
Cendertron,安全爬虫的分布式与稳定性优化之路
Cendertron 是基于 Puppeteer 的 Web 2.0 动态爬虫与敏感信息泄露检测工具,其为 Chaos-Scanner 后续的基础扫描与 POC 扫描提供的扫描的 URL 目标。我们前文介绍了 Cendertron 的基础使用,这里我们针对实际扫描场景下的爬虫参数设计与集群架构进行简要描述。不得不说,再优雅的设计也需要经过大量的数据实践与经验沉淀,与前一个版本的 Cendertron 相比,更多的是来自于细节的适配。
基于 Docker Swarm 的弹性化集群部署
在 Docker 实战系列中,我们详细介绍了 Docker 及 Docker Swarm 的概念与配置、这里我们也是使用 Docker 提供的 Route Mesh 机制,将多个节点以相同端口暴露出去,这也就要求我们将各个爬虫节点的部分状态集中化存储,这里以 Redis 为中心化存储。
实际上,Chaos Scanner 中的 POC 节点与爬虫节点都遵循该调度方式,不过 POC 扫描节点主要是依赖于 RabbitMQ 进行任务分发:
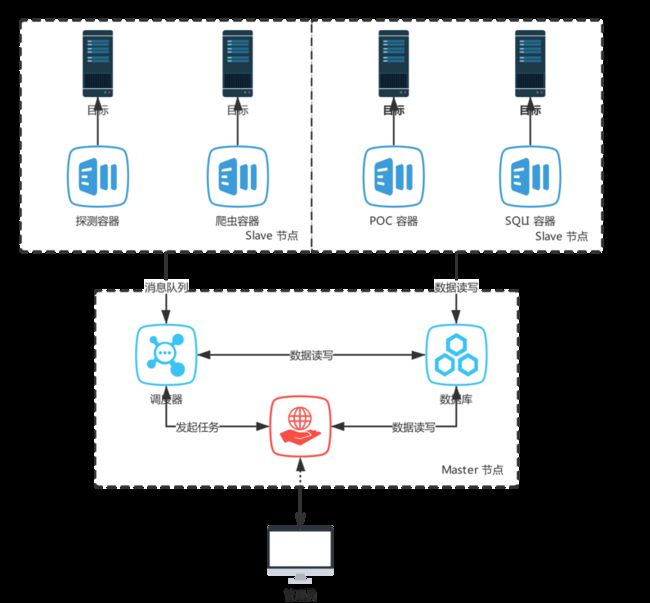
整体爬虫在扫描调度中的逻辑流如下:
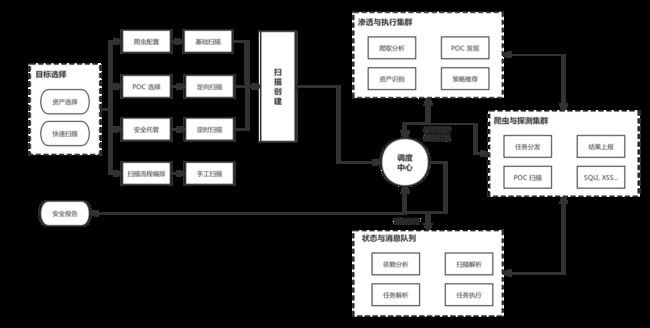
这里我们可以基于基础镜像编辑 Compose 文件,即 docker-compose.yml:
version: '3'
services:
crawlers:
image: cendertron
ports:
- '${CENDERTRON_PORT}:3000'
deploy:
replicas: 2
volumes:
- wsat_etc:/etc/wsat
volumes:
wsat_etc:
driver: local
driver_opts:
o: bind
type: none
device: /etc/wsat/这里我们将 Redis 的配置以卷方式挂载进容器,在 Chaos Scanner 好,不同设备的统一注册中心即简化为了这个统一的配置文件:
{
"db": {
"redis": {
"host": "x.x.x.x",
"port": 6379,
"password": "xx-xx-xx-xx"
}
}
}Redis 配置完毕之后,我们可以通过如下的命令创建服务:
# 创建服务
> docker stack deploy wsat --compose-file docker-compose.yml --resolve-image=changed
# 指定实例
> docker service scale wsat_crawlers=5这里我们提供了同时扫描多个目标的创建方式,不同的 URL 之间以 | 作为分隔符:
POST /scrape
{
"urls":"http://baidu.com|http://google.com"
}在集群运行之后,通过 ctop 命令我们能看到单机上启动的容器状态:

使用 htop 命令可以发现整个系统的 CPU 调用非常饱满:

面向失败的设计与监控优先
在测试与高可用保障系列文章中,我们特地讨论过在高可用架构设计中的面向失败的设计原则:
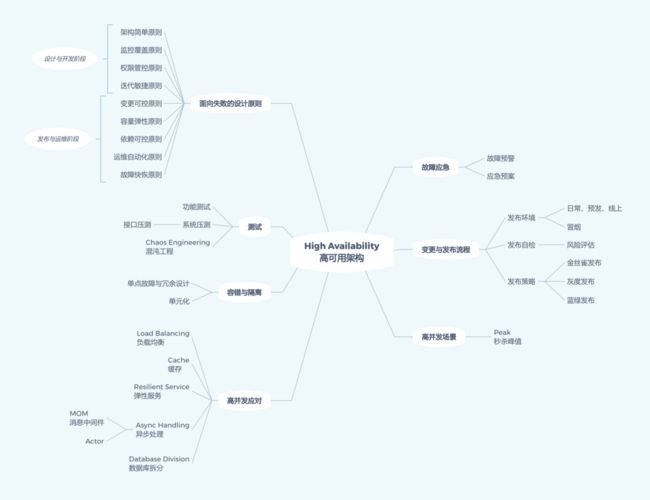
这些原则中极重要的一条就是监控覆盖原则,我们在设计阶段,就假设线上系统会出问题,从而在管控系统添加相应措施来防止一旦系统出现某种情况,可以及时补救。而在爬虫这样业务场景多样性的情况下,我们更是需要能够及时审视系统的现状,以随时了解当前策略、参数的不恰当的地方。
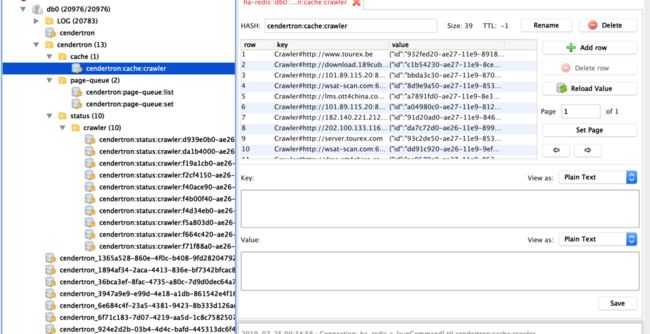
