数据库实验4HBase应用开发实验
HBase应用开发实验1
Using HBase for Real-time Access to your BigData
Running HBase operations using the Java client API
内容
使用JAVA客户机APIHBASE操作运行
2.1 设置您的ECLIPSE环境
2.2编码HBASE的JAVA类
2.3运行HBASE的JAVA类
2.4总结
使用Java客户端API运行HBase操作
在这个实验室中,我们将回顾演示不同HBase操作用法的实际Java代码。HBase是用Java构建的,它的本地API是用Java编写的。虽然可以将HBase shell用于简单甚至管理任务,但HBase应用程序需要某种编程语言来充分利用它提供的所有功能。然而,Java并不是惟一可以使用的语言。我们将在另一课中讨论其他客户机api。
完成这个动手实验后,你将能够:
•使用客户端API创建Java类来使用HBase操作
这些练习的解决方案可以在您从大数据大学课程网页下载的文件中的Lab_Files/LabSolutions中找到。
这个实验室假设您对Eclipse环境有一定的了解。
允许60到90分钟来完成这部分实验。这个版本的实验是使用InfoSphere BigInsights 2.1 Quick Start版本设计的。在整个实验过程中,您将使用以下帐户登录信息:

2.1设置Eclipse环境
为了准备这个实验,您必须设置Eclipse环境。
__1。在桌面上双击Eclipse图标:

