Java并发编程高阶技术、高性能并发框架Disruptor
1.简介
Martin Fowler在自己网站上写了一篇LMAX架构的文章,在文章中他介绍了LMAX是一种新型零售金融交易平台,它能够以很低的延迟产生大量交易。这个系统是建立在JVM平台上,其核心是一个业务逻辑处理器,它能够在一个线程里每秒处理6百万订单。业务逻辑处理器完全是运行在内存中,使用事件源驱动方式。业务逻辑处理器的核心是Disruptor。Disruptor它是一个开源的并发框架,并获得2011 Duke’s 程序框架创新奖,能够在无锁的情况下实现网络的Queue并发操作。Disruptor是一个高性能的异步处理框架,或者可以认为是最快的消息框架(轻量的JMS),也可以认为是一个观察者模式的实现,或者事件监听模式的实现。
开源:https://github.com/LMAX-Exchange/disruptor
2.使用
- 目前我们使用disruptor已经更新到了3.x版本,比之前的2.x版本性能更加的优秀,提供更多的API使用方式,直接下载jar包,addTopath就可以使用了。
- 也可以以maven的方式来引入
com.lmax
disruptor
3.4.2
- 示例
下面以一个例子来使用disruptor框架:
先了解一下步骤:
1. 建立一个Event类,用于创建Event类实例对象
import java.text.SimpleDateFormat;
public class OrderEvent {
private long value; //订单的价格
public long getValue() {
return value;
}
public void setValue(long value) {
this.value = value;
}
}
- 需要有一个监听事件类,用于处理数据(Event类)
import java.text.SimpleDateFormat;
public class OrderEvent {
private long value; //订单的价格
public long getValue() {
return value;
}
public void setValue(long value) {
this.value = value;
}
}
- 实例化Disruptor实例,配置参数,编写Disruptor
import java.nio.ByteBuffer;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import com.lmax.disruptor.BlockingWaitStrategy;
import com.lmax.disruptor.EventFactory;
import com.lmax.disruptor.EventHandler;
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.dsl.ProducerType;
public class Main {
public static void main(String[] args) {
// 参数准备工作
OrderEventFactory orderEventFactory = new OrderEventFactory();
int ringBufferSize = 1024*1024;
ExecutorService executor = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
/**
* 建立OrderEvent类
* 1 eventFactory: 消息(event)工厂对象 实现 implements EventFactory接口
* OrderEventHandler implements EventHandler 用来接受数据
* 2 ringBufferSize: 容器的长度
* 3 executor: 线程池(建议使用自定义线程池) RejectedExecutionHandler
* 4 ProducerType: 单生产者 还是 多生产者
* 5 waitStrategy: 等待策略
*/
//1. 实例化disruptor对象
Disruptor disruptor = new Disruptor(orderEventFactory,
ringBufferSize, //容器大小
executor, //线程池
ProducerType.SINGLE, //SINGLE\MULTI 单生产者模式和 多生产者模式
new BlockingWaitStrategy()); //等待策略 阻塞策略
//2. 添加消费者的监听 (构建disruptor 与 消费者的一个关联关系)
disruptor.handleEventsWith(new OrderEventHandler());
//3. 启动disruptor
disruptor.start();
//4. 获取实际存储数据的容器: RingBuffer
RingBuffer ringBuffer = disruptor.getRingBuffer();
//订单生产者
OrderEventProducer producer = new OrderEventProducer(ringBuffer);
ByteBuffer bb = ByteBuffer.allocate(8);
for(long i = 0 ; i < 100; i ++){
bb.putLong(0, i);
producer.sendData(bb);
