先看一段synchronized 的详解:
synchronized 是 java语言的关键字,当它用来修饰一个方法或者一个代码块的时候,能够保证在同一时刻最多只有一个线程执行该段代码。
一、当两个并发线程访问同一个对象object中的这个synchronized(this)同步代码块时,一个时间内只能有一个线程得到执行。另一个线程必须等待当前线程执行完这个代码块以后才能执行该代码块。
二、然而,当一个线程访问object的一个synchronized(this)同步代码块时,另一个线程仍然可以访问该object中的非synchronized(this)同步代码块。
三、尤其关键的是,当一个线程访问object的一个synchronized(this)同步代码块时,其他线程对object中所有其它synchronized(this)同步代码块的访问将被阻塞。
四、第三个例子同样适用其它同步代码块。也就是说,当一个线程访问object的一个synchronized(this)同步代码块时,它就获得了这个object的对象锁。结果,其它线程对该object对象所有同步代码部分的访问都被暂时阻塞。
五、以上规则对其它对象锁同样适用.
简单来说, synchronized就是为当前的线程声明一个锁, 拥有这个锁的线程可以执行区块里面的指令, 其他的线程只能等待获取锁, 然后才能相同的操作.
这个很好用, 但是笔者遇到另一种比较奇葩的情况.
1. 在同一类中, 有两个方法是用了synchronized关键字声明
2. 在执行完其中一个方法的时候, 需要等待另一个方法(异步线程回调)也执行完, 所以用了一个countDownLatch来做等待
3. 代码解构如下:
synchronized void a(){
countDownLatch = new CountDownLatch(1);
// do someing
countDownLatch.await();
}
synchronized void b(){
countDownLatch.countDown();
}
其中
a方法由主线程执行, b方法由异步线程执行后回调
执行结果是:
主线程执行 a方法后开始卡住, 不再往下做, 任你等多久都没用.
这是一个很经典的死锁问题
a等待b执行, 其实不要看b是回调的, b也在等待a执行. 为什么呢? synchronized 起了作用.
一般来说, 我们要synchronized一段代码块的时候, 我们需要使用一个共享变量来锁住, 比如:
byte[] mutex = new byte[0];
void a1(){
synchronized(mutex){
//dosomething
}
}
void b1(){
synchronized(mutex){
// dosomething
}
}
如果把a方法和b方法的内容分别迁移到 a1和b1 方法的synchronized块里面, 就很好理解了.
a1执行完后会间接等待(countDownLatch)b1方法执行.
然而由于 a1 中的mutex并没有释放, 就开始等待b1了, 这时候, 即使是异步的回调b1方法, 由于需要等待mutex释放锁, 所以b方法并不会执行.
于是就引起了死锁!
而这里的synchronized关键字放在方法前面, 起的作用就是一样的. 只是java语言帮你隐去了mutex的声明和使用而已. 同一个对象中的synchronized 方法用到的mutex是相同的, 所以即使是异步回调, 也会引起死锁, 所以要注意这个问题. 这种级别的错误是属于synchronized关键字使用不当. 不要乱用, 而且要用对.
那么这样的 隐形的mutex 对象究竟是 什么呢?
很容易想到的就是 实例本身. 因为这样就不用去定义新的对象了做锁了. 为了证明这个设想, 可以写一段程序来证明.
思路很简单, 定义一个类, 有两个方法, 一个方法声明为 synchronized, 一个在 方法体里面使用synchronized(this), 然后启动两个线程, 来分别调用这两个方法, 如果两个方法之间发生锁竞争(等待)的话, 就可以说明 方法声明的 synchronized 中的隐形的mutex其实就是 实例本身了.
public class MultiThreadSync {
public synchronized void m1() throws InterruptedException{
System. out.println("m1 call" );
Thread. sleep(2000);
System. out.println("m1 call done" );
}
public void m2() throws InterruptedException{
synchronized (this ) {
System. out.println("m2 call" );
Thread. sleep(2000);
System. out.println("m2 call done" );
}
}
public static void main(String[] args) {
final MultiThreadSync thisObj = new MultiThreadSync();
Thread t1 = new Thread(){
@Override
public void run() {
try {
thisObj.m1();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
Thread t2 = new Thread(){
@Override
public void run() {
try {
thisObj.m2();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
t1.start();
t2.start();
}
}
结果输出是:
m1 call m1 call done m2 call m2 call done
说明方法m2的sync块等待了m1的执行. 这样就可以证实 上面的设想了.
另外需要说明的是, 当sync加在 static的方法上的时候, 由于是类级别的方法, 所以锁住的对象是当前类的class实例. 同样也可以写程序进行证明.这里略.
所以方法的synchronized 关键字, 在阅读的时候可以自动替换为synchronized(this){}就很好理解了.
void method(){
void synchronized method(){ synchronized(this){
// biz code // biz code
} ------>>> }
}
由Synchronized的内存可见性说开去
在Java中,我们都知道关键字synchronized可以用于实现线程间的互斥,但我们却常常忘记了它还有另外一个作用,那就是确保变量在内存的可见性 - 即当读写两个线程同时访问同一个变量时,synchronized用于确保写线程更新变量后,读线程再访问该 变量时可以读取到该变量最新的值。
比如说下面的例子:
public class NoVisibility {
private static boolean ready = false;
private static int number = 0;
private static class ReaderThread extends Thread {
@Override
public void run() {
while (!ready) {
Thread.yield(); //交出CPU让其它线程工作
}
System.out.println(number);
}
}
public static void main(String[] args) {
new ReaderThread().start();
number = 42;
ready = true;
}
}
你认为读线程会输出什么? 42? 在正常情况下是会输出42. 但是由于重排序问题,读线程还有可能会输出0 或者什么都不输出。
我们知道,编译器在将Java代码编译成字节码的时候可能会对代码进行重排序,而CPU在执行机器指令的时候也可能会对其指令进行重排序,只要重排序不会破坏程序的语义 -
在单一线程中,只要重排序不会影响到程序的执行结果,那么就不能保证其中的操作一定按照程序写定的顺序执行,即使重排序可能会对其它线程产生明显的影响。
这也就是说,语句"ready=true"的执行有可能要优先于语句"number=42"的执行,这种情况下,读线程就有可能会输出number的默认值0.