__2。选择默认工作区:
__3。一旦工作区启动,您将看到以下屏幕:
__4。首先,创建一个Java项目。给它一个项目名HBase_Exercises。其他一切都可以作为默认:
__5。创建项目之后,您将配置构建路径以包含HBase库。BigInsights提供了一个库文件,从而简化了这一过程。Right-click 项目 Build Path Configure Build Path:
__6。选择Libraries选项卡,并添加Library:
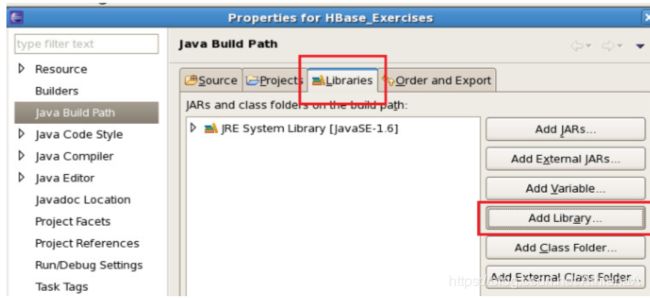
__7。选择BigInsights库
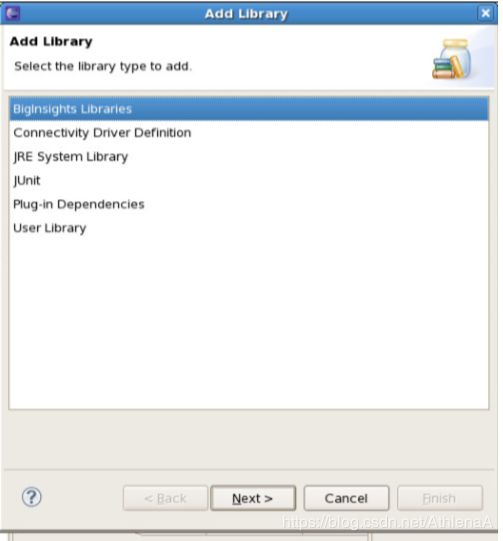
单击Next,然后单击Finish添加库。然后单击OK以退出构建路径属性。此时,您应该已经将BigInsights库添加到项目的构建路径中。
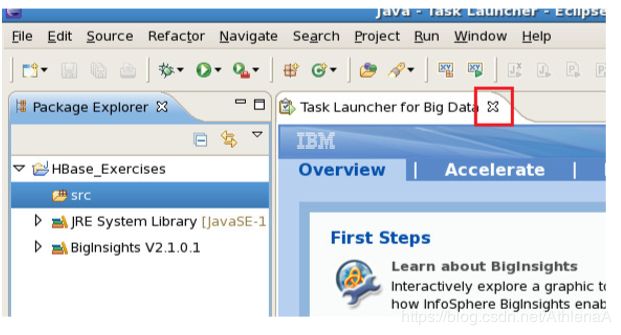
__8。在您的工作区中,继续并关闭Big Data选项卡的任务启动器。你不需要这个:
__9。现在您将为Java类创建包
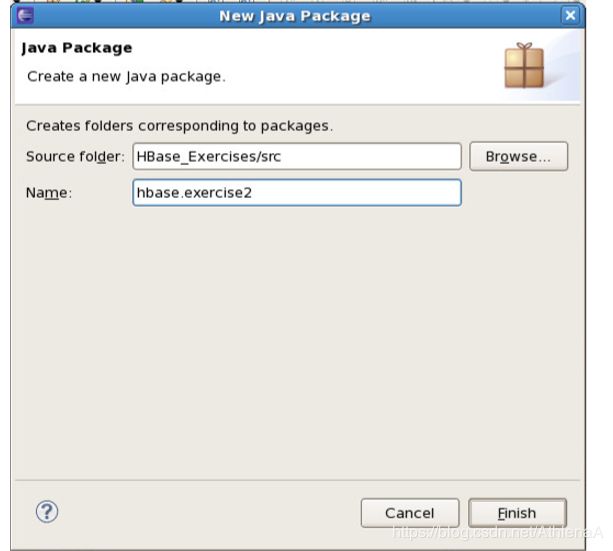
__10。右键单击src文件夹,然后转到New和Package。将包命名为:hbase.exercise2. 单击Finish创建包。
__11。在开始这门课程之前,您应该已经从大数据大学的课程页面下载了实验文件。如果你没有下载它们,请回到课程页面获取实验文件的说明。
__12。您将把练习2的文件导入Eclipse工作区。这些文件是部分完成的类,您将有机会在其中填写完成类所需的代码。右键单击hbase。您已经创建的练习2包,并选择Import。Then Choose General File System:
单击Next。
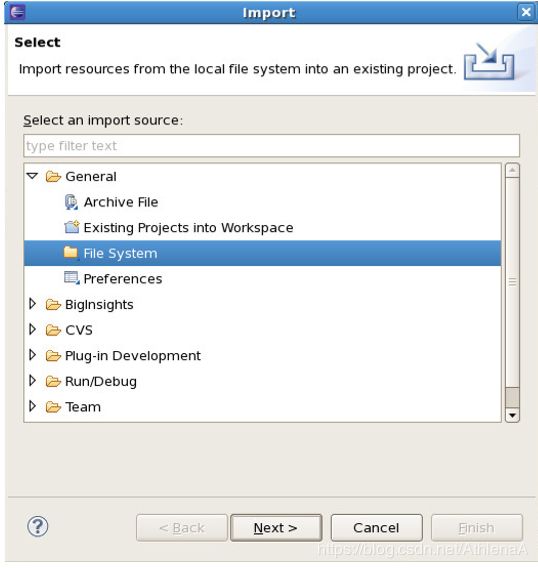
__13。导航到Exercise2 目录,选择要导入的所有3个文件并单击Finish
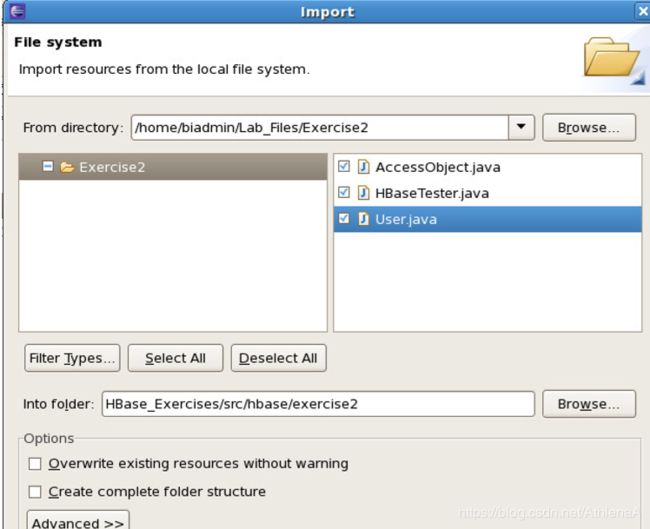
2.2 Coding the HBase Java classes
在本节中,您将编写大量的Java代码来访问HBase。不要害怕,如果你真的陷入困境,这里有一个解决方案。解决方案与您下载的实验文件一起找到。
__14。现在所有3个类都已经添加了,我们将逐一介绍。首先,打开User.java类:
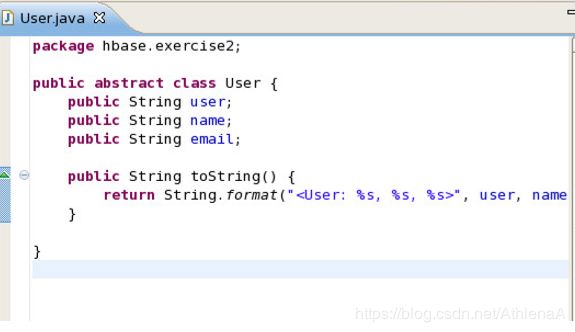
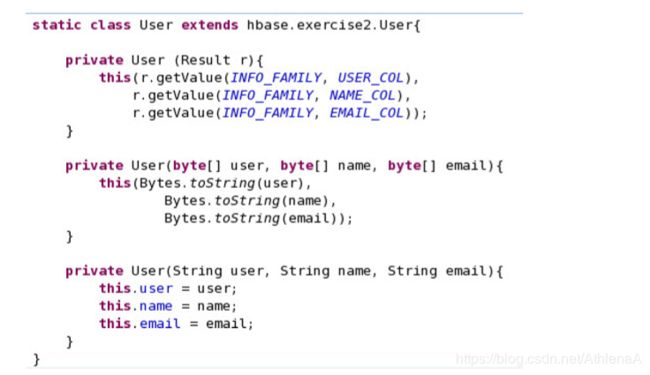
这个类基本上是我们的用户对象。我们将创建不同的用户来加载到HBase中。在这里,除了理解User对象的字段之外,您没有什么可做的。
__15。需要再次强调的是,在我们的练习中,我们使用的是人类可读的列,例如“user”、“name”和“email”。这使您更容易理解HBase的列和列族的概念。实际上,您不希望这样做,因为列名是以字节的形式与物理HFiles一起存储的。如果每个列跨多个hfile(在BigData世界中很可能是这样),并对成千上万个列重复此操作,那么将占用大量内存并降低HBase的效率。在继续之前,一定要理解这个概念。
__16。接下来,打开AccessObject.java。这个类将是我们大部分HBase编码的地方。这个类将访问HBase表。在这个类中有部分完成的代码片段,您可以自己完成它。让我们来看看这个类的整体结构:
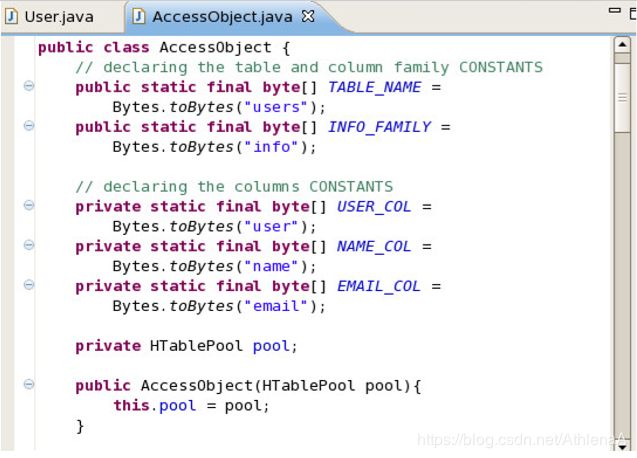
第一部分只是常用字节的声明。回想一下,HBase以字节的形式存储所有数据。因此,为了处理任何事情,我们需要使用Java提供的Bytes实用程序类。这里我们只是设置了表名、列族和列限定符的字节常量。稍后,我们可以只引用它们的常量,而不是每次都进行字节转换。
在常量声明之后,我们只声明用于管理表连接的HTablePool。创建一个表实例是一个相对昂贵的操作,因此我们将使用HTablePool来处理它。本课程后面会有更多关于这个主题的内容。现在,我们只使用HTablePool来管理表。
最后,我们有了AccessObject构造函数,它只是初始化池。
__17。每次我们想调用Get命令时,我们需要创建一个Get对象,传入适当的限定符来告诉HBase要检索什么。这个mkGet方法将创建并返回Get对象。我们需要添加列族来缩小返回给我们的内容。添加代码以指定Get对象的列族。
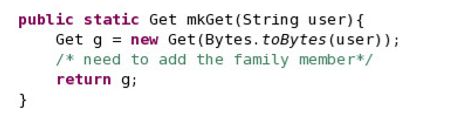
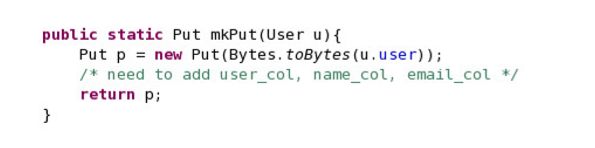
__18。你可以对Put函数做类似的事情。您需要为放入HBase中的每个用户对象指定用户列、名称、列和电子邮件列。请记住,对于传入Put的用户对象的每个属性,都需要将其转换为字节。这是第一个让你开始的:
p.add(INFO_FAMILY, USER_COL,Bytes.toBytes(u.user)); Do the same for u.name and u.email.
__19。对于我们的示例,mkDelete非常简单。我们将使用指定的行键删除用户。这里不需要做什么,只需要理解mkDelete方法是如何编码的。

