参考书目:[The C++ Standard Library 2nd Edition]
Move Semantics and Rvalue References
首先要搞明白两个概念:左值与右值。推荐这篇文章,讲的非常透彻。
- 左值( lvalue )
可以在内存中寻址的值,也就是可以放到等号左边的值。例如:
int a = 3; // 合法,a 是左值
a+a = 4; // 非法,a+a 是右值
- 右值( rvalue )
只能出现在等号右边的值,一般没有变量名。
C++11 的一个最重要的特性就是支持移动语义。
由于容器类都是采用值语义,合理利用移动语义能够避免不必要的拷贝。
X x; coll.insert(x); // inserts copy of x
...
coll.insert(x+x); // inserts copy of temporary rvalue
...
coll.insert(x); // inserts copy of x (although x is not used any longer)
在 C++11 之前,对于以上的程序,会创建 3 个 copy。然而,对于后两个,创建 copy 是不必要的。因为 x+x 与第二个 x 在此后都不会再使用。如果我们直接将这两个移动到容器中,就可以避免进行 copy,获得性能提升。
C++11 加入了 move 语法,使得这一切成为可能。但是它只会自动对临时的右值进行 move 优化。
X x;
coll.insert(x); // inserts copy of x (OK, x is still used)
...
coll.insert(x+x); // moves (or copies) contents of temporary rvalue
...
coll.insert(std::move(x)); // moves (or copies) contents of x into coll
现在我们只 copy 了一次。因为 x+x 自动采取了 move(如果他有move 构造函数),而第二个 x 我们手动指定采用move。
move 本身并不做任何移动,只是把其参数转为一个“右值引用”,用 X&& 表示。含义是一个能够被修改的右值。也就是说,实现了废物利用。将一个不会再使用的右值转为“右值引用”,继续使用。
int a1 = getVal(); // 1
int&& a2 = getVal(); // 2
一个典型的应用就是
namespace std {
template inline void swap(T &a, T &b)... {
T tmp(std::move(a));
a = std::move(b);
b = std::move(tmp);
}
}
Lambdas
C++11 引入了 Lambdas,这是现代编程语言中必不可少的一个功能。它有很多名字,有的语言称为 closures,有的称为 blocks。其含义就是匿名函数。
引入他的原因其实大部分是为了程序的简洁。假设某个功能只会在这一个地方用到,就可以将其以匿名函数的形式实现。
其基本使用格式为:
[<捕获变量方式>](<形参>) -> <返回类型>{<函数体>}(<实参>)
如果没有参数,可以省略形参部分。返回类型可以自己推断,所以一般也省略。
[...] {...} // 最简形式
如果不加最后的小括号,就不会立即调用。例如:
auto l = [] (const std::string& s) {
std::cout << s << std::endl;
}; // 定义而不调用
l("hello lambda"); // 在这里调用
Lambdas 的引入改变了 C++ 标准库的使用方式。
通过以下例程来看:
#include
#include
#include // for find_if
using namespace std;
// lambda test
int main() {
deque coll = {1, 3, 19, 5, 13, 7, 11, 2, 17};
int l = 5, r = 12;
// cbegin(), const iterator
auto pos = find_if(coll.cbegin(), coll.cend(),
[=](int i){
// 捕获了 l, r 变量,= 表示只读
// 如果试图修改,编译会报错
return i>l && i %d and < %d: %d\n", l, r, *pos);
printf("rescale to: [ ");
for_each(coll.begin(), coll.end(),
[](int &i){
i *= 2;
printf("%d ", i);
});
printf("]\n");
}
注意 for_each 和 find_if 源码都是类似的,传入的第三个参数是以容器元素为输入的一个函数,会被反复调用。如下所示。
namespace std {
template
Operation for_each (Iterator act, Iterator end, Operation op) {
while (act != end) {
op(*act);
++act;
}
return op;
}
}
这刚好也解释了为什么我们使用的 Lambda 是以数组元素为参数的。
另外一个经常用到的使用场景就是作为比较函数使用。例如我们希望升序排列数组的时候(这里当然可以直接使用 greater,但是这个写法可以用于自定义类型):
sort(coll.begin(), coll.end(), [](int i, int j)->bool {return i > j;});
变量捕获
首先猜测下面的程序输出是什么。
#include
int main(int argc, char const *argv[]) {
