VSLAM综述
传统SLAM算法及相关成果的介绍
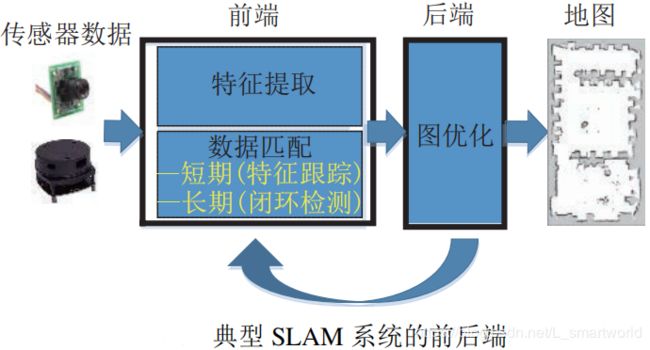
根据传感器的分类可将VSLAM大致分为单目SLAM、双目SLAM(立体)和RGB-D SLAM。有根据对图像信息不同的处理方式可分为直接法SLAM和基于特征SLAM。直接法主要有直接法和光流法,该类算法近几年才被提出,在场景特征点少的情况下,有较强的鲁棒性,适用于稠密建图。基于特征SLAM主要是对图像进行特征提取,主要的特征提取算法有SIFT特征提取(用在三维重构中)、SURF特征提取、ORB特征提取和关键帧(PTAM为代表)。
SLAM标志性成果:
第一个基于EKF的单目SLAM:MonoSLAM
基于直接法的单目SLAM:DTAM
第一个多线程处理的SLAM(第一个基于Kinect):PTAM
基于关键帧的SLAM:ORB_SLAM
SLAM知名研究实验室:
(1)苏黎世联邦理工学院的Autonomous System lab 主要负责:视觉定位和深度重建算法
(2)明尼苏达大学的Multiple Autonomous Robotic System Laboratory,主要研究四轴飞行器导航,合作建图,基于地图的定位,半稠密地图创建
(3)慕尼黑理工大学的The Computer Vision Group 主要研究三维重构、机器人视觉、VSLAM
VSLAM的 关键性问题
(1)特征检测和匹配
上面简单介绍过一些特征匹配的算法,每种算法各有优缺点。SIFT算法具有旋转不变性、尺度不变性、放射变换不变性,对噪声和光照变化有一定的鲁棒性,缺点是所描述的向量维数(128)过高,导致算法复杂,时间复杂度高。SURF算法具有尺度不变性、旋转不变性,相比于前者,速度有较大的提高(3~7倍)。ORB算法是运算速度最快的,具有旋转不变性,但是不具备尺度不变性。
(2)关键帧
关键帧也是近几年提出,所解决的问题就是帧与帧之间的对准会产生较大的累计误差,较为典型的关键帧方法为有较好的地图信息的选为关键帧;基于熵的关键帧;当两帧图像共同看到的特征点少于一定阈值时,创建关键帧。
VSLAM发展的热点与趋势
(1)多传感融合
多传感器的融合为现今重要发展方向,单纯的摄像头没有较强的鲁棒性,在剧烈运动下极易丢失图像信息,造成定位失败与地图构建失败。VSLAM中典型的多传感融合为IMU+camera,从传统的滤波器融合到非线性优化(BA)融合到先预积分再融合的发展历程,鲁棒性也有较大的增强。但依旧存在很多问题,在剧烈运动下,还是存在信息丢失情况,并没有完全解决;给IMU建立模型之后精度有所提升,但是也增加了时间复杂度和对算力的要求。尝试将不同的传感器融入SLAM。
(2)VSLAM与深度学习结合
VSLAM与深度学习结合主要在以下四方面:1.前端视觉里程计;2.回环检测;3.语义SLAM;4.多传感融合。前端视觉里程计(visual odometry)存在图像特征提取,用CNN将其代替;用深度学习方法代替传统回环算法可提高识别率;在SLAM建成的3D稠密地图中,利用深度学习将里面的物体识别并标注,使其成为具有语义信息的地图;用于多传感融合,使用相应的神将网络将不同传感器产生的位姿进行融合(fusion)。
基于深度学习的VSLAM
下面将着重介绍深度学习在VSLAM中的应用及一些进展。
(1)深度学习与视觉里程计
1)Konda 和 Memisevic 提出基于端到端的深度神经网络架构用于预测摄像机速度和方向的改变.主要分为 2 个步骤:首先是图像序列深度和运动信息的提取.利用乘性交互(multiplicative interaction)神经网络进行时序立体图像的同步检测(synchrony detection),将立体图像序列之间的空间变换估计转换为同步检测,该网络也被称为无监督同步/深度自动编码(synchrony/depth autoencoder,SAE-D).其次是图像序列速度和方向改变估计.将上一层 SAE-D 提取的运动和 深度信息作为卷积神经网络层(CNN)输入,用以 学习图像速度和方向改变,从而执行帧间估计.(简单的说第一步利用深度自动编码网络进行深度估计和运动提取,第二步将深度信息和运动信息传入CNN进行速度和方向估计)。
2)Costante 等提出利用卷积神经网络学习图像数据的最优特征表示进行视觉里程计估计(在光照强,图像模糊的情况下有一定的鲁棒性)。该方法先用 Brox 算法提取连续 2 帧的稠密光流特征,以此作为 CNN 网络的输入。主要设计三种CNN网络,CNN-1b(基于全局特征),CNN-4b(基于局部特征),P-CNN(将前两者融合)。
3)Handa等设计了一种神经网络来适配visual odometry。该系统的网络构架由 VGG-16 网络 启发构建的 Siamse 网络层、位姿变换估计层(SE3 layer)、3 维网格生成层(3D grid generator)、投影层(projection layer)和双线性插值层(bilinear interpolation)组成.其中,Siamse 网络的输入为 2 个连续的帧图像,输出是对摄像机 6 自由度的帧间位姿估计向量.基于此帧间估计,结合深度信息,将上一帧图像投射到当前位姿,并经过双线性插值生成预测图像.为构造损失函数进行学习,预测图像不是与当前图像进行像素级对比,而是与上一帧图像利用真实的帧间估计进行投影和双线性差值后的图像对比,从而避免了传统神经网络结构在学习过程中单方面的像素丢失和各种运动模糊、强度变化或图像噪声对匹配的影响.并且这种方法确保在收敛时,损失函数尽可能接近 0,能够恰当地处理丢失像素.