}
disruptor.shutdown();
executor.shutdown();
}
}
- 编写生产者组件,向Disruptor容器中去投递数据
import java.nio.ByteBuffer;
import com.lmax.disruptor.RingBuffer;
public class OrderEventProducer {
private RingBuffer ringBuffer;
public OrderEventProducer(RingBuffer ringBuffer) {
this.ringBuffer = ringBuffer;
}
public void sendData(ByteBuffer data) {
//1 在生产者发送消息的时候, 首先 需要从我们的ringBuffer里面 获取一个可用的序号
long sequence = ringBuffer.next(); //0
try {
//2 根据这个序号, 找到具体的 "OrderEvent" 元素 注意:此时获取的OrderEvent对象是一个没有被赋值的"空对象"
OrderEvent event = ringBuffer.get(sequence);
//3 进行实际的赋值处理
event.setValue(data.getLong(0));
} finally {
//4 提交发布操作
ringBuffer.publish(sequence);
}
}
}
3.Disruptor为什么这么快
- 环形队列RingBuffer
一个环形队列,意味着首尾相连,对列可以循环使用,使用数组来保存。环形队列在JVM生命周期中通常是永生的,GC的压力更小。
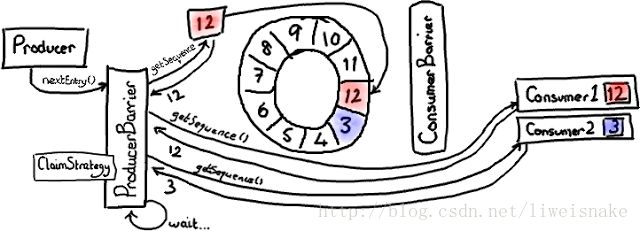
我们来解释一下这个图:当前有一个consumer,停留在位置12,这时producer假设在位置3,这时producer的下一步是如何处理的呢?producer会尝试读取4,发现下一个可以获取,所以可以安全获取,并且通知一个阻塞的consumer起来活动。如此一直到下一圈11都是安全的(这里我们假设生产者比较快),当producer尝试访问12时发现不能继续,于是自旋等待;当consumer消费时,会调用barrier的waitFor方法,waitFor看到前面最近的安全节点已经到了下一圈的11,于是consumer可以无锁的去消费当前12到下一圈11所有数据,可以想象,这种方式比起synchronized要快上很多倍。 - 弃用锁机制使用CAS
在高度竞争的情况下,锁的性能将超过原子变量的性能,但是更真实的竞争情况下,原子变量的性能将超过锁的性能。同时原子变量不会有死锁等活跃性问题。能不用锁,就不使用锁,如果使用,也要将锁的粒度最小化。
唯一使用锁的就是消费者的等待策略实现类中,下图。补充一句,生产者的等到策略就是LockSupport.parkNanos(1),再自旋判断。
- 等待策略
| 名称 | 措施 | 适用场景 |
|---|---|---|
| BlockingWaitStrategy | 加锁 | CPU资源紧缺,吞吐量和延迟并不重要的场景 |
| BusySpinWaitStrategy | 自旋 | 通过不断重试,减少切换线程导致的系统调用,而降低延迟。推荐在线程绑定到固定的CPU的场景下使用 |
| PhasedBackoffWaitStrategy | 自旋 + yield + 自定义策略 | 策略 CPU资源紧缺,吞吐量和延迟并不重要的场景 |
| SleepingWaitStrategy | 自旋 + yield + sleep | 性能和CPU资源之间有很好的折中。延迟不均匀 |
| TimeoutBlockingWaitStrategy | 加锁,有超时限制 | CPU资源紧缺,吞吐量和延迟并不重要的场景 |
| YieldingWaitStrategy | 自旋 + yield + 自旋 | 性能和CPU资源之间有很好的折中。延迟比较均匀 |
- 解决伪共享,采用缓存行填充

从上图看到,线程1在CPU核心1上读写变量X,同时线程2在CPU核心2上读写变量Y,不幸的是变量X和变量Y在同一个缓存行上,每一个线程为了对缓存行进行读写,都要竞争并获得缓存行的读写权限,如果线程2在CPU核心2上获得了对缓存行进行读写的权限,那么线程1必须刷新它的缓存后才能在核心1上获得读写权限,这导致这个缓存行在不同的线程间多次通过L3缓存来交换最新的拷贝数据,这极大的影响了多核心CPU的性能。
下面代码解决伪共享问题的,就是实例变量前后各加7个long形变量,用空间换时间。
abstract class SingleProducerSequencerPad extends AbstractSequencer
{
protected long p1, p2, p3, p4, p5, p6, p7;
SingleProducerSequencerPad(int bufferSize, WaitStrategy waitStrategy)
{
super(bufferSize, waitStrategy);
}
}
public final class SingleProducerSequencer extends SingleProducerSequencerFields
{
protected long p1, p2, p3, p4, p5, p6, p7;
//..省略
}
Java中通过填充缓存行,来解决伪共享问题的思路,现在可能已经是老生常谈,连Java8中都新增了sun.misc.Contended注解来避免伪共享问题。但在Disruptor刚出道那会儿,用缓存行来优化Java数据结构,这恐怕还很新潮。
