Hadoop Configuration配置类的分析
学习Hadoop Common模块,当然应该是从最简单,最基础的模块学习最好,所以我挑选了其中的conf配置模块进行学习。整体的类结构非常简单。
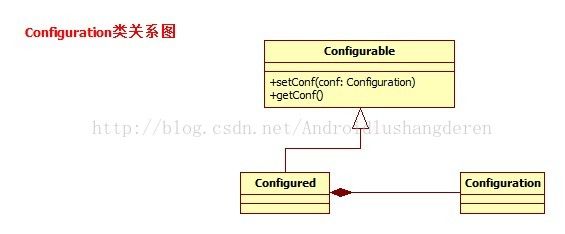
只要继承了Configurable接口,一般表明就是可配置的,可以执行相应的配置操作,但是配置的集中操作的体现是在Configuration这个类中。这个类中定义了很多的集合变量:
/**
* List of configuration resources.
*/
private ArrayList
//资源配置文件中的属性会加载到Properties属性中来
private Properties properties;
static{
//print deprecation warning if hadoop-site.xml is found in classpath
ClassLoader cL = Thread.currentThread().getContextClassLoader();
if (cL == null) {
cL = Configuration.class.getClassLoader();
}
if(cL.getResource("hadoop-site.xml")!=null) {
LOG.warn("DEPRECATED: hadoop-site.xml found in the classpath. " +
"Usage of hadoop-site.xml is deprecated. Instead use core-site.xml, "
+ "mapred-site.xml and hdfs-site.xml to override properties of " +
"core-default.xml, mapred-default.xml and hdfs-default.xml " +
"respectively");
}
//初始化中加载默认配置文件,core-site是用户的属性定义
//如果有相同,后者的属性会覆盖前者的属性
addDefaultResource("core-default.xml");
addDefaultResource("core-site.xml");
}
/**
* Add a default resource. Resources are loaded in the order of the resources
* added.
* @param name file name. File should be present in the classpath.
*/
public static synchronized void addDefaultResource(String name) {
if(!defaultResources.contains(name)) {
defaultResources.add(name);
//遍历注册过的资源配置,进行重新加载操作
for(Configuration conf : REGISTRY.keySet()) {
if(conf.loadDefaults) {
conf.reloadConfiguration();
}
}
}
}
/**
* Reload configuration from previously added resources.
*
* This method will clear all the configuration read from the added
* resources, and final parameters. This will make the resources to
* be read again before accessing the values. Values that are added
* via set methods will overlay values read from the resources.
*/
public synchronized void reloadConfiguration() {
//重新加载Configuration就是重新将里面的属性记录清空
properties = null; // trigger reload
finalParameters.clear(); // clear site-limits
}
/** A new configuration. */
public Configuration() {
//初始化是需要加载默认资源的
this(true);
}
/** A new configuration where the behavior of reading from the default
* resources can be turned off.
*
* If the parameter {@code loadDefaults} is false, the new instance
* will not load resources from the default files.
* @param loadDefaults specifies whether to load from the default files
*/
public Configuration(boolean loadDefaults) {
this.loadDefaults = loadDefaults;
if (LOG.isDebugEnabled()) {
LOG.debug(StringUtils.stringifyException(new IOException("config()")));
}
synchronized(Configuration.class) {
//加载过的Configuration对象对会加入到REGISTRY集合中
REGISTRY.put(this, null);
}
this.storeResource = false;
}以上分析的代码都是前期的操作,那么比较关键的set/get这类和属性直接相关的方法怎么实现的,所以这个时候,必须要先了解Hadoop中的配置文件是怎样的格式存在于文件中的。比如HDFS的配置文件hdfs-site.xml;
dfs.name.dir
/var/local/hadoop/hdfs/name
Determines where on the local filesystem the DFS name node
should store the name table. If this is a comma-delimited list
of directories then the name table is replicated in all of the
directories, for redundancy.
true
dfs.data.dir
/var/local/hadoop/hdfs/data
Determines where on the local filesystem an DFS data node
should store its blocks. If this is a comma-delimited
list of directories, then data will be stored in all named
directories, typically on different devices.
Directories that do not exist are ignored.
true
.......
/**
* Set the value of the name property.
*
* @param name property name.
* @param value property value.
* 根据name设置属性值,属性键值对保存在property中
*/
public void set(String name, String value) {
getOverlay().setProperty(name, value);
getProps().setProperty(name, value);
}/**
* 加载的时候采用了延时加载的策略
* @return
*/
private synchronized Properties getProps() {
if (properties == null) {
properties = new Properties();
//从资源中再次获取属性相关的数据
loadResources(properties, resources, quietmode);
if (overlay!= null) {
properties.putAll(overlay);
if (storeResource) {
for (Map.Entry item: overlay.entrySet()) {
updatingResource.put((String) item.getKey(), "Unknown");
}
}
}
}
return properties;
}
private void loadResource(Properties properties, Object name, boolean quiet) {
try {
//工厂模式获取解析xml文件对象,这里用的是doc解析方式
DocumentBuilderFactory docBuilderFactory
= DocumentBuilderFactory.newInstance();
//ignore all comments inside the xml file
docBuilderFactory.setIgnoringComments(true);
//allow includes in the xml file
docBuilderFactory.setNamespaceAware(true);
try {
docBuilderFactory.setXIncludeAware(true);
} catch (UnsupportedOperationException e) {
LOG.error("Failed to set setXIncludeAware(true) for parser "
+ docBuilderFactory
+ ":" + e,
e);
}
DocumentBuilder builder = docBuilderFactory.newDocumentBuilder();
.....
