第三章:Tensorflow 2.0 利用高级接口实现对cifar10 数据集的全连接(理论+实战实现)
理论部分
一、cifar 10 数据集简介
cifar 10相比于MNIST数据集而言更为复杂,其拥有10个种类(猫、飞机、汽车、鸟、鹿、狗、青蛙、马、船卡车),这十大类共同组成了50k的训练集,10k的测试集,每一张图片都是32*32的3通道图片(彩色图片),在神经网络中,通常表示成如下形式:
[b , w, h, c] = [b, 32 ,32, 3]
下面给出一些cifar 10 中的部分图片。我们可以看出,32*32尺寸的彩色图片是不够清晰的,所以相比于MNIST数据集,cifar 10 数据集更为复杂,少奶奶利用全连接层进行训练的话准确率最多达到0.46,但利用卷积神经网络进行计算的话,准确率大概是全连接层的两倍,这就是为什么卷积神经网络比全连接网络更受欢迎的原因。对于卷积神经网络,少奶奶将在后续博文中详细介绍,这里就不再展开赘述了。

二、损失函数------交叉熵
神经网络中给的熵
熵在不同的运用范围里,其表达的主体是不同的,在神经网络中,熵表达的意义是恒量信息的不确定度,即信息的稳定程度可以通过熵进行量化,熵越小,包含信息就越多也越不稳定,熵越大则包含的信息就越少也越稳定,具体计算公式如下:
![]()
例如:a = [0.25, 0.25, 0.25, 0.25] b = [0, 0,0, 0.25]
根据公式计算可得:
![]()
![]()
![]()
![]()
由于a的熵值比b的大,所以a包含的信息比b更加稳定,我们观察可得,a中的数值变化不大,所以稳定,而b中的数值变化是比较大的, 所以其不稳定
神经网络中的交叉熵
神经网络中的交叉熵恒量的是两个分布之间的稳定程度,通俗的讲,就是恒量标签和预测值之间的距离大小,若预测值和标签相差很大,则说明预测值中的最大值和最小值相差不大,预测结果中的数值稳定(如a所示),若预测值和标签相差不大,则说明预测值中的最大值和最小值相差很大。预测结果中的数值非常不稳定(如b所示),在神经网络中,我们希望交叉熵越小越好,即预测结果中的数值越不稳定越好。因为交叉熵越不稳定,那么预测值中数值最大的一类最有可能是正确的结果,而交叉熵越稳定,那么预测值中的较大值会出现好几个,我们就无法判断最有可能是正确的结果,具体公式如下:
![]()
而交叉熵的公式还可以表示成如下形式 :
![]()
其中:![]() 表示熵,
表示熵,![]() 表示p和q之间的散度,当p=q时,
表示p和q之间的散度,当p=q时,![]() =0,那么上述公式就会变成熵的计算公式。
=0,那么上述公式就会变成熵的计算公式。
交叉熵在神经网络中的运用
在神经网络中,交叉熵主要用于损失函数,实现标签和预测值之间的损失计算,下面少奶奶将具体讲解其计算流程。
例如:
输入一张图片:image = [1, 32, 32, 3] ,其代表cat。在cifar 10中,cat的标签label=3,则转化成one_hot编码是
one_hot = [ 0,0,0,1,0,0,0,0,0,0]
模型的预测值:pre = [ 0.01,0.01,0.01,0.91,0.01,0.01,0.01,0.01,0.01,0.01 ]
![]()
![]()
![]()
通过上述计算,我们可以明白,利用交叉熵对One_hot编码的数据进行损失计算是可行的,当然,通过对交叉熵进行求导然后根据学习率去更新权重也是可行的,只不过Tensorflow会自动为我们进行求导操作,若想知道其反向传播的本质是什么,大家可以查看少奶奶写的前置博文,希望对大家能有所帮助,
第一章:Tensorflow 2.0 实现简单的线性回归模型(理论+实践)
Tensorflow 2.0 提供的高级接口--------keras
首先,keras并不是tf.keras,这里提到的keras是Tensorflow 2.0 重新封装的高级接口,其拥有的操作方法 例如:Sequential、
complie、layers、losses、metries等,对我们构建神经网络时拥有很好的封装,我们只需要写很少的代码就能实现一个比较复杂的神经网络,当然,我们也可以利用keras自定义神经网络,少奶奶将在下一章进行讲解。这一节,少奶奶主要讲解如何利用keras的一些核心接口,实现网络层的构建。
什么是keras .Sequential()?
Sequential主要是构建神经网络模型的函数,具体用法如下:
首先在前面引入相应模块

