scrapyd 部署爬虫项目
1、方便监控爬虫的实时运行状态,也可以通过接口调用开发自己的监控爬虫的页面
2、方便统一管理,可以同时启动或关闭多个爬虫
3、拥有版本控制,如果爬虫出现了不可逆的错误,可以通过接口恢复到之前的任意版本
实现功能,爬虫项目在服务器端运行,实现爬虫远程管理,不占用本机的运行空间。
=======================================================
首先 新建一个虚拟环境 使用mkvirtualenv 来新建一个虚拟环境,进入虚拟环境使用pip 将做需要的
安装包安装完成。一般有scrapy,scrapyd,等等
等安装完了,用scrapy sheel http://www.baidu.com 来验证一下是否成功
如果出现 ImportError: No module named win32api 就安装一下 pip install pywin32
因为scrapy运行需要依赖包,出现什么错误就安装 什么,知道运行正常。

尝试开启 scrapyd服务,然后打开浏览器 看服务器是否建成功。
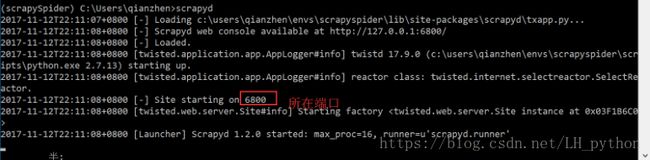

这样就 代表着服务器可以建成功,就在非C盘下新建一个文件夹,名字自定义,如果服务器在本地这个文件夹是来存放服务器获取的数据。那么就在此处开启cmd,进入虚拟环境,开启服务器,系统就会自动生成文件夹来存储信息。

安装一个scrapyd-client模块到虚拟环境中,这个模块是用来打包scrapy项目到scrapyd服务中的。
![]()
安装完成之后,会在虚拟环境中出现scrapy-deploy的启动文件,这个文件在linux中可以运行,在windows下
需要编辑使其可以运行。(新建一个文件把其名字改为 scrapyd-deploy.bat这样这个文件就可以编辑了)

进入虚拟环境,进入爬虫项目,进入带有scrapy.cfg文件的目录下,执行scrapyd-deploy,来进行测试scrapy-deploy
是否可以正常运行,如果正常出现以下样式:

这里没有显示成功是应为 我们项目中的文件还没有修改成远程连接的原因,接下来就开始修改scrapy.cfg文件。

在开始打包之前,先执行一个命令:scrapy list 这个命令成功说明就可以打包了,如果没执行成功,说明还没有开始工作
注意执行 scrapylist,
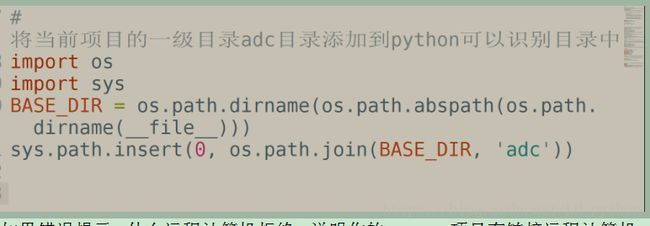
如果是python无法找到scrapy项目,需要在scrapy项目里的settings.py配置文件里设置成python可识别路径
# 将当前项目的一级目录TotalSpider目录添加到python可以识别目录中
BASE_DIR = os.path.dirname(os.path.abspath(os.path.dirname(__file__)))
sys.path.insert(0, os.path.join(BASE_DIR, “TotalSpider”))
如果错误提示,什么远程计算机拒绝,说明你的scrapy项目有链接远程计算机,如链接数据库或者elasticsearch(搜索引擎)之类的,需要先将链接服务器启动执行 。
scrapy list 命令返回了爬虫名称说明一切ok了,如下图

到此我们就可以打包scrapy项目到scrapyd了,用命令结合scrapy项目中的 scrapy.cfg文件设置来打包项目。
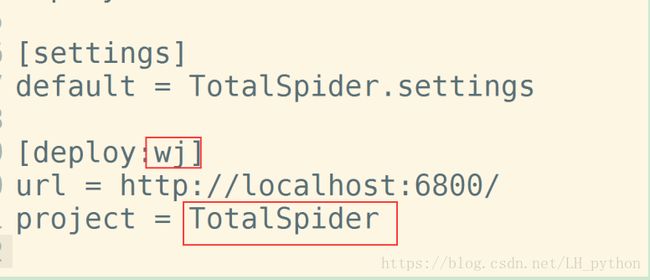
开始执行打包命令 scrapy-deploy ks -p JobSpider
如果出现

就是版本不对,建议安装pip install scrapyd==1.1.1,直到你的egg文件夹中有项目即可,如果直接安装不下来就去
官网下载低版本的。然后安装, 然后执行爬虫命令,
curl http://localhost:6800/schedule.json -d project=项目名称 -d spider=爬虫名称
![]()

以下为命令总结。。
