自动驾驶笔记(二)
15. 总结
感知的工作方式、感知的不同的方法和传感器
感知的主要任务,检测、分类、跟踪、分割——依赖于卷积神经网络
传感器信息融合
14. 感知融合策略
Apollo 使用激光雷达 和雷达 来检测障碍物。
用于融合输出的算法 主要是 卡尔曼滤波算法。
卡尔曼滤波算法 有两个步骤:
第一步:预测状态(predict state)
第二步:更新量测结果(update measurements)
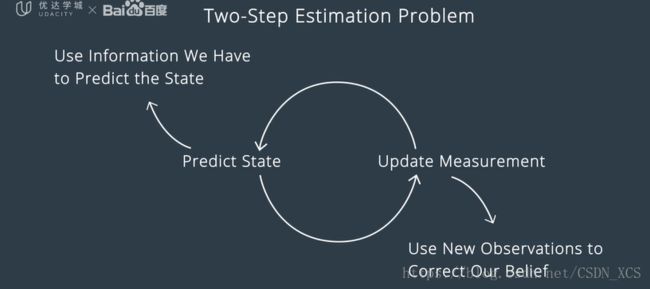
设想:我们在跟踪一名行人,此处的状态是行人的 位置和速度,
- 从已掌握的行人的状态开始,来执行 第一步,即预测未来时刻行人的状态;
- 下一步是误差结果更新,我们使用新的传感器值 修正我们认为的行人的状态
最后,无限循环。
实际上,有两种 量测结果更新的 方法:同步 和 异步
- 异步融合,逐个更新所收到的传感器测量结果(update at the time once they arrive)
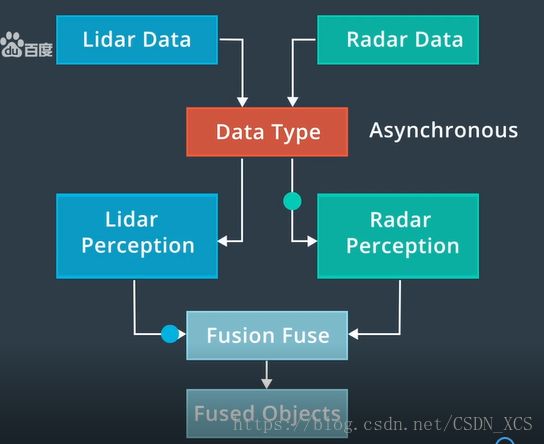
- 同步融合,同时更新来自不同传感器的测量结果。(all at the same time)

传感器融合可提高感知性能,因为各传感器相辅相成(complements each other)
融合也可以减小跟踪误差,所以我们可以更加确信对道路上其他物体位置的预测。
13. 传感器数据比较
感知 通常依赖于 摄像头、激光雷达和雷达
三种传感器的优缺点如下图所示:
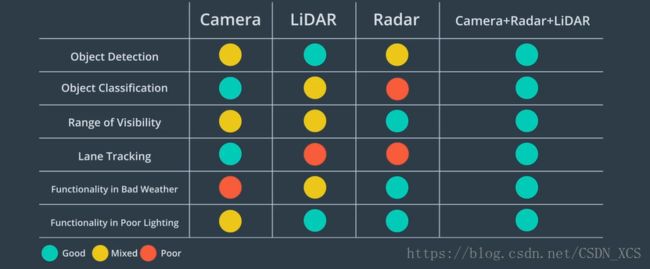
- 摄像头 非常适合用于 分类。
Apollo 主要用它做 交通信号灯分类 和 车道检测。
- 激光雷达 优势在于 障碍物检测,即使在夜间,没有自然光情况下。
- 雷达 优势在于 探测范围 和 应对恶劣天气方面。
通过融合三个传感器的数据,可以实现最佳聚合性能。
这被叫做 传感器融合
12. Apollo感知
The Apollo software stack (Apollo 开放式软件栈)可以 感知障碍物、交通信号灯和车道。
对于 三维对象 检测,Apollo 使用 感兴趣区域(ROI)来重点关注相关对象。 Apollo 把 ROI过滤器
应用于点云和图像数据,以缩小搜索范围,加快感知。
然后,向检测网络馈送 已经过滤过的点云,输出用于构建 围绕对象的三维边界框。

