ROC(Receiver Operating Characteristic)曲线简介
最近在看一些医学和机器学习结合的论文,这些论文里面评价分类器的分类性能最常用的指标之一就是ROC曲线。同时我也注意到在一些涉及到实际应用的场景中,ROC曲线出现的频率也很高。鉴于以上原因,接下来我就对ROC曲线进行一下简单的介绍。
首先我们先考虑一下平时我们常用的度量分类模型分类能力的标准。现在称霸ML界的标准:分类精度(accuracy)想必大家都不陌生,但是对于一些实际情况,单纯的分类精度并不能反映分类器的真实工作状态,下面引用一位网友的例子进行说明:
“现实中样本在不同类别上的不均衡分布(class distribution imbalance problem)。使得accuracy这样的传统的度量标准不能恰当的反应分类器的performance。举个例子:测试样本中有A类样本90个,B 类样本10个。分类器C1把所有的测试样本都分成了A类,分类器C2把A类的90个样本分对了70个,B类的10个样本分对了5个。则C1的分类精度为 90%,C2的分类精度为75%。但是,显然C2更有用些。另外,在一些分类问题中犯不同的错误代价是不同的(cost sensitive learning)。这样,默认0.5为分类阈值的传统做法也显得不恰当了。”
正是因为这样的原因,ROC曲线应运而生。它能够很好的描述分类器对于不均衡分布的样本的分类性能。下面对ROC曲线用到的一些定义进行说明。
对于一个分类器的分类结果,一般有以下四种情况:
1. 真阳性(TP):判断为1,实际上也为1。
2. 伪阳性(FP):判断为1,实际上为0。
3. 真阴性(TN):判断为0,实际上也为0。
4. 伪阴性(FN):判断为0,实际上为1。
ROC空间将伪阳性率(FPR)定义为 X 轴,真阳性率(TPR)定义为 Y 轴。
TPR:在所有实际为阳性的样本中,被正确地判断为阳性之比率。
![]()
FPR:在所有实际为阴性的样本中,被错误地判断为阳性之比率。
![]()
我们可以通过调整分类器的分类阈值来获得不同的TPR/FPR对,这些数据对就是ROC的数据点。
一个ROC图形成的过程大概是这样的~~
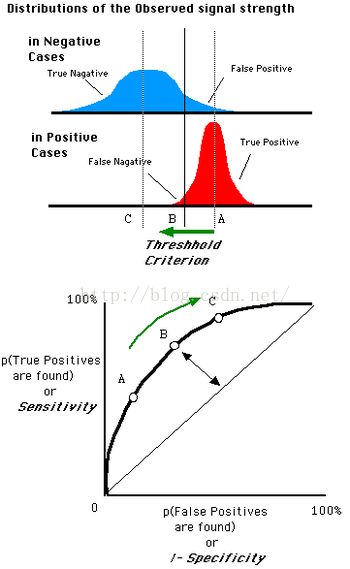
顺便说一下,ROC图是过(0,0)和(1,1)两个点的,这是因为:
当阈值设定为最高时,亦即所有样本都被预测为阴性,没有样本被预测为阳性,此时在伪阳性率 FPR = FP / ( FP + TN ) 算式中的 FP = 0,所以 FPR = 0%。同时在真阳性率(TPR)算式中, TPR = TP / ( TP + FN ) 算式中的 TP = 0,所以 TPR = 0%
→ 当阈值设定为最高时,必得出ROC座标系左下角的点 (0, 0)。
当阈值设定为最低时,亦即所有样本都被预测为阳性,没有样本被预测为阴性,此时在伪阳性率FPR = FP / ( FP + TN ) 算式中的 TN = 0,所以 FPR = 100%。同时在真阳性率 TPR = TP / ( TP +FN ) 算式中的 FN = 0,所以 TPR=100%
→ 当阈值设定为最低时,必得出ROC座标系右上角的点 (1, 1)。
另外我们把ROC曲线下面那部分的面积称为AUC,这个参数也是评估分类器分类精度的常用参数。由于ROC在1*1的方格里,所以有现实意义的AUC的值都在0.5和1之间。下面介绍AUC的判别标准:
· AUC = 1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不 存在完美分类器。
· 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
· AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
· AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。