【Semantic Segmentation】语义分割综述 -- Atrous Convolution
【Semantic Segmentation】语义分割综述 -- Atrous Convolution
- Atrous Convolution
- [DeepLabV2] Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution,and Fully Connected CRFs 2016
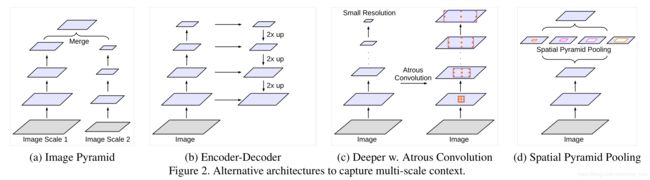
- [ASPP] atrous spatial pyramid pooling
- [DeepLabV3] Rethinking Atrous Convolution for Semantic Image Segmentation 2017-06
- [DeepLabV3+] Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation 2018-02
- code
- [DenseASPP] DenseASPP for Semantic Segmentation in Street Scenes 2019-01
Atrous Convolution
为了解决encoder+decoder 损失图片细节精度的问题,使用空洞卷积(Atrous Convolution)解决问题。
以前的CNN主要问题总结:
(1)Up-sampling / pooling layer
(2)内部数据结构丢失;空间层级化信息丢失。
(3)小物体信息无法重建 (假设有四个pooling layer 则 任何小于 2^4 = 16 pixel 的物体信息将理论上无法重建。)
[DeepLabV2] Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution,and Fully Connected CRFs 2016
https://arxiv.org/abs/1606.00915


[ASPP] atrous spatial pyramid pooling


[DeepLabV3] Rethinking Atrous Convolution for Semantic Image Segmentation 2017-06
https://arxiv.org/abs/1706.05587
[DeepLabV3+] Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation 2018-02
https://arxiv.org/abs/1802.02611v1

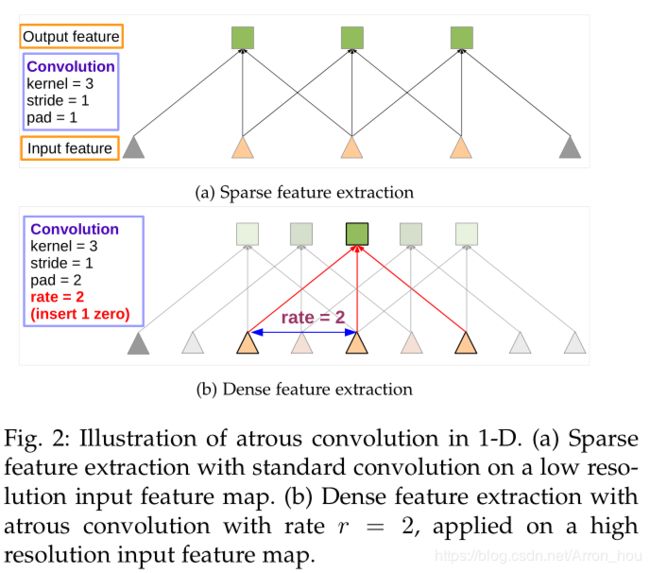
定义 output stride 为feature map较原图缩小的倍数.
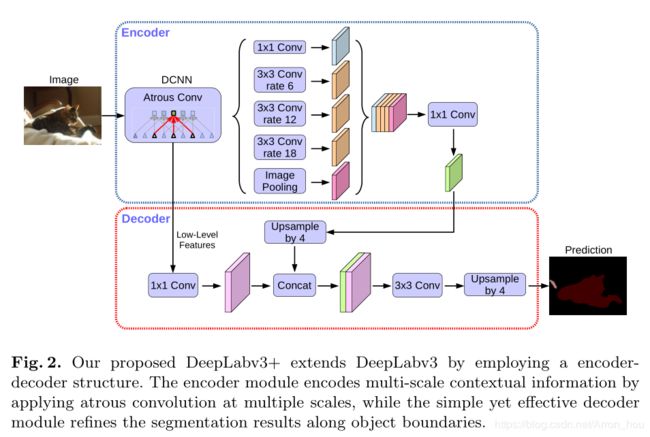
Encoder
- DCNN 可以选择resnet101,或者xception;
输出Low-Level Features 的output stride = 4,channel = 256/128(resnet101/xception);
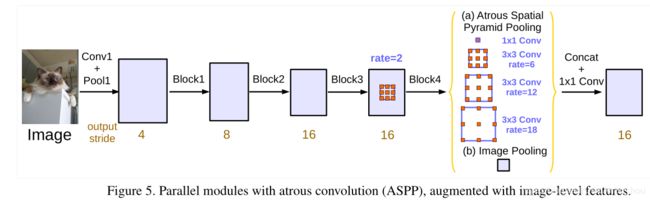
输出 tensor 的 output stride = 8/16,channel=2048; - ASPP将tensor 并行通过4个卷积层和一个全局平均池化层;
每一层的输出size 保持不变,channel数为256;
做concat 之后 通过1X1卷积特征融合,输出output stride = 8/16,channel 为256维的tensor;
Decoder
- Low-Level Features 通过1X1卷积特征融合,size 不变, 减少channel 为 48 (实验得出);
- ASPP 的输出tensor output stride = 8/16 ,需要上采样2/4倍;
- 此时size 相同,即output stride = 4 做concat得到新的tensor;
- tensor 经过卷积,上采样得到最终结果.