最后,我们使用 被称为检测跟踪关联的算法,来跨时间识别单个对象
该算法先保留每个时间步里要跟踪的对象列表,然后,在下一个时间步里找到最佳匹配。

对于 交通信号灯的分类:
- Apollo 先使用高精度地图 确定前方是否存在 信号灯,
如果前方有交通信号灯,高精度地图会返回灯的位置信息,而这就是摄像头的搜索范围。

- 在摄像头捕捉到交通信号灯图像之后,
Apollo 使用检测网络 对图像中灯的位置定位,
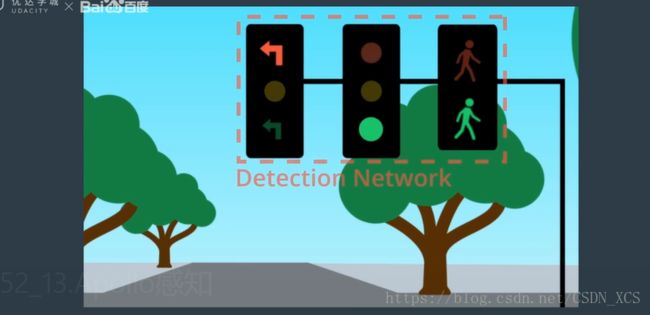
然后,Apollo 从较大的图像中 提取出 交通信号灯(裁剪),然后送给分类网络以确定颜色。
(如果这里有许多信号灯,则需要选择那个灯与 自己的车道相关)
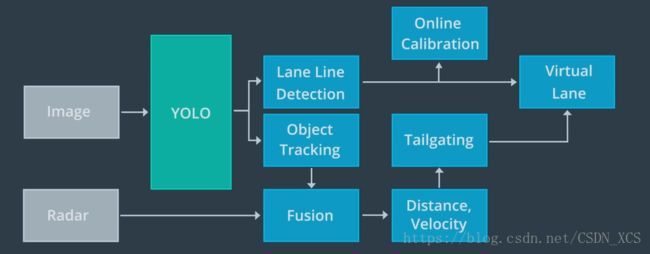
Apollo 使用 YOLO 网络来检测车道和动态物体,其中包括车辆、自行车、行人。
- 在经过 YOLO 网络的车道检测之后,在线检测模块会并入其他传感器的数据,
对车道线预测进行调整。(车道线最终被并入到 虚拟车道 的数据结构中去) - 类似地,也通过其他传感器的数据,对YOLO检测到的动态对象进行调整,
以获得每个对象的类型、类型、速度和前进方向
最终,虚拟车道 和 动态对象 均被传递到规划和控制模块。
11. 分割
语义分割 涉及对图像的每个像素进行分类。
它用于尽可能详细地了解环境,并确定车辆可驾驶区域(drivable area)。
语义分割 依赖于 一种特殊的 CNN—— 全卷积网络 FCN
(Fully Convolutional Network)

FCN 用 卷积层(Convolutional Layer) 来代替传统 CNN 体系结构末端的 平坦层。
现在,网络中的每一层都是卷积层,因此得名“全卷积网络”。
FCN 提供了 可在原始输入图像之上叠加的 逐像素输出。
我们必须考虑的一个复杂因素是 大小。
在典型的 CNN,经过多次卷积之后,所产生的输出图像 比原始输入图像小的多。
然而,为了分割图像,输出图像的尺寸必须与原始图像的尺寸 相匹配
为了达到这个目的,我们可以对 中间输出 进行上采样处理,直到大小相匹配。