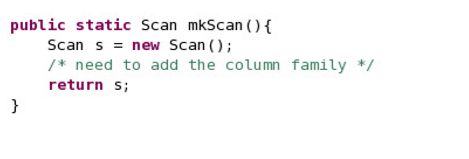
__20。对于Scan函数,需要将列族添加到mkScan方法中,以确保只从特定的列族进行扫描。
__21。现在您已经创建了所有的helper方法,现在可以创建与HBase表直接交互的实际方法了。getUser (get)、addUser (put)、deleteUser (delete)和getUsers (scan)这4个方法将为我们实现这一点。
让我们看看我们需要做什么。我们需要做的第一件事是通过使用HTablePool对象获得表的句柄。我们将这个对象传递给充当表传递器的HTableInterface。然后我们调用mkGet来创建用户的Get对象。一旦创建了get对象,我们只需调用表的get命令并将结果传递到结果对象中。亲自。
__a。您可以使用以下命令:Result result = users.get(g);
__b。然后,您基本上需要从结果创建一个User对象,并通过返回该对象将其传递给调用方法。我们通过允许您使用Result对象作为参数来创建User对象,从而简化了这一过程:User (Result r);
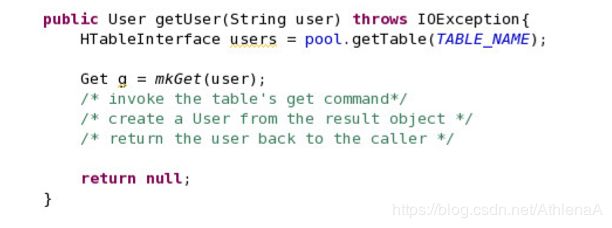
__c。删除“return null”并替换为返回用户的实例。
__22。创建addUser()方法。
__a。从HTablePool获取表句柄的第一行与上一步中的getUser()方法相同。
__b。回想一下,mkPut方法将用户作为输入。使用mkPut(User u)创建Put对象,
Put p = mkPut(new User(user,name,email));
__c。调用表的put命令将对象插入表中。
users.put§;
__d。关闭表的连接资源。
users.close ();

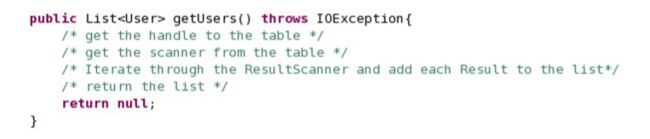
__23。创建getUsers()方法。这个方法与您已经创建的getUser()方法稍有不同,没有s。这一项获取表的所有用户。
__a。把句柄拿到表上。
__b。通过调用mkScan()方法获取扫描仪对象
ResultScanner results = users.getScanner(mkScan());
__c。然后您希望遍历结果并将每个用户添加到列表中。
ArrayList al = new ArrayList();
for(Result r : results) { al.add(new User®); }
__d。最后,我们需要返回列表。
__24。创建deleteUser()方法。

