大数据入门之Hadoop生态系统(2) -- HDFS概念
通过大数据入门之Hadoop生态系统(1),我们大致地了解了HDFS的概念,这里我们具体地看一下HDFS的实现原理与架构分析。
1.HDFS架构

HDFS采用的是Master/Slave架构(1个Master带多个Slave)。一个HDFS集群通常由一个Master(NameNode)和多个Slave(DataNode)构成。一个文件会被拆分成多个Block(默认每个数据块是128M),如果一个文件有130M,那么就会拆分成两个Block,一个是128M,另一个是2M。这些Blocks被存放在多个DataNode上面。
NameNode:(1)负责客户端请求的相应。 (2)负责元数据(文件的名称、副本系数、Block存放的DataNode)的管理。
DataNode:(1)存储用户的文件对应的数据块(Block)。 (2)要定期向NameNode发送心跳信息,汇报本身机器所有的Block信息,健康状况。
A typical deployment has a dedicated machine that runs only the NameNode software. Each of the other machines in the cluster runs one instance of the DataNode software. //一个典型的部署架构是,一台机器上运行一个NameNode,集群中的其它机器每一个都会运行一个DataNode。(1个NameNode + N个DataNode)。这个架构不排除运行多个DataNode在相同的机器上,但是在生产环境上我们一般不会建议这样做。建议:NameNode和DataNode部署在不同的节点上。
2.HDFS副本机制
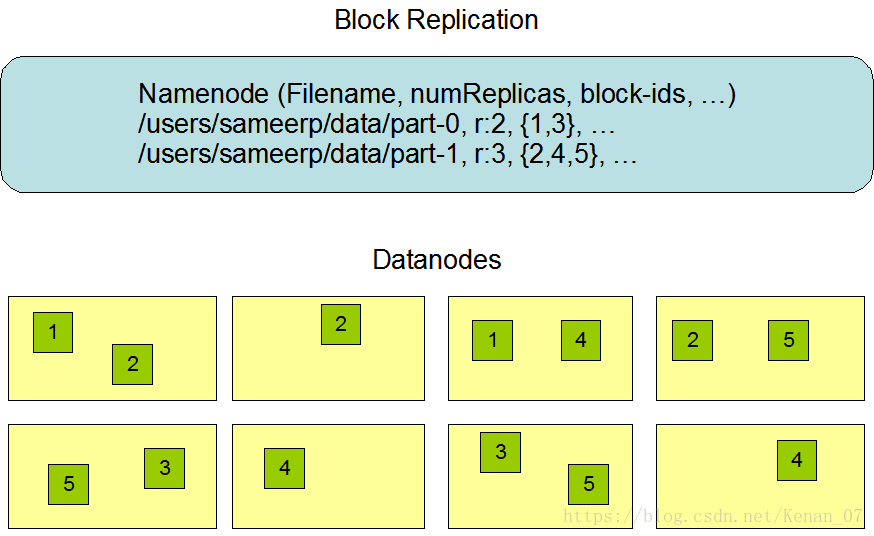
如图,每一个框框是一个机器,我们通过/users/sameerp/data/part-0 r:2,{1, 3} ...来了解一下副本机制。这里文件名就是part-0,r表示副本系数,这里有两个副本,它的Block编号是1和3。如图所示,1和3分别都有两个在不同的机器上。1和3共同组成这一个文件,因为副本系数是2,所以1和3分别要有两份。
副本存放策略:
你在客户端提交数据,一般第一个副本会在你客户端所在的节点上,第二个副本会选择放在不同服务器上的节点中,第三个副本会存放在与第二个副本相同的服务器中的不同节点中。如果副本太多的话,副本的位置会随机挑选。这样就算某个服务器挂掉了,文件数据还可以正常使用。
3.工作原理
登场人物:用户(HDFS shell命令、Java API等操作),Client(向HDFS发起读写请求),NameNode(唯一的领导,全局协调,把控请求),DataNode(一堆DataNode,负责数据存储)
写入HDFS
用户:我要写一个200MB的数据文件
Client:很荣幸为你服务,但是你是不是忘记告诉我一些东西呢?
用户:对了,我要求每个Block是128MB的,要以3副本的方式进行存储。(这些都是配置文件中的内容)
Client:首先,我要把文件拆分成多个Block(假如文件是200MB,那么就会拆分成2个Block = 128MB + 72MB)。然后我要把请求发送给NameNode,让他去写一个128MB的Block,然后以3副本方式存储。
NameNode:副本要3个,我给你找3个DataNode,好了,我找到了3个:DataNode1,DataNode2,DataNode3(按照距离远近排序)
Client:那我就把这个Block的数据发到第一个DataNode上。
DataNode1:我在接受数据的同时,我会把接收到的相同大小的数据传送到第二个DataNode上去。
DataNode2:同理,我也会把这些相同的数据发送给第三个DataNode上。
DataNode1、DataNode2、DataNode3:好了,我们都写完了。
NameNode:好了,第一个Block存完了。
Client:好的,那我对剩下的那个Block重复相同的操作就行。
--------- 当所有的Block都写完了,Client与NameNode的连接关闭,NameNode在磁盘或内存中存有元数据信息(这个文件的哪几个Block分别存放在哪几个DataNode上)-----------
读取HDFS
用户:我要读取一个文件,文件名是fileName
Client:NameNode先生,请给我fileName这个文件的信息。
NameNode:好的,我会告诉你这个文件的元数据信息(这个文件有哪些Block,分别存放在了哪些DataNode上)
Client:好的我都知道了。
------ Client发起请求与DataNode进行交互即可,Client告诉DataNode要哪一个Block,然后DataNode就会把相应的Block信息给他。 ---------
4.HDFS优缺点
优点:数据冗余、硬件容错。处理流式的数据访问(一次写入,多次读取)。适合存储大文件。构建在廉价的机器上。
缺点:低延迟的数据访问(延迟时间长)。不适合小文件存储(一个小文件存储,也会有对应的元数据存放在NameNode上,如果小文件很多,元数据占用内存也就越多,对NameNode的压力也就更大了)。
关于HDFS更多的介绍,我们可以查看HDFS官方文档。