抓取国家统计局区划、城乡划分代码的简易python爬虫实现
抓取国家统计局区划、城乡划分代码的简易python爬虫实现
免责声明
本篇文章仅用于学习交流,并不针对任何网站、软件、个人。
概要说明
本篇文章介绍一个简易python爬虫的开发,对国家统计局区划、城乡规划代码进行抓取。
所谓简易,一方面是因为是单线程爬虫,不涉及python的多进程、多线程编程,另一方面是因为不包括“URL管理器”的模块(负责存储已爬取、未爬取的url序列,控制爬虫不多爬、不漏爬),而是用了循环体的结构,依次爬取省、市、区、街道的页面。
爬虫主要分为4个模块:
1. 主控制器(spider_main.py),负责对其他模块进行调用,控制整个爬取过程
2. 下载器(html_downloader.py),负责请求指定的url,将响应结果返回主控制器
3. 解析器(html_parser.py),负责调用beautifulsoup4对请求到的html代码进行解析,拼装需要的数据集合
4. 数据库控制器(mysql_handler.py),负责执行数据库操作
前置条件
- python3.5.2
- mysql
- beautifulsoup4
- pymysql
主控制器(spider_main.py)
# !/usr/bin/env python3
# -*- coding: utf-8 -*-
from mysql_handler import MysqlHandler
from html_downloader import HtmlDownloader
from html_parser import HtmlParser
import traceback
class CodeSpider(object):
def __init__(self):
# 实例化其他模块类
self.mysql_handler = MysqlHandler()
self.html_downloader = HtmlDownloader()
self.html_parser = HtmlParser()
# 爬取起点url
self.root_url = 'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2016/index.html'
# 用于后续url的拼接
self.split_url = 'http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2016/'
# 省页面列表
self.province_url_list = []
# 市页面列表
self.city_url_list = []
# 区页面列表
self.county_url_list = []
# 乡镇、街道页面列表
self.town_url_list = []
def craw(self):
try:
# 记录正在下载、解析的url,便于分析错误
downloading_url = self.root_url
html_content = self.html_downloader.download(downloading_url)
# 第一个参数:需要解析的html代码
# 第二个参数:用于url拼接的url
self.province_url_list = self.html_parser.province_parser(html_content, self.split_url)
for province_name, province_url, province_code in self.province_url_list:
# 第一个参数:1-插入一个省数据;2-市数据;3-区数据;4-乡镇街道数据
# 第二个参数:省市区街道名称
# 第三个参数:上级的id,注意省没有上级id
# 第四个参数:市区街道的行政区划编码
province_id = self.mysql_handler.insert(1, province_name, None, None)
# 记录正在下载、解析的url,便于分析错误
downloading_url = province_url
html_content = self.html_downloader.download(downloading_url)
self.city_url_list = self.html_parser.city_parser(html_content, self.split_url)
for city_name, city_url, city_code in self.city_url_list:
city_id = self.mysql_handler.insert(2, city_name, province_id, city_code)
# 例如直辖市没有下级页面
if city_url is None:
continue
# 记录正在下载、解析的url,便于分析错误
downloading_url = city_url
html_content = self.html_downloader.download(downloading_url)
self.county_url_list = self.html_parser.county_parser(html_content, self.split_url + province_code + "/")
for county_name, county_url, county_code in self.county_url_list:
county_id = self.mysql_handler.insert(3, county_name, city_id, county_code)
if county_url is None:
continue
# 记录正在下载、解析的url,便于分析错误
downloading_url = county_url
html_content = self.html_downloader.download(downloading_url)
self.town_url_list = self.html_parser.town_parser(html_content, self.split_url)
for town_name, town_url, town_code in self.town_url_list:
# 输出抓取到的乡镇街道的名称、链接(实际不需要)、编号代码
print(town_name, town_url, town_code)
self.mysql_handler.insert(4, town_name, county_id, town_code)
self.mysql_handler.close()
except Exception as e:
print('[ERROR] Craw Field!Url:', downloading_url, 'Info:', e)
# 利用traceback定位异常
traceback.print_exc()
if __name__ == '__main__':
obj_spider = CodeSpider()
obj_spider.craw()
下载器(html_downloader.py)
# !/usr/bin/env python3
# -*- coding: utf-8 -*-
import urllib.request
import urllib.error
import time
class HtmlDownloader(object):
def download(self, url):
if url is None:
raise Exception('url is None')
# 输出当前进行下载的url
print(url)
# 伪装浏览器
request = urllib.request.Request(url, None, {'Cookie': 'AD_RS_COOKIE=20083363',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWeb\Kit/537.36 (KHTML, like Gecko)\
Chrome/58.0.3029.110 Safari/537.36'})
try:
with urllib.request.urlopen(request) as response:
print(response.getcode())
if response.getcode() != 200:
# 线程暂停5秒
time.sleep(5)
# 递归调用
return self.download(url)
else:
return response.read()
except urllib.error.HTTPError as e:
print(e)
time.sleep(5)
return self.download(url)
为什么要用递归?