__25。AccessObject类的其余部分已经为您完成。它包含用户类的构造函数。
__26。最后,我们的最后一个类HBaseTester.java包含main()方法。这个类已经为你完成了。它运行我们所有的方法。花几分钟时间打开HBaseTester类,看看它是做什么的。
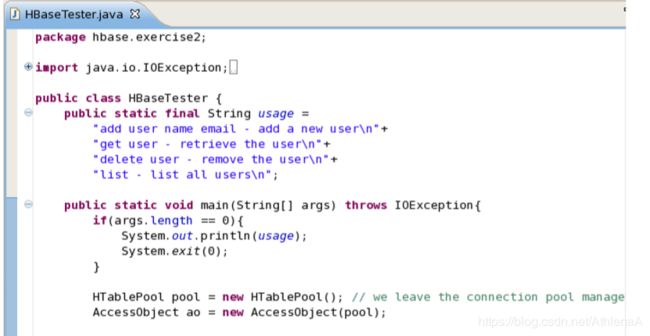
本质上,hbasetest .java将接受您想要做的事情的参数。例如,如果您想添加一个用户,然后传入参数“add ”,其中的值就是您提供的值。
2.3运行HBase Java类
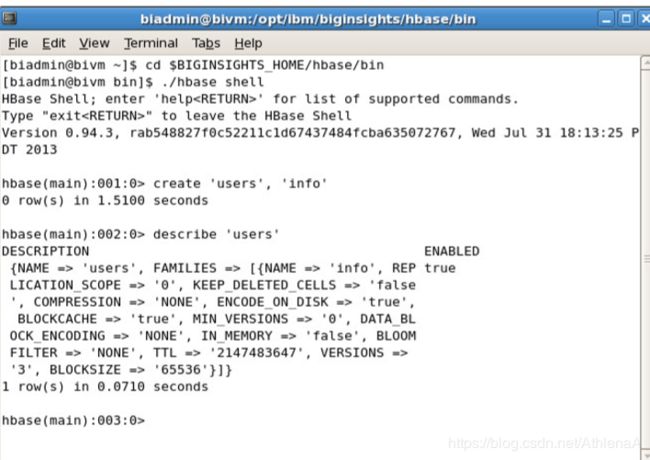
__27。在运行这些类之前,需要在HBase中创建一个可以使用的表。我们将在后面的课程中了解如何创建表和模式,所以现在,使用HBaseShell创建表。打开HBase Shell并输入以下命令:
create ‘users’, ‘info’
__28。现在您已经有了表,回到Eclipse来执行您的类。请记住,如果您需要,我已经将完成的类包含在lab文件的LabSolutions文件夹中。
Go , Run Run Configurations bar. 从 菜单双击Java应用程序创建一个新的运行配置:
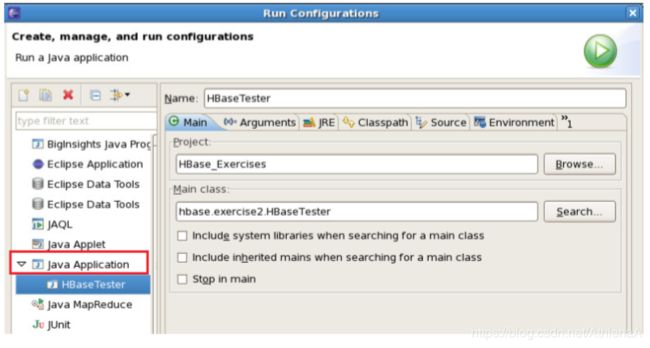
__29。单击Arguments选项卡并添加以下参数:
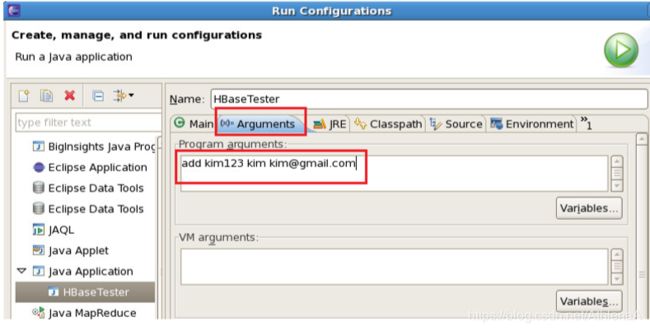
__30。您告诉程序将用户(kim123) name (kim) email ([email protected])添加到HBase表中。
__31。添加运行程序的参数后,单击Run。您将看到添加了该用户的控制台的输出。
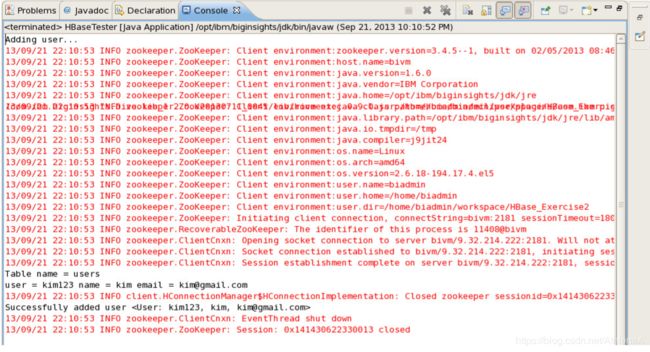
__32。使用以下参数再次运行程序,并注意它们的输出,以查看不同的结果。
__a。添加jay456 Jay [email protected]
__b。添加scottie789 scottie [email protected]
__c。列表
__d。删除jay456
__e。列表
__f。得到kim123
__a. add jay456 Jay [email protected]
__b. add scottie789 scottie [email protected]
__c. list
__d. delete jay456
__e. list
__f. get kim123
__33。你已经做完这个实验练习了。继续保存并关闭Eclipse以及您可能打开的任何其他窗口或终端。
2.4小结
做得好!您已经创建了Java类来演示HBase Get、Put和Scan操作的使用。当您开始考虑如何为BigData应用程序开发时,这些都是HBase的构建块。我们在这里看到的大多数任务都可以很容易地实现,使用HBase Shell要快得多。您可能会问,当HBase Shell能够以一种更有效的方式完成此任务时,为什么我应该使用Java ?Java(和其他客户机api)允许您构建使用Shell无法完成的更复杂的应用程序。
HBase应用开发实验2
Using HBase for Real-time Access to your BigData
Using administrative and advance features for schema creation and data retrieval
使用管理和高级功能的模式创建和数据检索
3.1使用HBASEADMIN API创建和修改模式
3.2为HBASE装载一个数据集
3.2.1 HDFS加载数据
3.2.2导入数据到HBASE
3.3 创建和使用过滤器来检索数据
3.4与计数器合作
3.5小结
使用管理和高级特性来创建模式和检索数据
在这个实验室中,您将使用HBaseAdmin API创建和更新模式。这将允许您为数据创建表和列族。然后您将使用Java API来利用过滤器和计数器。作为该实验室设置的一部分,您将看到如何使用ImportTsv工具加载示例数据集。
完成这个动手实验后,你将能够:
•使用HBaseAdmin API创建和修改HBase表和模式
•使用ImportTsv工具将数据加载到HBase中
•对扫描应用过滤器或获取操作以增强从HBase返回的数据
•使用计数器收集统计信息
这个实验室假设您对Eclipse环境有一定的了解。您在VM映像中下载的文件中包含了lab解决方案。
允许60分钟到90分钟来完成这部分实验。这个版本的实验是使用InfoSphere BigInsights 2.1 Quick Start版本设计的。在整个实验过程中,您将使用以下帐户登录信息:
3.1使用HBaseAdmin API创建和修改模式。
通过直接从shell创建表和列族,如果需要以编程方式创建它们呢?使用HBaseAdmin API将允许您这样做。
这部分练习的解决方案可以在Lab_Files/LabSolutions中找到。
__1。启动Eclipse并转到默认工作区。Exercise 2的文件很可能在您的工作区中打开,如果您之前没有关闭它们的话。现在全部关闭:
__2。您将创建一个名为:hbase.exercise3的新包。然后将部分完成的类从 Lab_Files/Exercise3下的实验室文件导入工作区。这是您应该导入的四个文件。

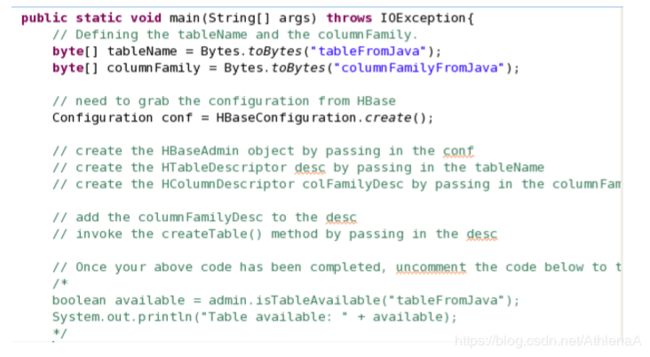
__3。使用HBaseAdmin创建一些表。打开HBase_SchemaTester.java。填写所需的代码。
__a. HBaseAdmin admin = new HBaseAdmin(conf);
__b. HTableDescriptor desc = new HTableDescriptor(tableName);
__c. HColumnDescriptor colFamilyDesc = new HColumnDescriptor(columnFamily);
__d. desc.addFamily(colFamilyDesc);
__e. admin.createTable(desc);
__f. Uncomment the code to test if the table has been created to complete the method for creating the table.
__4。运行该程序以查看表是否已创建。如果您在上面的步骤中没有这样做,请确保取消注释测试表是否可用的行。输出的结果应该返回true。
![]()
您还可以转到HBaseShell并输入命令列表或描述“tableFromJava”来查看它。
__5。一旦创建了表,就需要注释掉刚才编写的代码,这样就可以运行下一组代码来修改现有的表。继续并注释掉这些行。