code
ASPP
ASPP模块通过空洞卷积提取feature map不同尺度的特征.
O = I + 2 p − d ( k − 1 ) − 1 s + 1 O = \frac{I+2p-d(k-1)-1}{s}+1 O=sI+2p−d(k−1)−1+1
其 中 I 是 输 入 f e a t u r e m a p 的 s i z e , s 表 示 步 长 s t r i d e , p 表 示 p a d , d 表 示 d i l a t i o n , O 表 示 输 出 f e a t u r e m a p s i z e 其中I 是输入feature\ map的size,s表示步长stride,p表示pad,d表示dilation,O表示输出feature \ map\ size 其中I是输入feature map的size,s表示步长stride,p表示pad,d表示dilation,O表示输出feature map size令 O = I , k = 3 令O=I,k=3 令O=I,k=3
s ( I − 1 ) = I + 2 p − 2 d − 1 s(I-1)=I+2p-2d-1 s(I−1)=I+2p−2d−1
( s − 1 ) ( I − 1 ) = 2 p − 2 d (s-1)(I-1)=2p-2d (s−1)(I−1)=2p−2d
为 了 保 证 O = I , 显 而 易 见 的 s , p , d 的 关 系 可 以 为 s = 1 , p = d = 任 意 数 为了保证O=I,显而易见的s,p,d 的关系可以为s=1,p=d=任意数 为了保证O=I,显而易见的s,p,d的关系可以为s=1,p=d=任意数
令 O = I , k = 1 令O=I,k=1 令O=I,k=1
s ( I − 1 ) = I + 2 p − 1 s(I-1)=I+2p-1 s(I−1)=I+2p−1
( s − 1 ) ( I − 1 ) = 2 p (s-1)(I-1)=2p (s−1)(I−1)=2p
为 了 保 证 O = I , 显 而 易 见 的 s , p 的 关 系 可 以 为 s = 1 , p = 0 , d 为 任 意 数 为了保证O=I,显而易见的s,p 的关系可以为s=1,p=0,d 为任意数 为了保证O=I,显而易见的s,p的关系可以为s=1,p=0,d为任意数
import torch
import torch.nn as nn
import torch.nn.functional as F
from .utils import initialize_weights
def assp_branch(in_channels, out_channles, kernel_size, dilation):
#padding 和 dilation 的设置在上面解释了
padding = 0 if kernel_size == 1 else dilation
return nn.Sequential(
nn.Conv2d(in_channels, out_channles, kernel_size, padding=padding, dilation=dilation, bias=False),
nn.BatchNorm2d(out_channles),
nn.ReLU(inplace=True))
class ImagePooling(nn.Module):
def __init__(self, in_channels):
super(ImagePooling, self).__init__()
self.avg_pool = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Conv2d(in_channels, 256, 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True))
def forward(self, x):
return F.interpolate(self.avg_pool(x), size=(x.size(2), x.size(3)), mode='bilinear', align_corners=True)
class ASSP(nn.Module):
def __init__(self, in_channels, output_stride):
super(ASSP, self).__init__()
assert output_stride in [8, 16], 'Only output strides of 8 or 16 are suported'
dilations = [None] * 4
if output_stride == 16:
dilations = [1, 6, 12, 18]
elif output_stride == 8:
dilations = [1, 12, 24, 36]
self.aspp1 = assp_branch(in_channels, 256, 1, dilation=dilations[0])
self.aspp2 = assp_branch(in_channels, 256, 3, dilation=dilations[1])
self.aspp3 = assp_branch(in_channels, 256, 3, dilation=dilations[2])
self.aspp4 = assp_branch(in_channels, 256, 3, dilation=dilations[3])
self.aspp5 = ImagePooling(in_channels)
self.conv1 = nn.Conv2d(256 * 5, 256, 1, bias=False)
self.bn1 = nn.BatchNorm2d(256)
self.relu = nn.ReLU(inplace=True)
self.dropout = nn.Dropout(0.5)
initialize_weights(self)
def forward(self, x):
x1 = self.aspp1(x)
x2 = self.aspp2(x)
x3 = self.aspp3(x)
x4 = self.aspp4(x)
x5 = self.aspp5(x)
x = self.conv1(torch.cat((x1, x2, x3, x4, x5), dim=1))
x = self.bn1(x)
x = self.dropout(self.relu(x))
return x
Decoder code
class Decoder(nn.Module):
def __init__(self, low_level_channels, num_classes):
super(Decoder, self).__init__()
