近年来,SLAM技术取得了惊人的发展,领先一步的激光SLAM已成熟的应用于各大场景中,视觉SLAM虽在落地应用上不及激光SLAM,但也是目前研究的一大热点,今天我们就来详细聊聊视觉SLAM的那些事儿。
视觉SLAM是什么?
视觉SLAM主要是基于相机来完成环境的感知工作,相对而言,相机成本较低,容易放到商品硬件上,且图像信息丰富,因此视觉SLAM也备受关注。
目前,视觉SLAM可分为单目、双目(多目)、RGBD这三类,另还有鱼眼、全景等特殊相机,但目前在研究和产品中还属于少数,此外,结合惯性测量器件(Inertial Measurement Unit,IMU)的视觉SLAM也是现在研究热点之一。从实现难度上来说,大致将这三类方法排序为:单目视觉>双目视觉>RGBD。
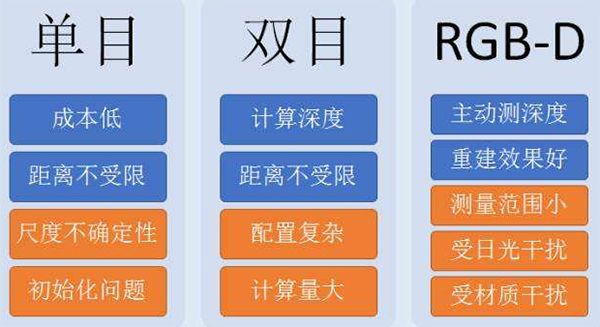
单目相机SLAM简称MonoSLAM,仅用一支摄像头就能完成SLAM。最大的优点是传感器简单且成本低廉,但同时也有个大问题,就是不能确切的得到深度。
一方面是由于绝对深度未知,单目SLAM不能得到机器人运动轨迹及地图的真实大小,如果把轨迹和房间同时放大两倍,单目看到的像是一样的,因此,单目SLAM只能估计一个相对深度。另一方面,单目相机无法依靠一张图像获得图像中物体离自己的相对距离。为了估计这个相对深度,单目SLAM要靠运动中的三角测量,来求解相机运动并估计像素的空间位置。即是说,它的轨迹和地图,只有在相机运动之后才能收敛,如果相机不进行运动时,就无法得知像素的位置。同时,相机运动还不能是纯粹的旋转,这就给单目SLAM的应用带来了一些麻烦。
而双目相机与单目不同的是,立体视觉既可以在运动时估计深度,亦可在静止时估计,消除了单目视觉的许多麻烦。不过,双目或多目相机配置与标定均较为复杂,其深度量程也随双目的基线与分辨率限制。通过双目图像计算像素距离,是一件非常消耗计算量的事情,现在多用FPGA来完成。
RGBD相机是2010年左右开始兴起的一种相机,它最大的特点是可以通过红外结构光或TOF原理,直接测出图像中各像素离相机的距离。因此,它比传统相机能够提供更丰富的信息,也不必像单目或双目那样费时费力地计算深度。
视觉SLAM框架解读
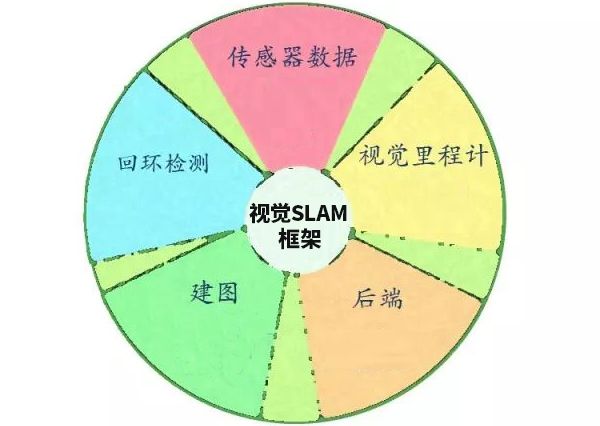
1.传感器数据
在视觉SLAM中主要为相机图像信息的读取和预处理。如果在机器人中,还可能有码盘,惯性传感器等信息的读取和同步。
2.视觉里程计
视觉里程计的主要任务是估算相邻图像间相机运动以及局部地图的样子,最简单的是两张图像之间的运动关系。计算机是如何通过图像确定相机的运动的。在图像上,我们只能看到一个个的像素,知道他们是某些空间点在相机的成像平面投影的结果。所以必须先了解相机跟空间点的几何关系。
Vo(又称为前端)能够通过相邻帧间的图像估计相机运动,并恢复场景的空间结构,称它为里程计。被称为里程计是因为它只计算相邻时刻的运动,而和再往前的过去信息没有关联。相邻时刻运动串联起来,就构成了机器人的运动轨迹,从而解决了定位问题。另一方面,根据每一时刻的相机位置,计算出各像素对应的空间点的位置,就得到了地图。
3.后端优化
后端优化主要是处理slam过程中噪声的问题。任何传感器都有噪声,所以除了要处理“如何从图像中估计出相机运动”,还要关心这个估计带有多大的噪声。
前端给后端提供待优化的数据,以及这些数据的初始值,而后端负责整体的优化过程,它往往面对的只有数据,不必关系这些数据来自哪里。在视觉slam中,前端和计算接视觉研究领域更为相关,比如图像的特征提取与匹配等,后端则主要是滤波和非线性优化算法。
4.回环检测