在集群背景下,爬虫的状态信息是存放在了 Redis 中,每个爬虫会定期上报。上报的爬虫信息会自动 Expire,如果查看系统当前状态时,发现某个节点的状态信息不存在,即表示该爬虫在本事件窗口内已经假死:
我们依然通过 GET /_ah/health 端口来查看整个系统的状态,如下所示:
{
"success": true,
"mode": "cluster",
"schedulers": [
{
"id": "a8621dc0-afb3-11e9-94e5-710fb88b1291",
"browserStatus": [
{
"targetsCnt": 4,
"useCount": 153,
"urls": [
{
"url": ""
},
{
"url": "about:blank"
},
{
"url": ""
},
{
"url": "http://180.100.134.161:8091/xygjitv-web/#/enter_index_db/film"
}
]
}
],
"runingCrawlers": [
{
"id": "dabd6260-b216-11e9-94e5-710fb88b1291",
"entryPage": "http://180.100.134.161:8091/xygjitv-web/",
"progress": "0.44",
"startedAt": 1564414684039,
"option": {
"depth": 4,
"maxPageCount": 500,
"timeout": 1200000,
"navigationTimeout": 30000,
"pageTimeout": 60000,
"isSameOrigin": true,
"isIgnoreAssets": true,
"isMobile": false,
"ignoredRegex": ".*logout.*",
"useCache": true,
"useWeakfile": false,
"useClickMonkey": false,
"cookies": [
{
"name": "PHPSESSID",
"value": "fbk4vjki3qldv1os2v9m8d2nc4",
"domain": "180.100.134.161:8091"
},
{
"name": "security",
"value": "low",
"domain": "180.100.134.161:8091"
}
]
},
"spiders": [
{
"url": "http://180.100.134.161:8091/xygjitv-web/",
"type": "page",
"option": {
"allowRedirect": false,
"depth": 1
},
"isClosed": true,
"currentStep": "Finished"
}
]
}
],
"localRunningCrawlerCount": 1,
"localFinishedCrawlerCount": 96,
"reportTime": "2019-7-29 23:38:34"
}
],
"cache": ["Crawler#http://baidu.com"],
"pageQueueLen": 31
}参数调优
因为网络震荡等诸多原因,Cendertron 很难保障绝对的稳定性与一致性,更多的也还是在效率与性能之间的权衡。最后我们还是再列举下目前 Cendertron 内置的参数配置,在 src/config.ts 中包含了所有的配置:
export interface ScheduleOption {
// 并发爬虫数
maxConcurrentCrawler: number;
}
export const defaultScheduleOption: ScheduleOption = {