我一开始也没使用递归方法来下载url,在爬虫运行的过程中发现经常碰到状态码502的情况,猜想可能服务器对爬虫有限制,频繁抓取就会出现502(吐槽:这还只是个单线程爬虫呀!)。第一时间的想法是用time.sleep()让线程休息几秒再抓取,于是在抓取每个市级页面的间隙中加入time.sleep(5),运行发现情况有好转但仍会出现502。
既然如此,换一个思路,就是重复抓取502的链接,直到成功,实现的办法有以下两个途径:
1. 如果爬虫包含URL管理器的模块,就把502的链接重新加到待爬取的队列,再以后的某个时间去爬取
2. 遇到502的链接,就暂停5秒后,继续请求,直到成功。
因为本爬虫不含有URL管理器模块,直接考虑第二种方法,于是采用递归的方法来反复请求502的链接,直到成功。递归部分如下:
if response.getcode() != 200:
# 线程暂停5秒
time.sleep(5)
# 递归调用
return self.download(url)
else:
return response.read()运行发现一遇到502,程序还是停下来了,原来在urllib.request.urlopen(request)的时候,遇到502就会抛出异常,那就用try···except···去捕获异常,捕获到异常的时候进行递归调用:
except urllib.error.HTTPError as e:
print(e)
time.sleep(5)
return self.download(url)解析器(html_parser.py)
# !/usr/bin/env python3
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import re
class HtmlParser(object):
# 第一个参数:需要解析的html代码
# 第二个参数:用于拼装下级页面的url
def province_parser(self, html_content, url):
if html_content is None:
raise Exception('Html is None')
# 将html代码从gb2312转码到utf-8
html_content = html_content.decode('gb2312', 'ignore').encode('utf-8')
soup = BeautifulSoup(html_content, 'html.parser', from_encoding='utf-8')
# 找出“北京市”、“天津市”等标签
url_tds = soup.find_all('a', href=re.compile(r'\d+.html'))
# 生成包含省名称、下级url、省编码(在后续拼装区级页面需要用到)的元组的列表
urls = [(td.get_text(), url + td['href'], td['href'].replace('.html', '')) for td in url_tds]
return urls
def city_parser(self, html_content, url):
if html_content is None:
raise Exception('Html is None')
html_content = html_content.decode('gb2312', 'ignore').encode('utf-8')
soup = BeautifulSoup(html_content, 'html.parser', from_encoding='utf-8')
# 找出“杭州市”、“温州市”等标签
url_trs = soup.find_all('tr', 'citytr')
# 生成包含市名称、下级url、市级12位编码的元组的列表
urls = [(tr.contents[1].get_text() if tr.contents[1].a is None else tr.contents[1].a.get_text(),
None if tr.contents[0].a is None else url + tr.contents[0].a['href'],
tr.contents[0].get_text() if tr.contents[0].a is None else tr.contents[0].a.get_text())
for tr in url_trs]
return urls
def county_parser(self, html_content, url):
if html_content is None:
raise Exception('Html is None')
html_content = html_content.decode('gb2312', 'ignore').encode('utf-8')
soup = BeautifulSoup(html_content, 'html.parser', from_encoding='utf-8')
# 找出“上城区”、“下城区”等标签
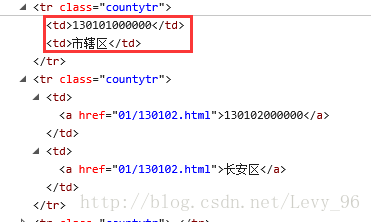
url_trs = soup.find_all('tr', 'countytr')
# 生成包含区名称、下级url、区级12位编码的元组的列表
urls = [(tr.contents[1].get_text() if tr.contents[1].a is None else tr.contents[1].a.get_text(),
None if tr.contents[0].a is None else url + tr.contents[0].a['href'],
tr.contents[0].get_text() if tr.contents[0].a is None else tr.contents[0].a.get_text())
for tr in url_trs]
return urls
def town_parser(self, html_content, url):
if html_content is None:
raise Exception('Html is None')
html_content = html_content.decode('gb2312', 'ignore').encode('utf-8')
soup = BeautifulSoup(html_content, 'html.parser', from_encoding='utf-8')
# 找出“西湖街道”、“留下街道”等标签
url_trs = soup.find_all('tr', 'towntr')
# 生成包含乡镇街道名称、下级url、乡镇街道级12位编码的元组的列表
urls = [(tr.contents[1].get_text() if tr.contents[1].a is None else tr.contents[1].a.get_text(),
None if tr.contents[0].a is None else url + tr.contents[0].a['href'],
tr.contents[0].get_text() if tr.contents[0].a is None else tr.contents[0].a.get_text())
for tr in url_trs]
return urls
为什么要转码?