您可以保留方法的其他部分不变,因为您仍然需要它们来修改表。
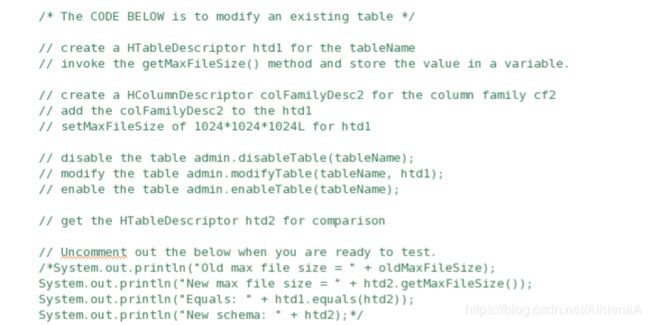
__6。现在需要创建修改表的代码。您将在刚刚注释掉的代码下面输入代码。
__a. HTableDescriptor htd1 = admin.getTableDescriptor(tableName);
__b. long oldMaxFileSize = htd1.getMaxFileSize();
__c. HColumnDescriptor colFamilyDesc2 = new HColumnDescriptor(Bytes.toBytes(“cf2”));
__d. htd1.addFamily(colFamilyDesc2);
__e. htd1.setMaxFileSize(1024 * 1024 * 1024L);
__f. admin.disableTable(tableName);
__g. admin.modifyTable(tableName, htd1);
__h. admin.enableTable(tableName);
__i. HTableDescriptor htd2 = admin.getTableDescriptor(tableName);
__j. Uncomment out the System.out.println() to test your class
__7。完成后,运行该程序,您应该会看到基于System .out系列的模式修改。
3.2将数据集加载到HBase中
3.2.1将数据加载到HDFS中
为本次实验做准备,您将使用BigInsights将样本数据集加载到HBase中。GSDB数据库是一个丰富而真实的数据库,其中包含Great Outdoors company(一个虚构的户外设备零售商)的样本数据。为了简单起见,我们将只使用这个数据库中的一个表。
首先,我们将把该文件加载到HDFS中。然后我们将它导入到HBase表中。
您应该已经下载了本练习的实验文件。如果你没有下载它们,去大数据大学的课程页面获取获取实验文件的说明。您将需要SLS_Sales_Fact.txt文件。
__8。双击BigInsights

__9。导航到Files选项卡,转到users下的biadmin目录,单击菜单栏上的“create new directory”图标。
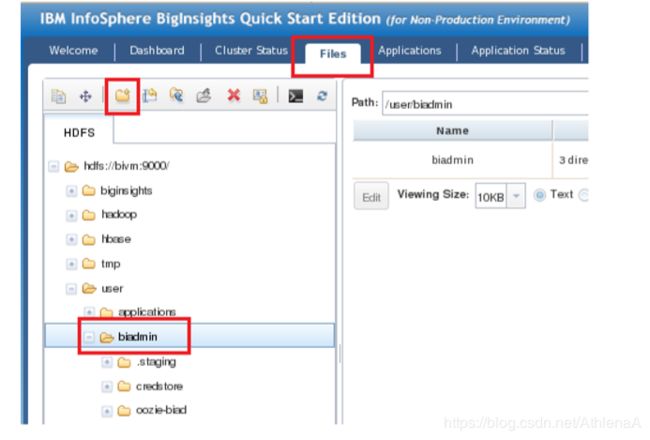
__10。将新文件夹命名为:exercise3
__11。选择练习3目录,然后点击上传图标:
__12。单击Browse并搜索要在Lab_Files/SLS_SALES_FACT.txt下上传的文件
__13。单击Open,然后单击OK上传文件。上传完成后,您将看到该文件。
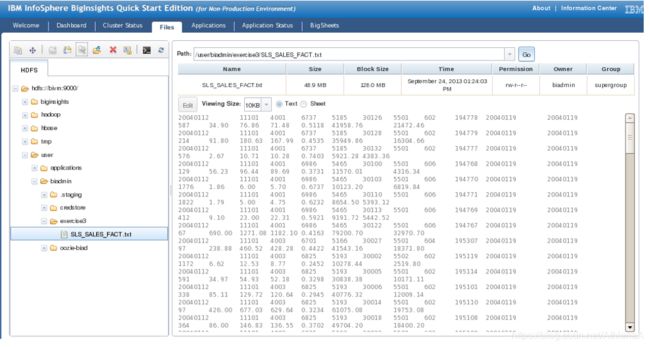
3.2.2。将数据导入HBase
__14。接下来要做的是创建表sales_fact,该表只有一个列族,只存储其值的一个版本。您将使用这个shell命令来完成:
create ‘sales_fact’, {NAME=> ‘cf’, VERSIONS=>1}
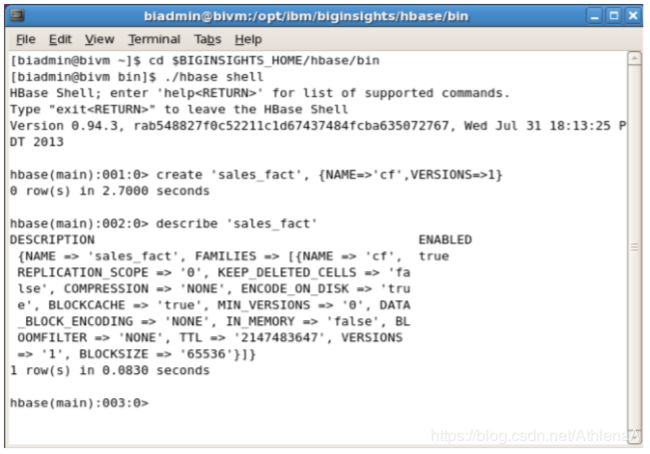
__15。表已经创建,继续并退出HBase Shell。
__16。现在我们将使用ImportTsv工具将数据加载到sales_fact表中