(2)深度学习结合回环检测
Gao 等通过自动编码器提取图像特征来进行图像匹配.首先利用传统 SIFT、FAST 或 ORB 等算法提取图像特征位置,并围绕特征位置裁剪图像为不同区域子图像块.自动编码器以向量化后的区域子图像块为输入、以训练后的隐含层输出图像特征.最后构建相似性矩阵,判断是否发生闭环.在自动编码机训练部分,针对损失函数进行了改进.
与传统闭环检测(位置识别)算法相比,基于深度学习的方法利用深度神经网络提取图像特征,表达图像信息更充分,对光照、季节等环境变化有 更强鲁棒性。但是用什么层表示图像特征,如何设计整个神经网络架构及如何训练等诸多问题存在。
(3)深度学习与语义SLAM
语义 SLAM 的优势:1.传统SLAM地图都是在静态场景中对物体的识别,而语义SLAM存在可移动属性;2.语义SLAM中相似物体可以进行分享;3.可以帮助实现智能化路径规划。
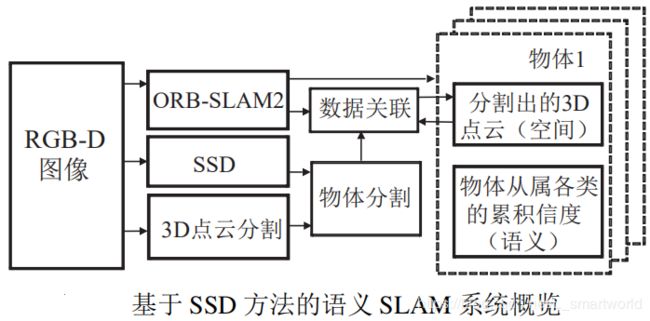
1)Sunderhauf 等提出面向物体对象的语义建 图方法(如下图所示):首先利用 ORB-SLAM2 算法估计 RGB-D 摄像头位姿和构建环境的稀疏特征地图,并将深度图像对应的点云依据摄像头当前位姿投射到全局坐标,从而得到环境的 3D 点云地图.其次是物体检测与识别,采用 Liu 等提出的SSD,对关键帧图像生成固定数量的物体建议边界框,并计算每个建议边界框的置信值.然后是基于超体元的 3 维目标物体点云分割,以进一步分割出前述基于图像划分得到的物体所对应点云.最后是基于最近邻方法的物体数据关联,以确定当前 物体和地图中物体之间的对应性,进而添加或更新 地图中目标物体的点云信息和从属类别置信值等数 据.因此,利用 CNN 网络中的 SSD 方法,该语义 地图最终包含有:(1) 关键帧的点云数据;(2) 地图 中各物体的 3D 点云分割及其所对应关键帧关系; (3) 语义信息.
2)McCormac 等提出基于卷积神经网络的稠密3维语义地图构建方法 SemanticFusion,其依赖 Elastic Fusion SLAM 算法提供室内 RGB-D 视频帧间位姿估计,利用卷积神经网络预测像素级的物体类别标签,最后结合贝叶斯升级策略和条件随机场模型实现不同视角下CNN 预测值的概率升级,最终生成包含语义信息的稠密 3 维语义地图. SemanticFusion 中的CNN 在caffe 框架下,选择在 Noh 等提出的基于VGG-16网络的反卷积语义分割网络结构基础上加入深度通道,从而能够在输入四通道 RGB-D 图像后,输出稠密像素级语义概率图。
3)Li 等提出了基于 CNN 和 LSD-SLAM(large scale direct SLAM)的单目半稠密 3 维语义建图构 建方法,其过程与 McCormac 所提方法类似,但利用 LSD-SLAM 代替 Elastic Fusion 方法估计摄像机位姿,利用单目相机而非 RGB-D 深度相机和立体 相机.其过程分为3部分:首先选取关键帧估计摄像机位姿,提高处理速度;其次利用 DeepLab-v2 中的 CNN 架构进行像素级分类,包含亚卷积和亚 空间金字塔池化(ASPP)两个核心组件,以扩大滤 波范围,融合多尺度特征信息;最后利用贝叶斯升 级像素分类概率预测,结合条件随机场(CRF)进 行地图正则化,对生成的语义分割地图进行噪声平滑。