回环检测也可以称为闭环检测,是指机器人识别曾到达场景的能力。如果检测成功,可以显著地减小累积误差。回环检测实质上是一种检测观测数据相似性的算法。对于视觉SLAM,多数系统采用目前较为成熟的词袋模型(Bag-of-Words, BoW)。词袋模型把图像中的视觉特征(SIFT, SURF等)聚类,然后建立词典,进而寻找每个图中含有哪些“单词”(word)。也有研究者使用传统模式识别的方法,把回环检测建构成一个分类问题,训练分类器进行分类。
5.建图
建图主要是根据估计的轨迹建立与任务要求对应的地图,在机器人学中,地图的表示主要有栅格地图、直接表征法、拓扑地图以及特征点地图这4种。而特征点地图是用有关的几何特征(如点、直线、面)表示环境,常见于视觉SLAM技术中。这种地图一般通过如GPS、UWB以及摄像头配合稀疏方式的vSLAM算法产生,优点是相对数据存储量和运算量比较小,多见于最早的SLAM算法中。
视觉SLAM工作原理
大多数视觉SLAM系统的工作方式是通过连续的相机帧,跟踪设置关键点,以三角算法定位其3D位置,同时使用此信息来逼近推测相机自己的姿态。简单来说,这些系统的目标是绘制与自身位置相关的环境地图。这个地图可以用于机器人系统在该环境中导航作用。与其他形式的SLAM技术不同,只需一个3D视觉摄像头,就可以做到这一点。
通过跟踪摄像头视频帧中足够数量的关键点,可以快速了解传感器的方向和周围物理环境的结构。所有视觉SLAM系统都在不断的工作,以使重新投影误差(Reprojection Error)或投影点与实际点之间的差异最小化,通常是通过一种称为Bundle Adjustment(BA)的算法解决方案。vSLAM系统需要实时操作,这涉及到大量的运算,因此位置数据和映射数据经常分别进行Bundle Adjustment,但同时进行,便于在最终合并之前加快处理速度。
视觉SLAM与激光SLAM有什么区别?
在业内,视觉SLAM与激光SLAM谁更胜一筹,谁将成为未来主流趋势这一问题,成为大家关注的热点,不同的人也有不同的看法及见解,以下将从成本、应用场景、地图精度、易用性几个方面来进行详细阐述。
1.成本
从成本上来说,激光雷达普遍价格较高,但目前国内也有低成本的激光雷达解决方案,而VSLAM主要是通过摄像头来采集数据信息,跟激光雷达一对比,摄像头的成本显然要低很多。但激光雷达能更高精度的测出障碍点的角度和距离,方便定位导航。
2.应用场景
从应用场景来说,VSLAM的应用场景要丰富很多。VSLAM在室内外环境下均能开展工作,但是对光的依赖程度高,在暗处或者一些无纹理区域是无法进行工作的。而激光SLAM目前主要被应用在室内,用来进行地图构建和导航工作。
3.地图精度
激光SLAM在构建地图的时候,精度较高,思岚科技的RPLIDAR系列构建的地图精度可达到2cm左右;VSLAM,比如常见的,大家也用的非常多的深度摄像机Kinect,(测距范围在3-12m之间),地图构建精度约3cm;所以激光SLAM构建的地图精度一般来说比VSLAM高,且能直接用于定位导航。
视觉SLAM的地图建立
4.易用性
激光SLAM和基于深度相机的视觉SLAM均是通过直接获取环境中的点云数据,根据生成的点云数据,测算哪里有障碍物以及障碍物的距离。但是基于单目、双目、鱼眼摄像机的视觉SLAM方案,则不能直接获得环境中的点云,而是形成灰色或彩×××像,需要通过不断移动自身的位置,通过提取、匹配特征点,利用三角测距的方法测算出障碍物的距离。
总体来说,激光SLAM相对更为成熟,也是目前最为可靠的定位导航方案,而视觉SLAM仍是今后研究的一个主流方向,但未来,两者融合是必然趋势。
本文转截于:http://www.slamtec.com/cn/News?category=2