请再次记住,这里的列是传统RDBMS中典型列名的代表。在HBase中,您不希望这样命名列,而是尽可能使用简短的列名。
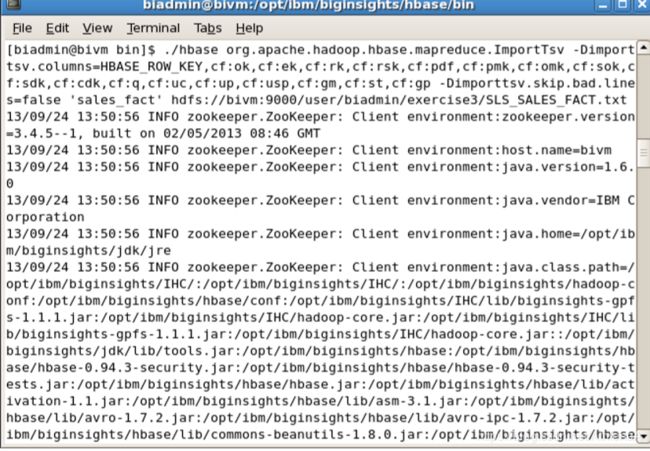
__17。运行此命令添加列及其各自的值:
$HBASE_HOME/bin/hbase org.apache.hadoop.hbase.mapreduce.ImportTsv - Dimporttsv.columns=HBASE_ROW_KEY,cf:ok,cf:ek,cf:rk,cf:rsk,cf:pdk,cf:pmk,cf: omk,cf:sok,cf:sdk,cf:cdk,cf:q,cf:uc,cf:up,cf:usp,cf:gm,cf:st,cf:gp - Dimporttsv.skip.bad.lines=false ‘sales_fact’ hdfs://bivm:9000/user/biadmin/exercise3/SLS_SALES_FACT.txt
__18。完成后,通过在HBase shell中使用以下命令计算结果中的行:
count ‘sales_fact’
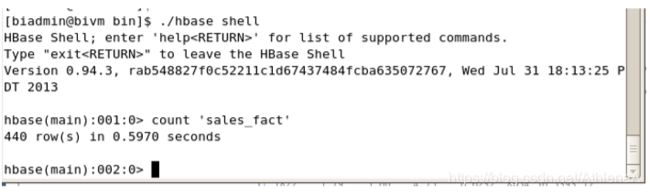
您已经将440行导入到’ sales_fact '表中。数据已经加载。转到下一节处理数据集。
3.3创建和使用过滤器来检索数据
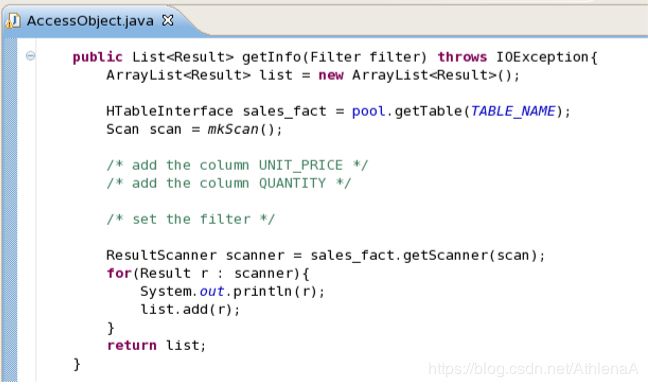
__19。我们将首先处理过滤器。打开AccessObject.java并转到getInfo()方法。在这个方法中,您将在sales_fact表上创建一个扫描程序。您希望将扫描限制为仅两列,这对于我们的目的已经足够了。稍后将创建筛选器,现在编写代码添加这两列并设置筛选器:
__a. scan.addColumn(COLUMN_FAMILY, UNIT_PRICE);
__b. scan.addColumn(COLUMN_FAMILY, QUANTITY);
__c. scan.setFilter(filter);
__20。现在打开HBase_FilterTester.java。在这里,您将编写代码来创建五个不同的过滤器。
__a. Filter f1 = new RowFilter(CompareFilter.CompareOp.LESS_OR_EQUAL, new BinaryComparator(Bytes.toBytes(“20070920”)));
__b. Filter f2 = new RowFilter(CompareFilter.CompareOp.LESS_OR_EQUAL, new BinaryComparator(Bytes.toBytes(“20050920”)));
__c. Filter f3 = new RowFilter(CompareFilter.CompareOp.EQUAL, new RegexStringComparator(".*2006.")); __d. Filter f4 = new QualifierFilter(CompareFilter.CompareOp.LESS_OR_EQUAL, new BinaryComparator(Bytes.toBytes(“q”)));
__e. Filter f5 = new ValueFilter(CompareFilter.CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes(“136.90”)));

__21。编写完这5个过滤器后,取消对ao.getInfo(f1)的注释,并在每个过滤器上运行程序,查看结果以验证过滤器。您还可以更改比较运算符或周围的比较器,以查看不同的结果。
3.4与计数器一起工作
__22。接下来,您将使用计数器。返回AccessObject.java类。我们有一个递增计数器穿孔mincrement()方法。编写适当的代码来完成这个方法:
__a. Increment increment1 = new Increment(Bytes.toBytes(rowkey));
__b. increment1.addColumn(COLUMN_FAMILY, Bytes.toBytes(“ViewCount”), viewCountValue);
__c. increment1.addColumn(COLUMN_FAMILY, Bytes.toBytes(“AnotherCount”), anotherCountValue);
__d. Result result1 = sales_fact.increment(increment1);
__e. Uncomment out the last section of the code to complete the method.
__23。一旦你完成了AccessObject.java,打开HBaseCounterTester.java:
我们只是随机选择一行来添加前面定义的两列计数器:ViewCount和AnotherCount。要增加的两个值是1和20。运行HBase_CounterTester以查看计数器结果。多次运行它以查看计数器增量。

__24。用负值运行它可以看到计数器减少,或者用0运行它可以得到当前值:
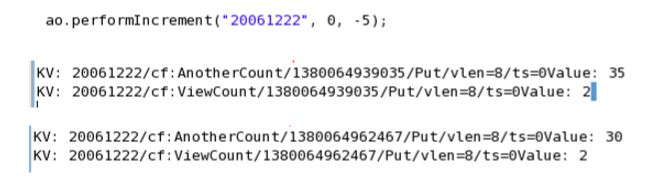
__25。你已经做完这个实验练习了。继续保存并关闭Eclipse以及您可能打开的任何其他窗口或终端。
3.5总结
工作出色!在为一些课程使用了表之后,您现在已经了解了如何使用HBaseAdmin API为应用程序以编程方式创建表。同样值得一提的是,您可以使用HBase Shell命令创建表,但是在应用程序中,您将使用某种客户机API。
现在您应该熟悉一些可用来过滤从HBase返回的数据的筛选器。您还应该了解计数器是如何工作的。过滤器和计数器对于HBase非常重要,因为它们允许您缩小大型数据集(我们处理的是大数据,因此您将拥有大量数据)的范围,以便快速获得所需的数据。计数器帮助您管理和收集表的统计信息。
另外,作为实验室设置的一部分,您了解了如何使用ImportTsv工具将一些数据导入HBase。首先,必须将数据加载到HDFS中。然后运行工具,该工具指定文本文件中的数据的列族和列名。
HBase应用开发实验3
Using HBase for Real-time Access to your BigData
Integrating HBase as a data source of a MapReduce job
整合HBASE的数据源 MAPREDUCE工作
5.1建立一个现有HBASE表的数据源MAPREDUCE工作
5.2运行MAPREDUCE工作与HBASE表作为源
5.3(可选)建立HBASE沉入MAPREDUCE工作
5.4总结
将HBase集成为MapReduce作业的数据源
MapReduce需要完成大量任务,并将它们分解为分布在集群中的更小的可管理任务。显然,将HBase与MapReduce集成是这些技术的自然发展。HBase支持数据的快速访问,结合MapReduce的设计,非常适合大数据应用。在这个实验室中,您将设置一个现有的HBase表作为MapReduce作业的源,然后运行MapReduce作业以获得sales_fact表中每个产品键出现的次数。
完成这个动手实验后,你将能够:
•使用Java API作为MapReduce作业的数据源来设置现有的HBase表
•运行MapReduce作业来分析来自HBase表的数据。
•验证MapReduce作业的输出
•(可选)将HBase设置为MapReduce作业的源和接收器
在60分钟至90分钟内完成本部分的实验。在整个实验过程中,您将使用以下帐户登录信息:
5.1设置现有HBase表作为MapReduce作业的数据源
在本节中,您将使用现有HBase表sales_fact作为MapReduce作业的数据源。这个工作的目的是获得一个产品销售次数的计数。作业将计算pdk (product_key)并将结果发送到一个文件。
__1。启动Eclipse

