机器学习之奇异值分解之Lanczos方法
开篇之前,我想和大家分享一个经验,一段时间以前笔者曾经进行了关于用户协同过滤推荐算法的hadoop分布式实现,由于算法间用户数量大,每个用户都需要与其他用户进行比较,或者判断不比较,导致了很严重的算法时间复杂度问题。于是笔者去优化算法,采用了两次反变换存储数据形式(自己定义的,就是一种数据的存储形式),争取做到了每一步都是有效运算(避免了查询操作),但是最后程序仍旧出现耗时长的问题。笔者和笔者的组长进行讨论,组长给我提了一个好的建议,你可以去追踪程序,看看时间究竟耗在了什么地方。后来笔者去查询相关资料,顿悟,程序的主要耗时在于文件从HDFS上的读写上。相对于hadoop的map-reduce框架而言,文件的读写似乎是无法避免的硬伤,但是针对某些特定的算法,比如上面的用户协同问题,是否可以让一些数据保存在内存中呢?笔者最后采用的就是这种方式。
于是,笔者得出结论:对于只考虑数据保存在内存中的操作,开根号的时间复杂度应当优先于四则运算的时间复杂度进行考虑,能优则优。而对于数据无法常驻内存中的操作,文件的读写很多情况下是时间复杂度的主要考虑因素,开根号的操作则往往不需要花太多时间考虑了。而这也就是单机和分布式的不同,分布式化我们不仅得考虑分布式上每台机器上的最优,也得考虑分布式环境下不得不考虑的诸多因素。所以,想写出一个好的分布式程序,是这两种因素的综合考虑。
好了,也该进入今天的主题,Lanczos方法了,Lanczos方法是20世界10大算法之一的Krylov子空间迭代算法的一种形式,其变形是目前求解大规模稀疏矩阵特征值问题最常用的方法之一。其实上篇文章讲的QR算法也是20世纪的10大算法之一,是矩阵运算另一种实用的方法。这两种方法的结合其实感觉蛮不错的,Lanczos将对称矩阵三对角化,QR算法对三对角矩阵求解特征值,上篇文章已经说明,QR算法对于三对角矩阵时间复杂度的优势。
Lanczos方法是一种将对称矩阵通过正交相似变换转化为三对角矩阵的算法。它的起源来自Lanczos对求解特征多项式的研究,其天才的发现著名的三项递归式(具体的来龙去脉请参考Louis Komzsik著作的《Lanczos方法 演变与运用》 这是一本对Lanczos方法演变与运用的相关书籍,对于学习Lanczos是不错的选择):
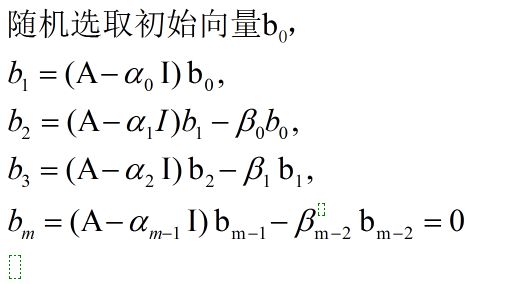
Lanczos方法的证明必然要和瑞利-里茨方法结合起来一起考虑,其实它们都是一种逼近思想来近似特征值和特征向量,这最佳的近似就是Ritz value和Ritz vector。(笔者能力较低,无法阐述其证明过程,有兴趣的同学可以查阅相关资料和书籍,《运用数值线性代数》一书应该有提到。)
好了,接着进入正题,首先根据上述的三项递归式,我们可以得到最初的Lanczos算法:

以上就是Lanczos算法的基本形式,再补充一下吧,Lanczos是将矩阵化为三对角矩阵的方法,其可以针对对称矩阵,也可以针对非对称矩阵,这里我们只考虑对称矩阵。而算法迭代过程中产生了相应的Lanczos向量![]() ,将会构成一个向量组,对求解原矩阵特征向量做出贡献,而
,将会构成一个向量组,对求解原矩阵特征向量做出贡献,而![]() 则是构成三对角矩阵T的元素。当将矩阵迭代成三对角矩阵之后,将会有许多高效的算法对其求解特征值和特征向量。
则是构成三对角矩阵T的元素。当将矩阵迭代成三对角矩阵之后,将会有许多高效的算法对其求解特征值和特征向量。
毕竟本篇主要了解一下Lanczos方法,不好展开其他内容,那么我们继续Lanczos方法,说说其所带来的精度问题及优化(只包括笔者写Lanczos方法遇到的问题,更为具体的各种优化考虑不进行讨论)。
Lanczos方法在最初并没有受到业界的重视,计算出的结果不是太好,而后数学家们在Lanczos上的研究发现导致Lanczos方法不适合运用于工程中的原因是计算机的有限精度问题,最终导致Lanczos向量很快失去正交性,而后一系列的改进提出,最终Lanczos方法成为解决大规模稀疏矩阵特征值问题的有效方法,并且成为20世纪最伟大的10大算法之一的一种形式。
假设存在向量v1,v2,v3,v4,v5……,如果其中v1正交于v2,v3正交于v1并且正交于v2,v4正交于v3并且正交于v2,以此递归,通过数学归纳法可以证明v5分别正交于v1,v2,v3,v4(证明略)。
但是实际情况呢?笔者做过实验,计算机中的数据采用double(双精度保存),产生40*40维的矩阵,矩阵中元素为一个40*40维矩阵及其转置矩阵的乘积,这个转置矩阵中元素范围为-5000到5000.