网络的前半部分,通常被称为编码器,(这部分网络 对输入图像的特征进行了提取和编码);
网络的后半部分,通常被称为解码器,(对 这些特征进行了解码,并将其应用于输出)
10. 跟踪
What’s the point of tracking?
追踪的意义 是什么?
如果我们对 每一帧(Frame)中的 每个对象 进行检测,
并用 边界框 对每个对象进行标识,那么,跨帧 追踪对象会带来哪些好处呢?
首先,追踪在检测失败时,是至关重要的。
- 如果在运行检测算法时,对象被另一个对象遮挡(occlusion)一部分
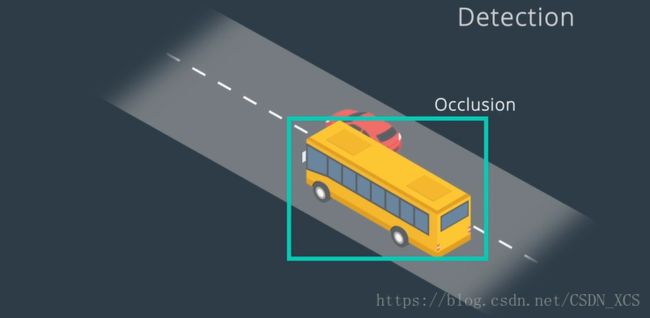
那么,检测算法有可能失败。
追踪 可以解决 遮挡问题。
另外,追踪 可以保留身份。
- 障碍物检测的输出 为 包含对象的边界框。
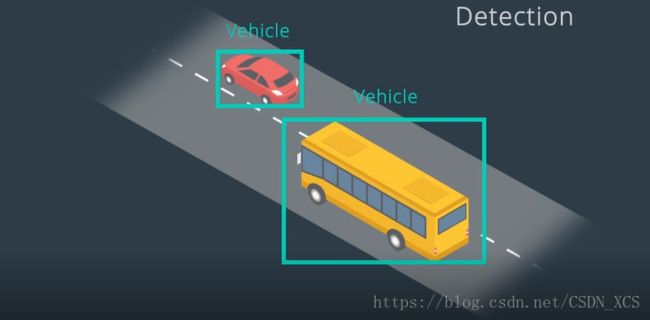
但是,对象 没有与 任何身份关联。
(即,单独使用 检测时,计算机并不知道,这一帧中的对象 和 下一帧中的那个对象对应!)
追踪的效果如下:
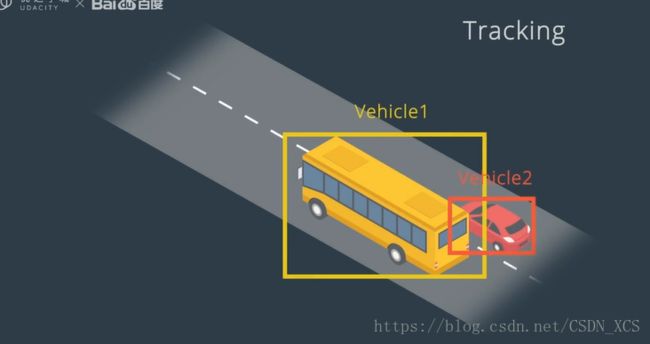