而在Java内存模型下,重排序问题是会导致这样的内存的可见性问题的。在Java内存模型下,每个线程都有它自己的工作内存(主要是CPU的cache或寄存器),它对变量的操作都在自己的工作内存中进行,而线程之间的通信则是通过主存和线程的工作内存之间的同步来实现的。
比如说,对于上面的例子而言,写线程已经成功的将number更新为42,ready更新为true了,但是很有可能写线程只同步了number到主存中(可能是由于CPU的写缓冲导致),导致后续的读线程读取的ready值一直为false,那么上面的代码就不会输出任何数值。
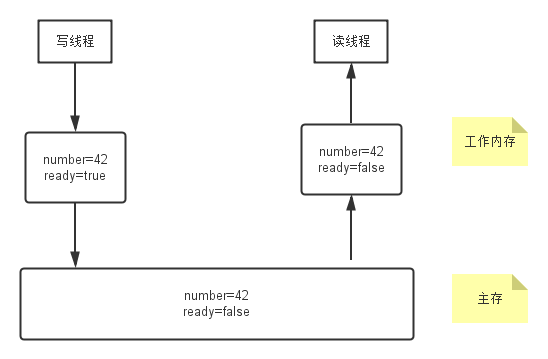
而如果我们使用了synchronized关键字来进行同步,则不会存在这样的问题,
public class NoVisibility {
private static boolean ready = false;
private static int number = 0;
private static Object lock = new Object();
private static class ReaderThread extends Thread {
@Override
public void run() {
synchronized (lock) {
while (!ready) {
Thread.yield();
}
System.out.println(number);
}
}
}
public static void main(String[] args) {
synchronized (lock) {
new ReaderThread().start();
number = 42;
ready = true;
}
}
}
这个是因为Java内存模型对synchronized语义做了以下的保证,
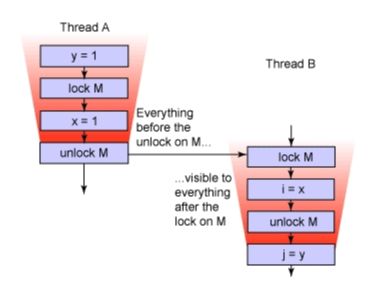
即当ThreadA释放锁M时,它所写过的变量(比如,x和y,存在它工作内存中的)都会同步到主存中,而当ThreadB在申请同一个锁M时,ThreadB的工作内存会被设置为无效,然后ThreadB会重新从主存中加载它要访问的变量到它的工作内存中(这时x=1,y=1,是ThreadA中修改过的最新的值)。通过这样的方式来实现ThreadA到ThreadB的线程间的通信。
这实际上是JSR133定义的其中一条happen-before规则。JSR133给Java内存模型定义以下一组happen-before规则,
- 单线程规则:同一个线程中的每个操作都happens-before于出现在其后的任何一个操作。
- 对一个监视器的解锁操作happens-before于每一个后续对同一个监视器的加锁操作。
- 对volatile字段的写入操作happens-before于每一个后续的对同一个volatile字段的读操作。
- Thread.start()的调用操作会happens-before于启动线程里面的操作。
- 一个线程中的所有操作都happens-before于其他线程成功返回在该线程上的join()调用后的所有操作。
- 一个对象构造函数的结束操作happens-before与该对象的finalizer的开始操作。
- 传递性规则:如果A操作happens-before于B操作,而B操作happens-before与C操作,那么A动作happens-before于C操作。
实际上这组happens-before规则定义了操作之间的内存可见性,如果A操作happens-before B操作,那么A操作的执行结果(比如对变量的写入)必定在执行B操作时可见。
为了更加深入的了解这些happens-before规则,我们来看一个例子:
//线程A,B共同访问的代码
Object lock = new Object();
int a=0;
int b=0;
int c=0;
//线程A,调用如下代码
synchronized(lock){
a=1; //1
b=2; //2
} //3
c=3; //4
//线程B,调用如下代码
synchronized(lock){ //5
System.out.println(a); //6
System.out.println(b); //7
System.out.println(c); //8
}
我们假设线程A先运行,分别给a,b,c三个变量进行赋值(注:变量a,b的赋值是在同步语句块中进行的),然后线程B再运行,分别读取出这三个变量的值并打印出来。那么线程B打印出来的变量a,b,c的值分别是多少?
根据单线程规则,在A线程的执行中,我们可以得出1操作happens before于2操作,2操作happens before于3操作,3操作happens before于4操作。同理,在B线程的执行中,5操作happens before于6操作,6操作happens before于7操作,7操作happens before于8操作。而根据监视器的解锁和加锁原则,3操作(解锁操作)是happens before 5操作的(加锁操作),再根据传递性 规则我们可以得出,操作1,2是happens before 操作6,7,8的。
则根据happens-before的内存语义,操作1,2的执行结果对于操作6,7,8是可见的,那么线程B里,打印的a,b肯定是1和2. 而对于变量c的操作4,和操作8. 我们并不能根据现有的happens before规则推出操作4 happens before于操作8. 所以在线程B中,访问的到c变量有可能还是0,而不是3.