int x = 0;
int y = 10;
auto f = [x, &y] {
std::cout << "x: " << x << ", y: " << y << std::endl;
++y;
};
x = y = 20;
std::cout << "updated, x: " << x << ", y: " << y << std::endl;
f();
f();
std::cout << "final y: " << y << std::endl;
return 0;
}
这个例子说明了变量捕获的时间是在生成 lambda 变量的时候。也就是说输出应该是:
updated, x: 20, y: 20
x: 0, y: 20
x: 0, y: 21
final y: 22
智能指针
从 C 开始,指针就是一个重要但是又经常带来问题的类型。其中一个原因就是指针能够在出了作用域后被引用。但是,要确保指针的生命周期和她们指向的对象的生命周期一致非常麻烦,尤其是在一个对象被多个指针引用的情况下。例如,如果一个对象在多个 collection 中,理想情况下,指向该对象的指针销毁时,不应该出现空悬指针,也不应该多次删除对象。当该对象不再被引用时,不会发生资源泄漏。
C++11 提供了两类智能指针:
- shared_ptr
顾名思义,shared_ptr 引入了共享的概念。多个智能指针可以指向同一个对象,该对象会在不再被引用时释放。 - unique_ptr
顾名思义,unique_ptr 引入了唯一的概念。它确保了同时只有一个智能指针可以指向某个对象,但是可以转交对象给别的指针。这个指针可用于避免资源泄漏,例如调用 new 新建了对象,执行中由于发生了 exception,没有调用 delete。此时使用 unique_ptr 可以确保对象被回收。
所有智能指针都需要引入
在现代 C/C++ 中,非常推荐使用 unique_ptr 来代替普通的指针。
参见我的相关文章。
shared_ptr
几乎所有的大项目都需要在多个地方同时用到某些对象。这时,我们就必须确保在对象不被引用时进行销毁,释放资源。
这种情况下,我们就需要使用 shared_ptr 了。
智能指针用法跟一般指针一样,可以进行赋值,拷贝,以及比较操作,可以用 * 解引用。
默认的,智能指针假设对象用 new 创建, 采用 delete 来销毁。通常我们都需要定义自己的析构方法。例如我们的对象是一个使用 new[] 创建的数组,我们就应该采用 delete[] 来析构。或者,假设我们的对象使用了某些资源,例如临时文件,锁等,我们也需要在析构时释放这些资源。
其基本使用方法,如下程序所示:
#include // for smart pointers
#include
#include
using namespace std;
int main() {
shared_ptr pNico(new string("nico"),
[](string* p){
cout << "delete " << *p << endl;
delete p;
});
shared_ptr pJutta(new string("jutta"),
[](string* p){
cout << "delete " << *p << endl;
delete p;
});
(*pNico)[0] = 'N'; // parenthesis
pJutta->replace(0, 1, "J"); // replace from 0 before 1 to J
vector> whoMadeCoffee;
whoMadeCoffee.push_back(pJutta);
whoMadeCoffee.push_back(pJutta);
whoMadeCoffee.push_back(pNico);
whoMadeCoffee.push_back(pJutta);
whoMadeCoffee.push_back(pNico);
for (auto ptr : whoMadeCoffee) {
cout << *ptr << " ";
}
cout << endl;
// smart pointer is used exactly like a pointer
*pNico = "Nicolai";
for (auto ptr : whoMadeCoffee) {
cout << *ptr << " ";
}
cout << endl;
cout << "use_count: " << whoMadeCoffee[0].use_count() << endl; // 输出4,数组引用了3次,pJutta引用了1次
whoMadeCoffee.resize(0);
cout << "use_count: " << whoMadeCoffee[0].use_count() << endl; // 输出1,pJutta引用了1次
}
如果我们想定义一个数组:
std::shared_ptr p( new int[10], [](int *p){delete[] p;} );
值得注意的是 shared_ptr 的模板类型不能是数组。例如:
shared_ptr p2(new int[10]); // error, does not compile
unique_ptr p2(new int[10]); // OK
不能将普通指针赋值给一个智能指针,但是 nullptr 可以。
shared_ptr sb = nullptr; // OK
sb = new int(1); // error, does not compile
weak_ptr
shared_ptr 是为了自动释放不需要的对象所占用的资源而引入的。但是,在一些特定情况下,会出现问题。