__2。选择您一直在使用的同一个工作区:
__3。为这个练习创建一个新包: hbase.exercise5:
__4。现在您想要从您上传的文件中导入ProductAnalyzer.java类。它应该存储在Lab_Files/Exercise5下。右键单击包并选择Import。选择“文件系统”并单击“下一步”。
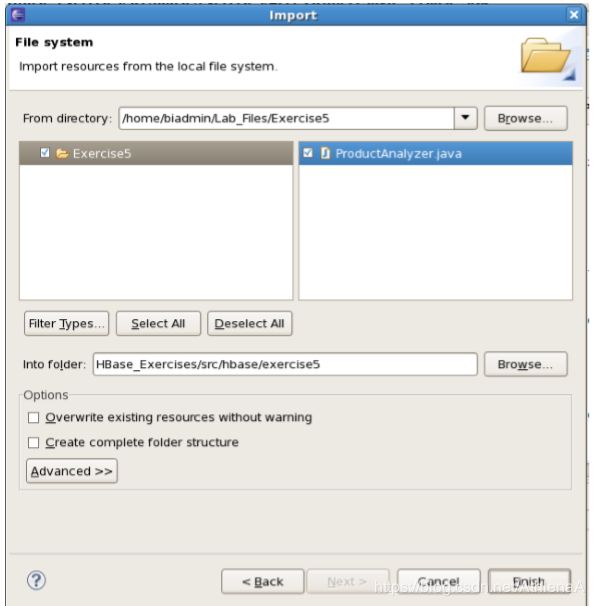
__5。导航到 Exercise 5 目录,并选择要导入的ProductAnalyzer.java类。
注意:现在还可以导入一个可选的 ProductAnalyzer_Sink.java 类。它将HBase表设置为接收器。此可选部分包含在本练习的最后。完成之后单击Finish。
__6。打开ProductAnalyzer类(如果还没有关闭所有其他类,则关闭它们)。
__7。Mapper类称为ProductMapper,它扩展了TableMapper
Text和IntWritable是这个mapper类的输出键和输出值。
除了这个实验,您还将看到一些计数器被用于跟踪统计数据。我们实际上不会对它们做任何操作,但是您将能够在作业完成后看到控制台上显示的计数器。
在map方法初始化之后输入这行代码;
context.getCounter(Counters.ROWS).increment(1);
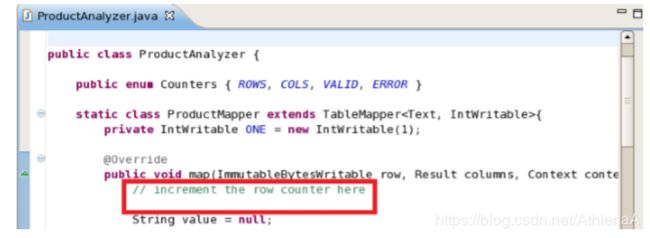
__8。现在您将实现map方法的其余部分。注意,结果列被传递到这里的方法中。这个值是从我们稍后将看到的Scan对象中检索的。现在,我们的map方法的目标是从结果对象中获取每个值,结果对象将是sales_fact表的pdk或product键,并将其映射到一个值1。我们将对所有pdk执行此操作,并将此操作传递给mapper,后者将计算每个pdk的值。输入两行代码,每一行对应一个注释。
__a. value = Bytes.toStringBinary(kv.getValue());
__b. context.write(new Text(value), ONE);

__9。现在,实现Reducer类和reduce方法。在这里,我们希望reducer通过将来自映射器的每个值相加来计算键的每个出现次数。输入两行代码
__a. for (IntWritable one: values) count ++;
__b. context.write(key, new IntWritable(count));

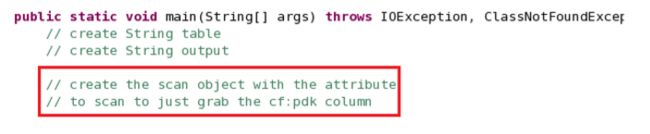
__10。现在转到main方法()。首先要指出的是,我们的程序将接受两个参数。第一个参数是表名。第二个参数是输出目录。分别将这些参数分配给字符串表和输出。
__a. String table = args[0];
__b. String output = args[1];

__11。下一步是创建scan对象,仅扫描pdk列。
__a. Scan scan = new Scan();
__b. scan.addColumn(Bytes.toBytes(“cf”), Bytes.toBytes(“pdk”));
__12。使用HBase中的配置创建作业,并使用包含映射器和reducer的类设置作业的类:
__a. job.setJarByClass(ProductAnalyzer.class);

