简单百科爬虫 python
本爬虫的目的是截取某百科下的所有相关链接的标题和简介,最终以html表格的形式呈现
爬虫整体架构
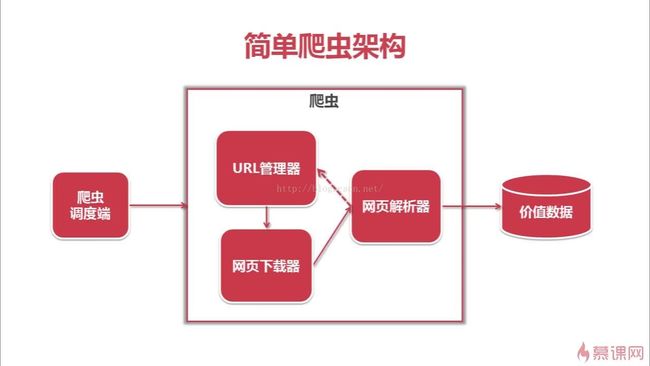
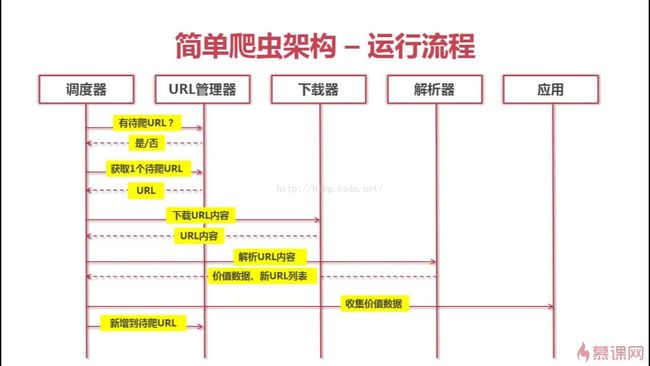
爬虫整体流程
结果展示:

代码部分
调度端- baike_spider:
# coding:utf-8
from baike_spider import url_manager, html_downloader, html_parser, html_outputer
class SpiderMain(object):
def __init__(self) :
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser()
self.outputer = html_outputer.HtmlOutputer()
def craw(self,root_url,num):
count = 1
self.urls.add_new_url(root_url) # url管理器加入根链接
while(self.urls.has_new_url()): # 当管理器中存在链接
try:
new_url = self.urls.get_new_url() #url管理器 取出一个url
print 'craw %d : %s ' % (count, new_url)
html_content = self.downloader.download(new_url) # 下载器通过url下载一个网页文档
new_urls, new_data = self.parser.parse(new_url, html_content) # 解析器通过文档解析出新文档与需要的数据
self.urls.add_new_urls(new_urls)
self.outputer.collect_data(new_data) # 输出器收集数据
except:
print 'craw failed' #当前页面爬取失败
count = count + 1
if count > num :
break
self.outputer.output_html()
if __name__=="__main__":
root_url="http://baike.baidu.com/link?url=DwQd6j2iC_BOdWhM645mbHcxgKFerheCISzWHbHZfyuzDiq2kfdlFHkRKjGzp9N2YznXdIw6TMCprdA-BhuaFq"
num=100
obj_spider=SpiderMain()
obj_spider.craw(root_url,num)url管理器- url_manager:
#coding:utf-8
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def add_new_url(self,url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self,urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
def has_new_url(self):
return len(self.new_urls) != 0
def get_new_url(self):
new_url=self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
#coding:utf-8
import urllib2
class HtmlDownloader(object): #html下载器
def download(self,url):
if url is None:
return None
response = urllib2.urlopen(url)
if response.getcode() != 200:
return None
return response.read()
文档解析器- html_parser:
#coding:utf-8
from bs4 import BeautifulSoup # html解析器模块
import re
import urlparse
class HtmlParser(object):
def get_new_urls(self, url, soup):
# Unix shell
new_urls = set()
links = soup.find_all('a' , href = re.compile(r'/view/\d+.htm')) #匹配相对url
for link in links:
new_url = link['href']
new_full_url = urlparse.urljoin(url,new_url) #通过本url格式补全相对url
new_urls.add(new_full_url)
return new_urls
def get_new_datas(self, url, soup):
new_dict = {}
new_dict['url'] = url
# Python
title_node = soup.find('dd',class_='lemmaWgt-lemmaTitle-title').find('h1') #找到标题节点
new_dict['title'] = title_node.get_text()
#
summary_node = soup.find('div', class_='lemma-summary') #找到简洁节点
new_dict['summary'] = summary_node.get_text()
return new_dict
def parse(self, url ,content):
if url is None or content is None:
return
soup = BeautifulSoup(content,'html.parser',from_encoding='utf-8') #通过html文件 解析该页面
new_urls = self.get_new_urls(url,soup)
new_datas = self.get_new_datas(url,soup)
return new_urls,new_datas
数据输出器- html_outputer:
#coding:utf-8
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self, data):
if data is None:
return
self.datas.append(data)
def output_html(self):
fout=open('result.htm','w')
fout.write("")
fout.write("")
fout.write('')
fout.write("Crawl Result ")
fout.write("")
fout.write("")
fout.write('Crawl Result
')
fout.write('')
for data in self.datas:
fout.write("")
# fout.write("" % data["url"])
# fout.write("%s " % data["title"].encode("utf-8"))
fout.write("%s " % (data["url"].encode("utf-8"),data["title"].encode("utf-8")))
fout.write("%s " % data["summary"].encode("utf-8"))
fout.write(" ")
fout.write("
")
fout.write('
Power By Effort john
')
fout.write("")
fout.write("")