而后采用Lanczos方法迭代,迭代次数在5-7次之后便失去了正交性,失去正交性如此之快,最终导致求得相同的最大特征值,而且呈线性关系,比如第一次失去正交,多迭代出最大特征值,第二次失去正交,又多迭代出最大特征值,并且附带第二大特征值多迭代出。如此类推,最终求得的特征值基本无法用于SVD的降维。
那么,导致其失去正交性的原因是什么了?很明显计算机的精度问题,double的64位存储,在矩阵元素较大的情况下,无法保存更多有用的位数,导致正交性失去,其实即使是128位失去正交性也是早晚的事。
那么我们该如何解决失去正交性了,方法很多,比如完全正交法,选择正交法,及部分正交法。
完全正交法即采用了上篇文章中描述的Gram-Schmidt正交化方法,这个方法的核心便是:
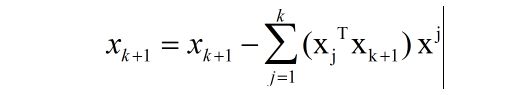
于是,完全正交化的方法便出来了:

其中正交化的公式便为:
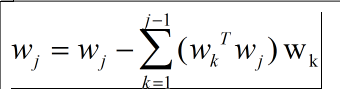
有人可能会觉得完全正交化岂不是太费时间啦,运算量太大,而且很有可能受限于矩阵规模。
其实,目前大多数人采用了选择正交化方法,对于选择正交化方法,这是根据前辈的得出来的数学经验和定理,来减少正交化的次数。
选择正交化的算法描述就不提供了,有兴趣的同学可以参考《运用数值线性代数》第323页,或者直接查看Parlett B N,Scott D S.发表的论文《The Lanczos algorithm with selective reorthogonalization》
不过笔者研究选择化正交方法,虽说很大程度上减少了正交化的次数,据说大约只占完全正交化工作的13%。但是笔者疑问重重,那就是如果一个矩阵那么不幸,每一步都失去正交(虽然这种情况不可能出现,我只是表述那类很容易失去正交性的矩阵特例),那么选择化正交的优势何在?其二便是,选择化正交依赖于求得的特征向量的第k个分量,是否意味着每一步迭代都得求得其特征值,这种方式带来的运算量是否会达到完全正交的运算?毕竟,完全正交可以等三对角矩阵全部求解出来之后,在进行矩阵特征值求解。
还是说我理解错了?每一步迭代过程产生的特征值和特征向量和下一步产生的特征值和特征向量有直接的联系,这样可以简化下一步求解特征值的时间复杂度。笔者对于这部分内容不是非常清楚,希望大家共同研究,给我一些建议,这样就可以优化我写的SVD,目前本人所做SVD采用的是完全正交化方法,将正交化的运算分布到各台机器,这样利用多台机器的优势简化时间的复杂度。
部分(半)正交化方法也是一种可行的策略,具体笔者没有时间研究,这里给出一篇文章,Simon H.《The Lanczos algorithm with partial reorthogonalization》,至于中文的,笔者未能找到参考资料。
另外关于Lanczos方法更多的细节,例如初始向量的选择加速迭代,分块正交,重启动等问题,如果有兴趣不妨多搜索一下资料看看,相信这样受益颇多。
笔者做的SVD虽然效果不是太理想,但是笔者所查阅之资料,论文至少超过30余篇,书籍主要两本《运用数值线性代数》及《Lanczos方法 演变与运用》,还有各种网上可以搜索得到的PPT。故一篇文章确实不能说明清楚,而且限于作者水平,很多问题不是太理解。
限于笔者水平,上述内容难免出错,还望大家多多指正。