__13。您将使用TableMapReduceUtil类来设置作业。输入:
__a. TableMapReduceUtil.initTableMapperJob(table, scan, ProductMapper.class, Text.class, IntWritable.class, job);
__14。使用作业对象分配减速机。
__a. job.setReducerClass(ProductReducer.class);
__15。分配reducer的输出键类
__a. job.setOutputKeyClass(Text.class);
__16。指定reducer的输出值类
__a. job.setOutputValueClass(IntWritable.class);
__17。设置reduce任务的编号
__a. job.setNumReduceTasks(1);
__18。设置输出格式
__a. FileOutputFormat.setOutputPath(job, new Path(output));
5.2以HBase表为源运行MapReduce作业
您已经创建了应用程序,以HBase表为MapReduce作业的源。在本节中,您将运行应用程序并查看MapReduce作业的结果。
__19。转到Run Configuration并双击Java Application以创建新的配置。
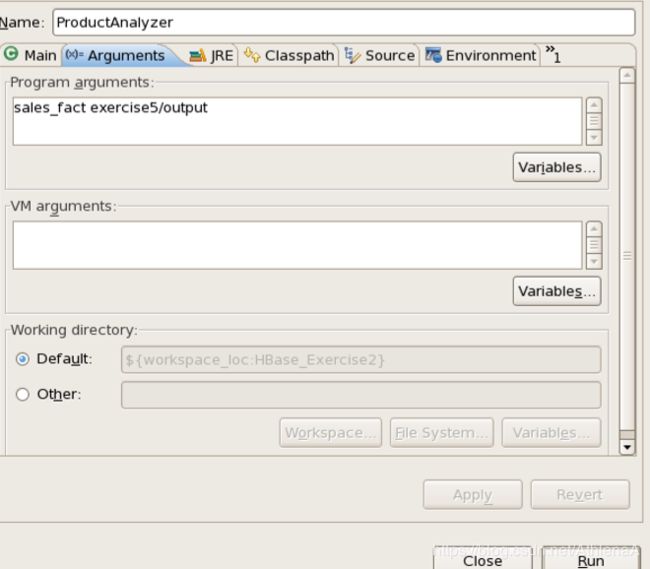
__20。在arguments选项卡上,输入程序参数。回想一下,我们已经将第一个参数指定为表名,第二个参数指定为输出目录。输出目录必须不存在,否则将引发错误。这是MapReduce作业的行为。输出目录路径将相对于java应用程序。
__21。运行工作。
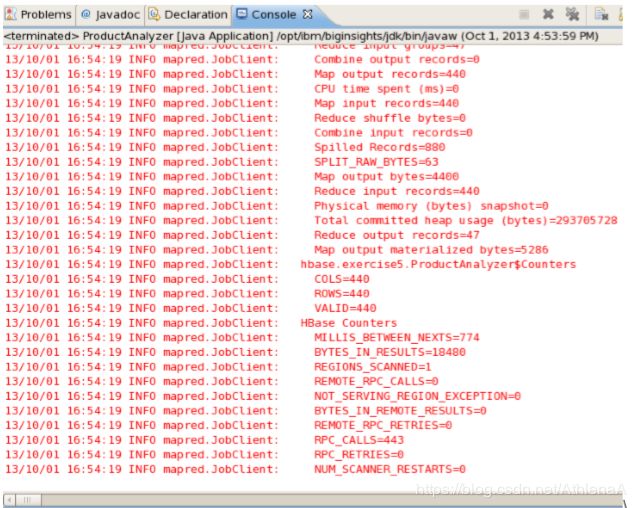
注意,一旦作业完成,您将看到在这里创建的计数器。它经过了440行(这是我们原始数据集中的行数!)
__22。让我们导航到创建输出以查看结果的工作区。打开一个终端,输入以下命令以到达输出目录:
cd $HOME/workspace/HBase_Exercises/exercise5/output
执行目录的列表,您将看到输出文件。

__23。使用以下命令打开输出文件part-r-00000:
gedit part-r-00000

__24。从结果中,您可以看到已售出的产品数量(基于其product_key)。把特定产品的销售数量记下来:30256。(售出15件)
_25。为了好玩,让Hive自己执行相同的工作来验证结果。打开蜂箱壳:
__26。请记住,我们已经从HBase表在Hive中创建了一个表。我们将这个表称为hbase_sales_fact。让我们通过运行从表中选择数据来确保它仍然在那里。
select * from hbase_sales_fact;
__27。现在让我们运行一个查询,它将给出pdk 30256的计数。我们已经将这个值映射到Hive上的product_key。运行这个查询:
select count(product_key) from hbase_sales_fact where product_key = 30256;


您可以看到,这两种方法都产生了相同的结果,但是要知道,我们所使用的数据集和作业的实际复杂性与典型作业相去甚远。与分布式设置相比,我们还在单个节点上运行。因此,根据您的数据集和数据访问模式,您需要决定是使用MapReduce配置Hive还是使用MapReduce配置HBase。Hive是一种批处理类型的客户机,通常在其中运行一批作业。
__28。你已经做完这个实验练习了。继续保存并关闭Eclipse和您可能打开的任何其他窗口。
5.3(可选)将HBase设置为MapReduce作业的sink,
在这个可选部分中,您将使用使用sales_fact表创建的源文件,而不是保存到文件中;您将创建并指定一个HBase表来保存输出。然后,您将能够通过扫描新表来验证输出。
__29。将 ProductAnalyzer_sink.java 类导入 Exercise 5 包。
__30。打开ProductAnalyzer_sink类
__31。我们需要做的第一件事是创建COLUMN_FAMILY和列常量。这已经为你做好了。
__32。接下来,我们保持map方法不变;这里没有任何变化,因为我们仍然使用原始的HBase sales_fact表作为源。
__33。还原法。您应该意识到的第一件事是,我们在这里扩展TableReducer类是为了使用HBase作为接收器。输出类是ImmutableBytesWritable,它将是我们的Put对象。创建键为rowkey 的Put对象:
Put put = new Put(Bytes.toBytes(key.toString()));
__34。将列族、列和计数值作为字符串添加到Put对象Put中。
put.add(COLUMN_FAMILY,COLUMN, Bytes.toBytes(count + “”));
__35。从reduce方法上下文中发出值。
context.write(null, put);
__36。下一节将创建表。表创建之后是HBase源的Scan实例的创建。我们在上一节中已经这样做了。在上一节中还设置了作业和源代码。
String sourceTable = args[0];
String targetTable = args[1];
__37。我们需要将sink设置为HBase表。为此,您需要使用TableMapReduceUtil.initTableReducerJob方法。
__a. TableMapReduceUtil.initTableReducerJob(targetTable, ProductReducer.class, job);
__38。现在,您已经准备好运行这个类了。使用两个参数创建一个运行配置:sales_fact和product_key_count作为源表和目标表。
__39。使用指定的参数运行该类:sales_fact和product_key_count。
__40。在程序成功执行之后,您将验证表是否已创建,以及结果是否已添加到表中。要快速完成此操作,请打开HBase Shell并首先键入list命令以查看表的列表。查找product_key_count表__a。
__a. list
__41。现在您已经验证了product_key_count表的存在。对表进行扫描,查看MapReduce作业的结果;
__a. scan ‘product_key_count’
__42。这就结束了关于如何使用HBase作为接收器的可选部分。
5.4总结
随着这项工作的完成,你有一个最重要的武库供你使用。MapReduce允许将复杂和大型作业分解成小块,可以由多台机器处理。结合HBase,您的作业的速度和性能现在非常适合处理BigData应用程序。