直接调用Sequential对象
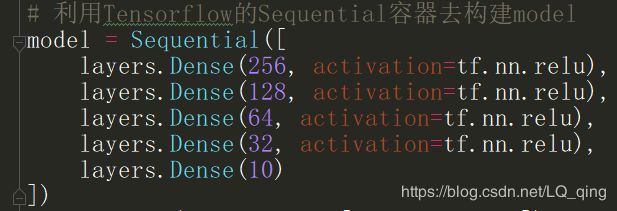
其后面填入的是一个list集合,集合里都是继承了keras.layer.Layer的对象,其中Layer对象用于定义每一层的参数数量和激活函数。上述代码代表的是,利用Sequential构建五层的全连接网路。
什么是keras.metries?
在训练中,我们通常都会计算loss值和准确率,为了使得loss值和准确率更加具有代表性,我们通常在所有训练集在迭代完一次后统计以下loss值和准确率,而在计算时,其方法和步骤是固定的,所以,Tensorflow提供了metries这个接口,我们只需要在对应位置调用该接口 就能轻松实现对loss值和准确率的计算。
什么是keras.complie?
在写训练相关代码时,我们通常的步骤如下:
步骤一:把训练集划分成不同批次进行训练
步骤二:计算梯度和loss值
步骤三:反向梯度更新
步骤四:投入测试数据进行测试
由于这四步是固定化的,没有什么技术含量,所以Tensorflow使用了complie对这些固定的结构进行封装,因此,我们只需要简单的几行代码就可以轻松实现上述四步。

上面的代码分别设置了优化函数(Adam)和学习率(lr = 0.01),损失函数(CategoricalCrossentropy),以及正确率
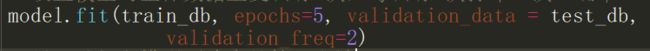
上面的代码设置了投喂的训练数据,整个训练数据需要重复训练的次数,测试数据以及每隔多少训练次数就进行一次测试。
例如,使用train_db用作训练数据,该训练数据需要重复训练5次,每隔2次输出一次测试结果,test_db为测试数据.
实战部分
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics
import matplotlib.pyplot as plt
import io
import datetime
(x, y), (test_x, test_y) = datasets.cifar10.load_data()
# 数据预处理
def progress (x ,y):
x = 2 * tf.cast(x, dtype=tf.float32) / 255. - 1.
x = tf.reshape(x, [-1, 32*32*3])
y = tf.one_hot(y, depth=10, dtype=tf.int32)
return x, y
# 构建dataset对象 方便对数据的管理
db_train = tf.data.Dataset.from_tensor_slices((x,y)).shuffle(1000)
db_test = tf.data.Dataset.from_tensor_slices((test_x,test_y))
# deal with data
train_db = db_train.map(progress).batch(128)
test_db = db_test.map(progress).batch(128)
train_iter = iter(train_db)
train_next = next(train_iter)
print(train_next[0].shape)
# 利用Tensorflow的Sequential容器去构建model
model = Sequential([
layers.Dense(256, activation=tf.nn.relu),
layers.Dense(128, activation=tf.nn.relu),
layers.Dense(64, activation=tf.nn.relu),
layers.Dense(32, activation=tf.nn.relu),
layers.Dense(10)
])
model.build(input_shape=[None, 32*32*3])
model.summary()
# 利用Sequential的compile方法,简化损失函数,梯度优化,计算准确率等操作
model.compile(optimizer=optimizers.Adam(lr = 0.01),
loss = tf.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
# 设置模型对整体数据重复训练5次,每训练2次打印一次正确率
model.fit(train_db, epochs=5, validation_data = test_db,
validation_freq=2)
# 另一种打印模型正确率的接口方法
model.evaluate(test_db)
训练结果
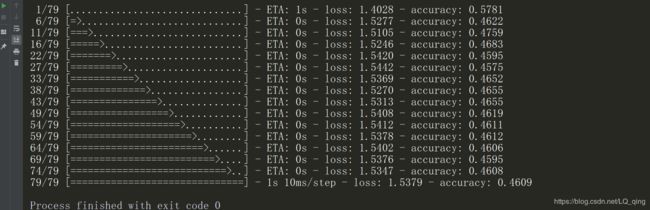
我们可以看到,利用五层全连接实现对cifar10的训练,准确率只有0.46,并不算太高,这也从侧面反映了全连接网络对于处理复杂数据集的不足,下一篇,少奶奶将介绍利用keras的自定义网络功能实现对cifar10的全连接训练(理论+实战),欢迎大家浏览查看
开篇:开启Tensorflow 2.0时代
第一章:Tensorflow 2.0 实现简单的线性回归模型(理论+实践)
第二章:Tensorflow 2.0 手写全连接MNIST数据集(理论+实战)
第三章:Tensorflow 2.0 利用高级接口实现对cifar10 数据集的全连接(理论+实战实现)
第四章:Tensorflow 2.0 实现自定义层和自定义模型的编写并实现cifar10 的全连接网络(理论+实战)
第五章:Tensorflow 2.0 利用十三层卷积神经网络实现cifar 100训练(理论+实战)
第六章:优化神经网络的技巧(理论)
第七章:Tensorflow2.0 RNN循环神经网络实现IMDB数据集训练(理论+实践)
第八章:Tensorflow2.0 传统RNN缺陷和LSTM网络原理(理论+实战)