追踪(Tracking)
第一步为确定身份。
通过查找 特征相似度最高的 对象,我们将 在之前的帧中检测到的所有对象 与 当前帧中的各对象进行匹配。
We match all the objects detected in previous frame with objects detected in the current frame by finding objects with the highest feature similarity.
另外,也可以考虑 连续帧之中对象的位置和速度,(因为两个帧之间的位置和速度变化不大,该信息有助于快速找到匹配对象)对象具有很多特征,有些特征可能基于颜色,有些特征可能基于形状, 计算机视觉算法可以计算出复杂的图像特征,如:局部二值模式和方向梯度直方图
确认身份之后,我们可以使用对象的位置并结合预测算法,以估计下个时间(next time step)的位置和速度。
该预测 也帮助我们识别下一帧中的对象。
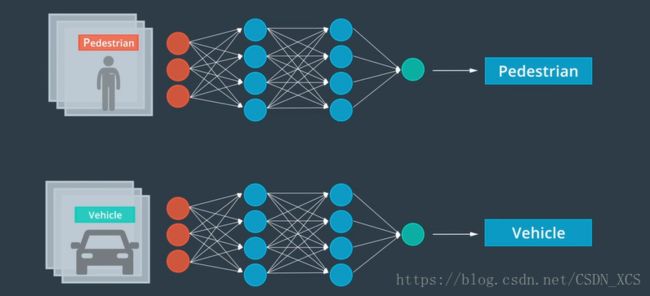
9. 检测 与 分类
在感知任务中,首先想到的就是 障碍物的检测和分类。
驾驶过程中的障碍物:
静态障碍物:墙壁、树木、杆子、墙壁;
动态障碍物:行人、自行车、其他车辆;
计算机 首先需要知道这些障碍物的位置,然后把他们分类。
另一个检测分类的例子:交通信号灯的检测分类
首先,我们使用计算机视觉 对 交通信号灯 进行定位,
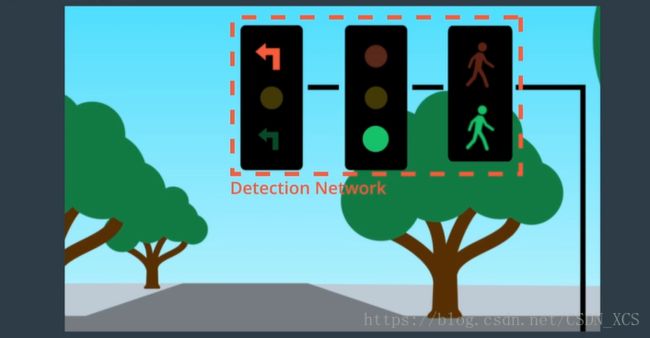
然后,我们可以根据灯光的颜色对 信号灯进行分类。
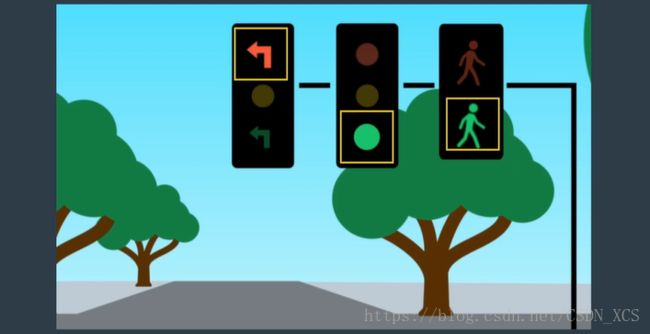
在无人驾驶中,我们使用什么算法 对障碍物进行检测和分类?
首先,我们使用 检测CNN查找图像中 对象的位置,
定位之后,我们可以将图像送给另外一个分类CNN 进行分类。或者,可以使用单一CNN体系结构 对对象进行检测分类
常用的做法是,在单一体系结构末端附加几个不同的“头”,
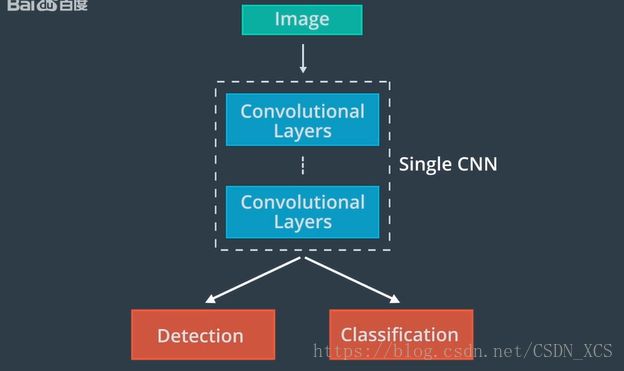
经典的体系结构为 R-CNN 及其变体 Fast R-CNN 和 Faster R-CNN
YOLO 和 SSD 是具有类似形式的不同体系结构。
8. 卷积神经网络(CNN)
Convolutional Neural Network
CNN 是一种人工神经网络,它对解决 感知问题 特别有效。
CNN 接受多维输入,包括 定义大多数传感器数据的 二维、三维形状。
例子:如解决 图像分类问题:
- 如果 使用标准神经网络解决:
则需要一种方法,将图像连接到网络的第一层(它是一维的)
常用的方法是,将图像矩阵重塑为一个矢量,并在一个大行中连接所有的列,
将图像展开为一维像素阵列。
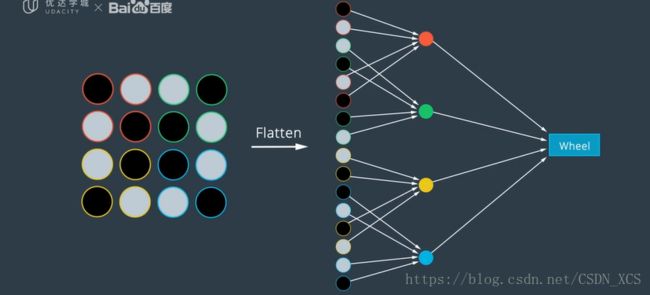
然而,这种方法打破了 图像所嵌入的空间信息。 - 如果 使用CNN解决:
CNN 通过持续输入像素之间的空间关系 解决上述问题。
具体讲,CNN 通过 过滤器连续滑过图像来收集信息,
每次收集信息时,只对整个图像的一小部分区域进行分析,这被称为卷积。