-
还有一些细节性的
1)通过sequence & (bufferSize - 1)定位元素的index比普通的求余取模(%)要快得多。sequence >>> indexShift 快速计算出sequence/bufferSize的商flag(其实相当于当前sequence在环形跑道上跑了几圈,在数据生产时要设置好flag。2)合理使用Unsafe,CPU级别指令。实现更加高效地内存管理和原子访问。
至于一些更细节的,下面源码搞起来,还是很简单的。
3. 高性能之道-内核-使用单线程写-系统级别内存屏障实现-消除伪共享-序号栅栏机制
- disruptor的RingBuffer,之所以可以做到完全无锁,也是因为“单线程写”,这是所有“前提的前提”。
- 离开了这个前提条件,没有任何技术可以做到完全无锁。
- redis、netty(串行,并行有多线程竞争问题,buffer池)等等高性能技术框架的设计都是这个核心思想。
- 要正确的实现无锁,还需要另外一个关键技术:内存屏障
- 对应到java语言,就是valotile变量与happens before 语义。
- 内存屏障 -linux的smp_wmb()/smp_rmb()。
- 缓存系统中以缓存行为单位存储的
- 缓存行是2的整数幂个连续字节,一般为32-256个字节
- 最常见的缓存行大小是64个字节
- **当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行 **
- **就会无意中影响批次的性能,这就是伪共享。(左边填充七个long缓存行、右边填充7个long缓存行,以空间换时间实现伪共享,减少资源竞争) **
- disruptor3.0中,序号栅栏 sequenceBarrier和序号sequence搭配使用
- 协调和管理消费者与生产者的工作节奏,避免了锁和CAS的使用
- 消费者序号小于生产者序号数值
- 消费者序号数值必须小于前置(依赖关系)消费者的序号数值
- 生产者号数值不能大于消费者中最小的序号数值
- 以避免生产者速度过快,将还未来及消费的消息覆盖。
@Override
public long next(int n) //1
{
if (n < 1) //初始值 sequence= -1
{
throw new IllegalArgumentException("n must be > 0");
}
long nextValue = this.nextValue; //语义级别的: nextvalue 为singleProducerSequencer的变量
long nextSequence = nextValue + n; //0
long wrapPoint = nextSequence - bufferSize; // -10 wrapPoint用于判断当前的序号有没有绕过整个ringbuffer容器
//这个cachedGatingSequence 他的目的就是不用每次都去进行获取消费者的最小序号,用一个缓存区进行接收
long cachedGatingSequence = this.cachedValue; //-1 cachedValue我不太清楚 但是语义上说是进行缓存优化的
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > nextValue)
{
long minSequence; //最小序号
// 如果你的生产者序号大于消费者中最小的序号 那么你就挂起 进行自旋操作
//生产者号数值不能大于消费者中最小的序号数值
while (wrapPoint > (minSequence = Util.getMinimumSequence(gatingSequences, nextValue))) //自旋操作 自旋锁 避免加锁 与cas操作
// Util.getMinimumSequence(gatingSequences, nextValue) 找到消费者中最小的序号值
{
LockSupport.parkNanos(1L); // TODO: Use waitStrategy to spin?
}
this.cachedValue = minSequence;
}
this.nextValue = nextSequence;
return nextSequence;
}
4. Disruptor源码解读
- 核心类接口
Disruptor 提供了对RingBuffer的封装。
RingBuffer 环形队列,基于数组实现,内存被循环使用,减少了内存分配、回收扩容等操作。
EventProcessor 事件处理器,实现了Runnable,单线程批量处理BatchEventProcessor和多线程处理WorkProcessor。
Sequencer 生产者访问序列的接口,RingBuffer生产者的父接口,其直接实现有SingleProducerSequencer和MultiProducerSequencer。
EventSequencer 空接口,暂时没用,用于以后扩展。
SequenceBarrier 消费者屏障 消费者用于访问缓存的控制器。
WaitStrategy 当没有可消费的事件时,根据特定的实现进行等待。
SingleProducerSequencer 单生产者发布实现类
MultiProducerSequencer 多生产者发布实现类
参考:
https://www.cnblogs.com/lewis09/p/9974995.html