if (root == null) {
//获取xml中的节点进行获取,这里先获取了根节点
root = doc.getDocumentElement();
}
if (!"configuration".equals(root.getTagName()))
LOG.fatal("bad conf file: top-level element not ");
NodeList props = root.getChildNodes();
for (int i = 0; i < props.getLength(); i++) {
Node propNode = props.item(i);
if (!(propNode instanceof Element))
continue;
Element prop = (Element)propNode;
if ("configuration".equals(prop.getTagName())) {
//如果子节点是configuration,则再次递归调用loadResource()方法
loadResource(properties, prop, quiet);
continue;
}
if (!"property".equals(prop.getTagName()))
LOG.warn("bad conf file: element not ");
NodeList fields = prop.getChildNodes();
String attr = null;
String value = null;
boolean finalParameter = false;
for (int j = 0; j < fields.getLength(); j++) {
Node fieldNode = fields.item(j);
if (!(fieldNode instanceof Element))
continue;
//属性节点分3种判断,name,value,final
Element field = (Element)fieldNode;
if ("name".equals(field.getTagName()) && field.hasChildNodes())
attr = ((Text)field.getFirstChild()).getData().trim();
if ("value".equals(field.getTagName()) && field.hasChildNodes())
value = ((Text)field.getFirstChild()).getData();
if ("final".equals(field.getTagName()) && field.hasChildNodes())
//final参数需额外添加到finalParameters参数的集合中
finalParameter = "true".equals(((Text)field.getFirstChild()).getData());
}
// Ignore this parameter if it has already been marked as 'final'
if (attr != null) {
if (value != null) {
if (!finalParameters.contains(attr)) {
//在这步把上面去的值放入properties属性中
properties.setProperty(attr, value);
if (storeResource) {
updatingResource.put(attr, name.toString());
}
} else if (!value.equals(properties.getProperty(attr))) {
LOG.warn(name+":a attempt to override final parameter: "+attr
+"; Ignoring.");
}
}
if (finalParameter) {
finalParameters.add(attr);
}
}
} 下面我们说说get的属性获取操作,同样有别样的设计,他可不仅仅是getProps().get(name)这样的操作,因为有的时候,通过这样的操作还无法取出真正想要的值。比如下面这样的结构:
dfs.secondary.namenode.kerberos.principal
hdfs/_HOST@${local.realm}
Kerberos principal name for the secondary NameNode.
/**
* Get the value of the name property, null if
* no such property exists.
*
* Values are processed for variable expansion
* before being returned.
*
* @param name the property name.
* @return the value of the name property,
* or null if no such property exists.
*/
public String get(String name) {
return substituteVars(getProps().getProperty(name));
}
//需匹配的模式为\$\{[^\}\$ ]+\},里面多的\是在java里进行转义
//$,{,}是正则表达式中的保留字,因此需要加\,此匹配可分解为
//'\$\'{匹配的是${的部分
//最后的'\}'匹配了结尾符},这样就构成了初步的${....}的目标类型结构了
//中间[^\}\$ ]匹配了除了},$,空格除外的关键字
//+是1个修饰次数,保证中间的匹配至少为1次,也就是说中间至少有值存在
private static Pattern varPat = Pattern.compile("\\$\\{[^\\}\\$\u0020]+\\}");
private static int MAX_SUBST = 20;
private String substituteVars(String expr) {
//输入的属性匹配值,为空的话直接返回
if (expr == null) {
return null;
}
Matcher match = varPat.matcher("");
String eval = expr;
//避免循环迭代陷入死循环,这里强制最多MAX_SUBST20次的替换
for(int s=0; s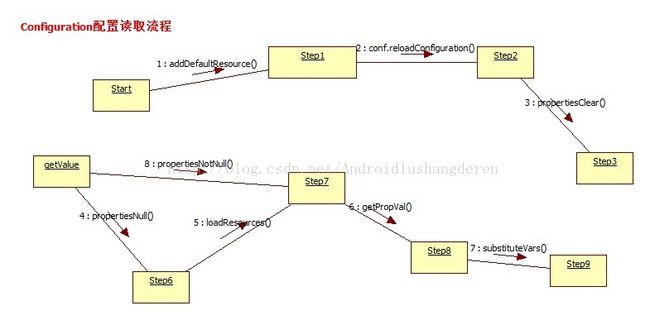
配置类代码的实现应该说是短小和精炼,以后开发大型系统的时候完全可以借鉴此类似的原理。