当 我们在整个图像上 对一个过滤器进行卷积时,
我们将该信息与下一个卷积层相关联。
例如:
CNN 可以识别第一个卷积层中的 基本边缘和颜色信息,
然后,通过在第一层上 卷积新过滤器,CNN 可以用 边缘和颜色信息来归纳更复杂的结构,如:车轮,车门,挡风玻璃;
而,另一个卷积 可以用这些车轮、车门、挡风玻璃识别整个车辆!
最后,神经网络可以使用 这个高阶信息 进行分类。

人们通常不理解 CNN怎样解读图像,
有时,CNN 关注的部分让人们惊讶,但这也是深度学习神奇的地方,
CNN 根据任务,查找真正所需要的特征。
任务 可能是 检测、分类、分割或其他的目标。
7. 反向传播算法(Backward Propagation)
我们已经讨论了,神经网络如何从数据中“学习”。(有时也被叫做 训练)
那么 这种学习是怎样发生的呢?
它由三步循环组成:
- 前馈(Feed Forward)
最初,随机分配初始权重,(即人工神经元的值)
然后,通过神经网络来馈送每个图像,产生输出
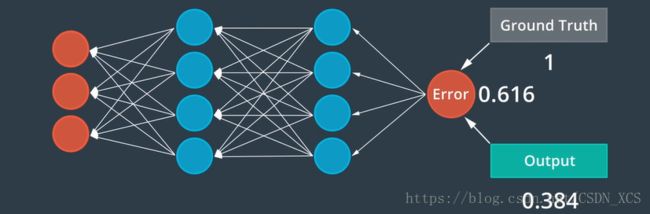
- 误差测定
误差是 前馈过程产生的输出 与 真实值之间的偏差

- 反向传播
我们将误差反向发送,使其通过神经网络,(像前馈过程,只是方向相反)
每个神经元 对其值进行 微调,所有这些独立调整的结果可以产生更准确的网络。
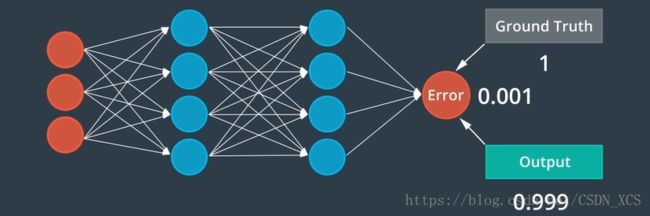
为了训练这个网络,我们需要数千个这样的周期,
训练的最终结果应该是,模型能够根据新数据做出准确的预测(判断)。
6. 神经网络(Neural Networks)
人工神经网络(Artificial Neural Networks)是 受到构成人类神经系统的生物神经元的启发 产生的,(也可以用于无人驾驶车)。
生物神经元 通过相互连接构成了 神经系统或神经网络;
类似地,我们可以将 人工神经网络连接起来,来创建 用于机器学习的 人工神经网络。
人工神经网络,是一种工具,一种通过数据 来学习复杂模型的 工具。
Artificial Neural Networks is a tool to learn complex pattern by data.
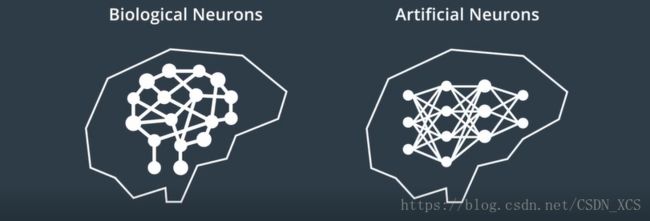
像 生物神经网络一样,
人工神经网络 由大量的神经元组成,且 其中的神经元负责传递和处理信息。
这些神经元 也可以 被训练。
仔细想想,你可能不知道自己如何知道它们是车辆,
也许是 它们的某些特征 触发了你的反应。
人工神经网络 具有类似的工作方式。
通过密集训练,计算机可以辨别车辆、行人、电线杆等,
我们并不总是理解,它们如何做出这些辨别,
但它们学习了(学懂了)用于执行任务的数学模型,只是我们可能很难直观地去理解该数学模型。


类似地,人工神经网络会从图片中提取许多特征,
但是这些特征 可能是我们人类无法描述或无法理解的特征!

