python基础二
前面我们介绍了python中的数字和字符串类型,下面接着介绍python中的其它数据类型和基本语法。
1,灵活多变的存储—列表
创建列表:[元素1,元素2…..],列表中可存储函数和类
对列表的操作与字符串类似

为什么说列表是灵活多变的呢?
我们先来看对字符串中一个元素的改变,对它在内存中的地址有什么影响。

可以看出,对字符串中某个元素的改变会导致整个字符串的地址发生改变。那么,如果在列表中呢?

在列表中,对列表某个元素的改变实际上只改变了这个元素的地址,而整个列表的地址并没有改变。
列表方法:
这里需要注意的是extend与append的区别,extend是把列表中的元素一个一个添加到列表中,而append是将一个列表整体添加进去。二维列表和二维数组的操作类似。

2,不可变的元组
元组就没有列表那样灵活多变了。
创建元组:(元素1,元素2,…)
元组的拆分:x,y = (value1,value2),必须要一一对应。

3,列表解析和生成表达式
在解释列表解析之前,我们先来看一道题:
如果我们列出小于10,并且是3或5的倍数的所有自然数,它是3,5,6,9,计算它们的和是3+5+6+9 = 23,现找出小于100并且是3或5的倍数的所有自然数并计算它们的和。


在需要改变列表而不是需要新建列表时,可以使用列表解析。
列表解析表达式为:
[expr for iter_var in iterable]
//expr是一个表达式,遍历序列中的每一个元素去执行这个表达式
[expr for iter_var in iterable if cond_expr]
//满足if后面条件的元素去执行表达式
下面我们用列表解析表达式来解决一开始那道题:
![]()
生成器表达式:
生成器表达式的结构和列表解析相同。不过就是把[]改成了(),但生成器表达式返回的是一个生成器对象,不会占用太多内存空间。
(expr for iter_var in iterable)
//expr是一个表达式,遍历序列中的每一个元素去执行这个表达式
(expr for iter_var in iterable if cond_expr)
//满足if后面条件的元素去执行表达式
生成器表达式并不真正创建数字列表,而是返回一个生成器,这个生成器在每次计算出一个条目后,把这个条目“产生”出来,生成器表达式使用了“惰性计算”,只有在检索时才被赋值,所以在列表比较长的情况下使用内存上更有效。
建议:
(1)当需要只是执行一个循环的时候尽量使用循环而不是列表解析,这样更符合python提倡的直观性。
for item in sequence
process(item)(2)当有内建的操作或者类型能够以更直接的方式实现的,不要用列表解析。
比如,复制一个链表时,使用L1 = list(L)即可,不必使用:L1 = [x for x in L]
(3)如果需要对每个元素读调用,并且返回结果时,应使用L1 = map(f,L);而不是L1=[f(x) for x in L]
字典类型
字典是除列表以外python中最灵活的内置结构类型。
区别与其它类型的是,字典中的元素是通过键来存取,而不是通过偏移。
字典创建:dict1 = {‘key’:value,’key’:value}

字典属性:
(1)通过键而不是偏移量来读取
(2)任意对象引用的集合
(3)可变,异构,任意嵌套
(4)属于可变映射类型
(5)对象引用表(哈希表—支持快速检索的数据结构)
字典访问:
(1)通过key访问value
(2)单个访问dict[‘key’]
(3)遍历
for key in dict:
print('key = %s,value = %s' % (key,dict[key]))(4)方法 ‘key’ in dict 或dict.has_key(‘key’)
字典更新:采用覆盖更新

删除字典和字典元素:
(1)del dict2[‘name’] 删除键为name的所有条目
(2)dict2.clear() 删除dict2中的所有条目
(3)del dict2 删除整个dict2字典
(4)dict2.pop(‘name’) 删除并返回键为name的条目
(5)d1 = dict2.items() 返回素有的键值对
运用字典写一个简单的四则运算器:

集合类型
可变集合:set(iterable)
特点:无须排序且不重复,是可变的
功能:关系测试和消除重复元素
不可变集合:frozenset(iterable)
特点:冻结的集合,不可变
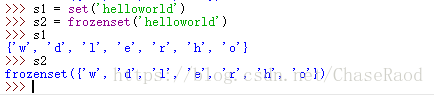
集合的部分方法:

交集、合集和差集
交集:&
合集:|
差集:-