self.low_level_conv = nn.Sequential(
nn.Conv2d(low_level_channels, 48, 1, bias=False),
nn.BatchNorm2d(48),
nn.ReLU(inplace=True),
)
# Table 2, best performance with two 3x3 convs
self.output = nn.Sequential(
nn.Conv2d(48 + 256, 256, 3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.LeakyReLU(inplace=True),
nn.Conv2d(256, 256, 3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.LeakyReLU(inplace=True),
nn.Dropout(0.1),
nn.Conv2d(256, num_classes, 1, stride=1),
)
initialize_weights(self)
def forward(self, x, low_level_features, H, W):
# low_level_features 变为 channel = 48
low_level_features = self.low_level_conv(low_level_features)
# 上采用2/4倍
x = F.interpolate(x, size=(low_level_features.size(2), low_level_features.size(3)),
mode='bilinear',
align_corners=True)
# concat
x = torch.cat((x, low_level_features), dim=1)
# 得到结果卷积
x = self.output(x)
# 上采用4倍 恢复到原图大小,传入H,W 是保证输入图像size不是2的倍数也可以恢复到原图大小
x = F.interpolate(x, size=(H, W), mode='bilinear', align_corners=True)
return x
DeepLabV3+的主干网络
from itertools import chain
import torch
import torch.nn as nn
import torch.nn.functional as F
from .models import getBackBone
from .models.aspp import ASSP
from .models.decoder import Decoder
class DeepLabV3Plus(nn.Module):
def __init__(self, num_classes, in_channels=3, backbone='xception', pretrained=True,
output_stride=16, freeze_bn=False, **_):
super(DeepLabV3Plus, self).__init__()
assert ('xception' or 'resnet' in backbone)
self.backbone, low_level_channels = getBackBone(backbone, in_channels=in_channels, output_stride=output_stride,
pretrained=pretrained)
self.assp = ASSP(in_channels=2048, output_stride=output_stride)
self.decoder = Decoder(low_level_channels, num_classes)
if freeze_bn:
self.freeze_bn()
def forward(self, x):
H, W = x.size(2), x.size(3)
x, low_level_features = self.backbone(x)
x = self.assp(x)
x = self.decoder(x, low_level_features, H, W)
return x
# Two functions to yield the parameters of the backbone
# & Decoder / ASSP to use differentiable learning rates
# FIXME: in xception, we use the parameters from xception and not aligned xception
# better to have higher lr for this backbone
def get_backbone_params(self):
return self.backbone.parameters()
def get_decoder_params(self):
return chain(self.ASSP.parameters(), self.decoder.parameters())
def freeze_bn(self):
for module in self.modules():
if isinstance(module, nn.BatchNorm2d): module.eval()
参考
[细致讲解] https://blog.csdn.net/u011974639/article/details/79518175
[code] https://github.com/ArronHZG/segmentation-pytorch/tree/master/torch_model/net/DeepLabV3Plus
[DenseASPP] DenseASPP for Semantic Segmentation in Street Scenes 2019-01
http://openaccess.thecvf.com/content_cvpr_2018/papers/Yang_DenseASPP_for_Semantic_CVPR_2018_paper.pdf
DenseASPP 结合了ASPP和denseNet 的优点。
ASPP 的结构是一种平行的结构,通过不同的空洞卷积获得不同的感受野,兼顾了宏观和微观的语义信息。
而另一种结构例如Encode 和 Decode 是一种级联结构(cascading) ,天然地可以获得更大的感受野,但是对于物体边缘信息的判别就不是很准。
DenseASPP 综合了上述两种结构的优势。在Cityscapes数据集上在cat 取得了90.7的mIOU。