回归效率高.
- 当训练样本很大时,严格意义上来说并没有比GDA更好的算法(不管预测的多么精确).
- 事实证明即使样本数量很小,GDA相对logisic都是一个更好的算法.
但是,logistic回归做了更弱的假设,相对于不正确的模型假设,具有更好的鲁棒性(robust).许多不同的假设能够推出logistic函数的形式. 比如说,如果![]()
![]() 那么p(y|x)是logistic. logstic回归在这种类型的Poisson数据中性能很好. 但是如果我们使用GDA模型,把高斯分布应用于并不是高斯数据中,结果是不好预测的,GDA就不是很好了.
那么p(y|x)是logistic. logstic回归在这种类型的Poisson数据中性能很好. 但是如果我们使用GDA模型,把高斯分布应用于并不是高斯数据中,结果是不好预测的,GDA就不是很好了.
3.朴素贝叶斯
在GDA模型中,特征向量x是连续的实数向量.如果x是离散值,我们需要另一种学习算法了.
例子:垃圾邮件分类问题
首先是把一封邮件作为输入特征,与已有的词典进行比对,如果出现了该词,则把向量的xi=1,否则xi=0,例如:
我们要对p(x|y)建模,但是假设我们的词典有50000个词,那么![]() ,如果采用多项式建模的方式,会有
,如果采用多项式建模的方式,会有![]() ,明显参数太多了,这个方法是行不通的.
,明显参数太多了,这个方法是行不通的.
为了对p(x|y)建模,我们做一个很强的假设,假设给定y,xi是条件独立(conditionally independent)的.这个假设成为朴素贝叶斯假设(Naive Bayes assumption).
因此有: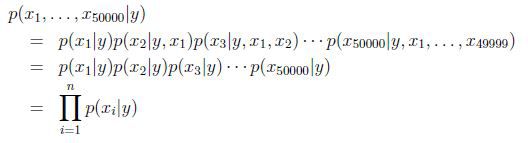
虽然说朴素贝叶斯假设是很强的,但是其实这儿算法在很多问题都工作的很好.
模型参数包括:![]()
![]()
联合似然性(joint likelihood)为: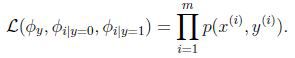
得到最大似然估计值: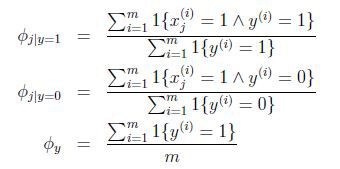
很容易计算: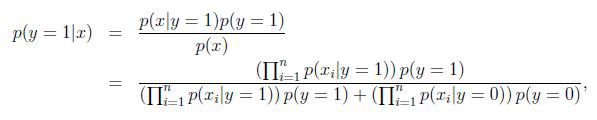
朴素贝叶斯的问题:
假设在一封邮件中出现了一个以前邮件从来没有出现的词,在词典的位置是35000,那么得出的最大似然估计为: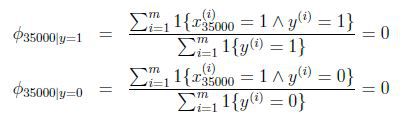
也即使说,在训练样本的垃圾邮件和非垃圾邮件中都没有见过的词,模型认为这个词在任何一封邮件出现的概率为0.
假设说这封邮件是垃圾邮件的概率比较高,那么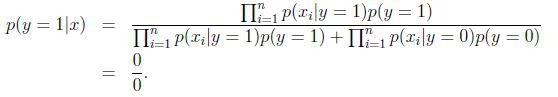
模型失灵.
在统计上来说,在你有限的训练集中没有见过就认为概率是0是不科学的.
4.laplace平滑
为了避免朴素贝叶斯的上述问题,我们用laplace平滑来优化这个问题.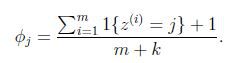
回到朴素贝叶斯问题,通过laplace平滑: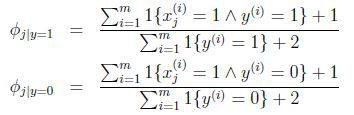
分子加1,分母加1就把分母为零的问题解决了.