html_content = html_content.decode('gb2312', 'ignore').encode('utf-8')
因为爬取的网站提供的编码为gb2312,不进行转码的话会出现乱码的情况。
注意decode()方法中需要填入第二个参数'ignore',因为在转码过程中会遇到非法字符,例如:全角空格往往有多种不同的实现方式,比如\xa3\xa0,或者\xa4\x57,
这些字符,看起来都是全角空格,但它们并不是“合法”的全角空格
真正的全角空格是\xa1\xa1,因此在转码的过程中出现了异常。 加上第二个参数'ignore'就能确保转码过程中遇到非法字符不会抛出异常使程序停止运行。
关于上述代码中的列表生成式的详解
例子:
urls = [(tr.contents[1].get_text() if tr.contents[1].a is None else tr.contents[1].a.get_text(),
None if tr.contents[0].a is None else url + tr.contents[0].a['href'],
tr.contents[0].get_text() if tr.contents[0].a is None else tr.contents[0].a.get_text())
for tr in url_trs]
列表生成式后半部分的for tr in url_trs表示遍历beautifulsoup获取到的集合,前半部分表示从tr元素中取出需要的数据,组合成一个元组。最后就产生了一个由元组组成的列表。
A if 条件 else B,这是python特有的三目运算的表达方式,意为“当条件成立时取A,否则取B”,本爬虫中的条件为tr.contents[1].a is None,是因为例如”直辖市”没有下级页面,中不包含tr.contents[1].a.get_text()去获取数据就会报错。
注意上下两个结构的区别:
数据库控制器(mysql_handler.py)
# !/usr/bin/env python3
# -*- coding: utf-8 -*-
import pymysql.cursors
class MysqlHandler(object):
def __init__(self):
self.db = pymysql.connect(host="localhost", user="root", passwd="", db="code_spider", charset="utf8", cursorclass=pymysql.cursors.DictCursor)
# 第一个参数:1-插入一个省数据;2-市数据;3-区数据;4-乡镇街道数据
# 第二个参数:省市区街道名称
# 第三个参数:上级的id,注意省没有上级id
# 第四个参数:市区街道的12位行政区划编码
def insert(self, level, name, pre_id, code):
try:
with self.db.cursor() as cursor:
if level == 1:
cursor.execute('INSERT INTO province (province_name) VALUES (%s)', [name])
elif level == 2:
cursor.execute('INSERT INTO city (city_name, province_id, city_code) VALUES (%s, %s, %s)'
, [name, pre_id, code])
elif level == 3:
cursor.execute('INSERT INTO county (county_name, city_id, county_code) VALUES (%s, %s, %s)'
'', [name, pre_id, code])
else:
cursor.execute('INSERT INTO town (town_name, county_id, town_code) VALUES (%s, %s, %s)'
, [name, pre_id, code])
insert_id = cursor.lastrowid
self.db.commit()
except Exception as e:
raise Exception('MySQL ERROR:', e)
# 返回存储后的id
return insert_id
#最后需要调用该方法来关闭连接
def close(self):
self.db.close()
项目源码与爬取结果sql文件
链接戳这里