但是,我们不需要理解,计算机会自动调整这些特征的权重,以完成神经网络的最终任务。
![]()
这就是深层神经网络的思维方式。
5. 机器学习(Machine Learning)
机器学习是 使用特殊算法训练 计算机 从数据中学习 的 计算机科学领域。
机器学习 诞生于 20世纪 60年代,
但随着 计算机硬件的改进,在过去的 20年中,才真正越来越受欢迎。
机器学习的应用:
- - 金融公司:对汇率和证券交易 进行预测;
- - 零售企业:预测需求;
- - 医生:辅助医疗诊断。

机器学习是 使用特殊算法训练 计算机 从数据中学习 的 计算机科学领域。
1- 通常,这种 学习 的结果 存放在 一种被称为 模型(Model) 的数据结构中,
有很多种模型。(事实上,模型 只是一种可用于理解和预测世界的数据结构)
2- 机器学习 涉及使用数据和相关的真值标记 来进行模型 训练,
- 监督式学习(Supervised Learning)(模型利用了人类创造的真实标记)
例如:显示车辆和行人的计算机图像 并告诉计算机各图像对应的标签,
我会让计算机 学习 如何最好地区分两类图像。

- 无监督式(Unsupervised Learning)
想象一个类似的学习过程,但这次使用的是没有 真值标记的车辆与行人图像,
在这种方法中,我们让计算机自行决定哪些图像是类似的,哪些图像是不同的,
- 半监督式学习(Semi-supervised Learning)
它将 监督式学习 和 半监督式学习的特点结合到一起;
该方法使用 少量的标记数据 和 大量的未标记数据来训练模型。 - 强化学习(Reinforcement Learning)
是 另外一种机器学习,
它允许模型 尝试许多不同的方法来 解决问题,
然后,衡量哪种方法最成功,并给予奖励。
(即,计算机将尝试很多种方法,最终使方法和环境相适应)
例如:训练无人驾驶车 右转:

4. 激光雷达(LiDAR)图像
激光雷达传感器 创建 环境的点云表征,提供 摄像头图像难以获得的信息——如距离和高度;
激光雷达传感器 使用光线(尤其是 激光)来测量距离,
测量,激光雷达传感器 与 环境中反射该光线的物体之间 距离;
激光雷达 发射脉冲,并测量物体 将每个激光脉冲反射回传感器所花费的时间。
反射需要的时间越长,物体离传感器越远,
激光雷达 通过这种方式 构建周围时间的视觉表征:
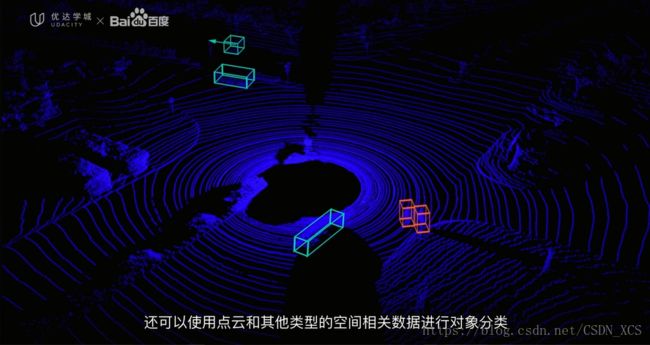
由 激光雷达之输出 获得的可视化图像
图像解读:
激光雷达 通过发射光脉冲来检测周围的环境,
中间的 黑色区域 表示 无人驾驶车本身;
蓝色点 表示 (反射 激光脉冲的)物体,(由于激光雷达测量激光束反射,它收集的数据形成一团点 或 点云;点云中的每个点,代表反射回传感器的激光束);
点云 可以告诉我们 关于该物体的许多信息——例如,它的形状、纹理;
通过 对点进行聚类和分析,
这些数据 提供了足够的对象检测、跟踪或分类信息(detect, track or classify an object)
上图中,标注出了 对点云执行检测、分类后的结果:
图像解读:
红点:为行人;
绿点:表示其他汽车;
因此,激光雷达 提供了充足的 用于构建世界视觉表征的 空间信息。
LiDAR provides enough spacial information to creat a visual repretation of the world.
计算机视觉技术 不仅可以使用摄像头图像进行对象分类,
还可以使用点云和其他类型的空间相关数据 进行对象分类。
3. 摄像头图像
摄像头图像(Camera Images)是 最常见的计算机视觉数据;
计算机 如何确定出 给的图片是一辆汽车的图像?