maxConcurrentCrawler: 1
};
export const defaultCrawlerOption: CrawlerOption = {
// 爬取深度
depth: 4,
// 单爬虫最多爬取页面数
maxPageCount: 500,
// 默认超时为 20 分钟
timeout: 20 * 60 * 1000,
// 跳转超时为 30s
navigationTimeout: 30 * 1000,
// 单页超时为 60s
pageTimeout: 60 * 1000,
isSameOrigin: true,
isIgnoreAssets: true,
isMobile: false,
ignoredRegex: '.*logout.*',
// 是否使用缓存
useCache: true,
// 是否进行敏感文件扫描
useWeakfile: false,
// 是否使用模拟操作
useClickMonkey: false
};
export const defaultPuppeteerPoolConfig = {
max: 1, // default
min: 1, // default
// how long a resource can stay idle in pool before being removed
idleTimeoutMillis: Number.MAX_VALUE, // default.
// maximum number of times an individual resource can be reused before being destroyed; set to 0 to disable
acquireTimeoutMillis: defaultCrawlerOption.pageTimeout * 2,
maxUses: 0, // default
// function to validate an instance prior to use; see https://github.com/coopernurse/node-pool#createpool
validator: () => Promise.resolve(true), // defaults to always resolving true
// validate resource before borrowing; required for `maxUses and `validator`
testOnBorrow: true // default
// For all opts, see opts at https://github.com/coopernurse/node-pool#createpool
};延伸阅读
您可以通过以下任一方式阅读笔者的系列文章,涵盖了技术资料归纳、编程语言与理论、Web 与大前端、服务端开发与基础架构、云计算与大数据、数据科学与人工智能、产品设计等多个领域:
- 在 Gitbook 中在线浏览,每个系列对应各自的 Gitbook 仓库。
| Awesome Lists | Awesome CheatSheets | Awesome Interviews | Awesome RoadMaps | Awesome-CS-Books-Warehouse |
|---|
| 编程语言理论 | Java 实战 | JavaScript 实战 | Go 实战 | Python 实战 | Rust 实战 |
|---|
| 软件工程、数据结构与算法、设计模式、软件架构 | 现代 Web 开发基础与工程实践 | 大前端混合开发与数据可视化 | 服务端开发实践与工程架构 | 分布式基础架构 | 数据科学,人工智能与深度学习 | 产品设计与用户体验 |
|---|