从计算机的角度,图像只是一个二维网格——矩阵(Matrix),
数字图像 全部由像素组成,
图像中的每个像素 只是一个数值,这些值构成了我们的 图像矩阵。
我们可以改变这些值:
给每个元素加上一个标量整数——改变图像亮度;
向右移动每一个数值——平移图像;
等等
这些数字网格,是许多图像处理技术的基础;
多数颜色和形状的转换只是通过 对图像进行数学运算以及逐一像素更改 完成的。
例子:
将 图像 分解为 二维灰度像素值网格

彩色图像 (三维立方体)深度为颜色通道数(例如 RGB图像——薄立方体,3层二维)

2. 计算机视觉
作为人类,我们可以自动识别 图像中的物体,甚至能推断 这些物体之间的关系。
但是,对于电脑而言,图像只是红色、绿色、蓝色值的集合;
如何 把这些值 解读为 有意义的图像内容?(It’s not obvious)
Self-Driving cars have four core task in the percevice world.
在感知方面,无人驾驶车 有四个核心任务:
- 检测:找到物体在环境中的位置;
- 分类:明确对象是什么;
- 跟踪:指随时间的推移,观察移动物体(如,其他车辆、自行车、行人);
- 语义分割:将图像中的每个像素与语义类别进行匹配(道路、汽车、天空);

我们 可以将分类作为 研究计算机视觉一般数据流程的例子:
We can use classification as an example to study the general data pipeline for computer vision.
图像分类器
是一种 将图像作为输入,并输出标识该图像的标签或“类别”的算法。
例如:
交通标志分类器:查看一个停车标志 并 识别它是停车标志,还是让路标志、限速标志或其他类型的标志。

再例如:
分类器 甚至可以识别行为:
一个人是在 走路?还是在跑步?
有许多种分类器,但它们都包含一系列类似的操作:
- 计算机 接收 类似摄像头等成像设备 的输入(图像或一系列图像);
- 将它们送去 预处理(将图像标准化:调整大小、旋转、全彩转换为灰度图);
【可以帮助模型加快处理速度】 - 提取特征(Extract Features)
【特征帮助计算机理解图像】 - 将特征输入到 分类模型中;(确定是否存在)
【使用特征来选择图像类别】

为了完成这些 视觉任务,我们需要建立模型;
模型 是帮助计算机了解图像内容的工具。
在计算机视觉中,不论 使用训练的模型去 执行什么任务,
它们通常在开始时将 摄像头图像(Cameral Imagines) 作为输入。
1. 感知
我们的 目标是教会车辆 如何drive themselves.
为此,我们需要教汽车如何感知 周围环境。
我们开车时,我们用眼睛 判断速度、车道位置、转弯位置;
无人驾驶车 的眼睛 是静态摄像头和其他传感器,
这里我们需要使用 大量的 计算机视觉技术;
计算机视觉,是指 计算机看待和理解 世界的方式;
现今,最广泛使用的方法是 卷积神经网络(CNN Convolutional neural network)
接下来,首先介绍计算机视觉的基本应用领域,
然后,介绍机器学习、神经网络和卷积神经网络的基础知识;
再讨论 感知模块 在无人驾驶车中的具体任务;
最后,介绍Apollo 感知模块的体系结构 和 传感器融合的相关主题;
摄像头:前方有什么障碍物
雷达、激光雷达(测量原始距离):这个障碍物距离我们多少厘米;
无人驾驶车的核心竞争力——利用海量的传感器数据,模仿人脑来理解这个世界。
当谈到传感器,也会谈到神经网络、深度学习和人工智能。