- 循环引用。这是所有采用引用计数机制的设计方法的通病。Objective-C 中也有这个问题。如果两个对象使用 shared_ptr相互引用,则两者都无法被销毁,因为 A 使 B 的引用计数为1,B无法销毁。同时,B 使 A 的引用计数为1,A 也无法销毁。
- d
下面给出了使用 weak_ptr 解决循环引用的实例。
#include
#include
#include
using namespace std;
class Person {
public:
string name;
shared_ptr mother;
shared_ptr father;
// vector> kids;
vector> kids;
explicit Person(const string &name_,
shared_ptr mother_ = nullptr,
shared_ptr father_ = nullptr)
: name(name_), mother(mother_), father(father_) {}
~Person() {
cout << "delete" << name << endl;
}
};
shared_ptr initFamily (const string& name) {
shared_ptr mom(new Person(name + "'s mom"));
shared_ptr dad(new Person(name + "'s dad"));
shared_ptr kid(new Person(name, mom, dad));
mom->kids.push_back(kid);
dad->kids.push_back(kid);
return kid;
}
int main() {
shared_ptr pNico = initFamily("Nico");
cout << "Nico's family exists" << endl;
// 如果使用 shared_ptr,这里将输出 3。父母各一次,pNico一次。
// 使用 weak_ptr,这里输出1
cout << "- Nico is shared " << pNico.use_count() << " times"<< endl;
// 使用 weak_ptr 会有细微区别
// cout << "- name of the first child of Nico's mom: " << pNico->mother->kids[0]->name << endl;
cout << "- name of the first child of Nico's mom: " << pNico->mother->kids[0].lock()->name << endl;
// 使用 weak_ptr 时,这里会删除 nico 家庭
pNico = initFamily("Jim"); // Nico's family should be deleted here
cout << "Jim's family exists"<< endl;
}
应该记住使用 shared_ptr 时,所有引用都应该是单向的。也就是说 A 中引用了 B,那 B 就不能再用 shared_ptr 引用 A 了,一定要引用 A 就使用 weak_ptr。
当使用 weak_ptr 来访问一个对象时,我们需要使用 lock() 方法
来生成一个新的 shared_ptr。如方法介绍里说的:
shared_ptrlock() const noexcept;
Returns a shared_ptr with the information preserved by the weak_ptr object if it is not expired.
If the weak_ptr object has expired (including if it is empty), the function returns an empty shared_ptr (as if default-constructed).
Because shared_ptr objects count as an owner, this function locks the owned pointer, preventing it from being released (for at least as long as the returned object does not releases it).
This operation is executed atomically.
之所以叫做 lock(),是因为这个方法会锁定对象,直到返回的 shared_ptr 使用完后才能回收。
线程安全
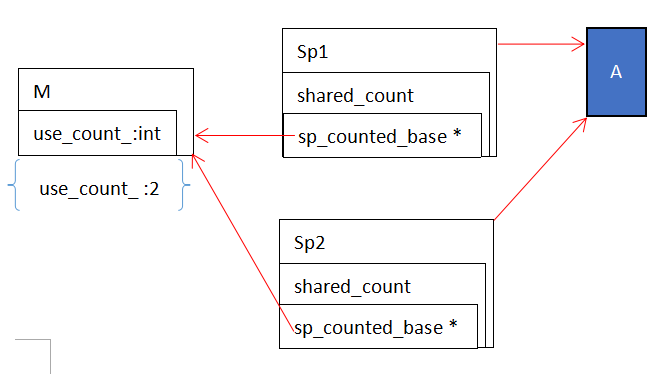
一般而言, shared_ptr 并不是线程安全的,因为它仅仅是实现了一个线程安全的引用计数,。当使用 shared_ptr 在多个线程中共享同一个对象时,需要用锁来避免竞争。但是当一个线程修改的时候,另一个线程读取 user_count 是合法的,不会引起竞争,但是有可能导致数据不是实时的。
还要注意的是,user_count() 函数并不是非常效率,只作为调试使用。
之所以产生这种情况,是因为指向同一个对象的指针,共享一个计数器,而不是各自持有一个。如下图所示,M 即为共享的计数区域。
unique_ptr
unique_ptr 也是从 C++11 新加入的类型。它主要用于避免发生 exception 时的资源泄漏。它实现了“独占”的思想,即保证了对象及其资源在同一时间只被一个指针占有。当指针不再指向该对象时,该对象也会被销毁。
unique_ptr 替代了 C++98 标准中的 auto_ptr 的作用。
如果不使用 unique_ptr,如果要确保内存不泄漏,我们需要在抛出异时做处理:
void f() {
ClassA* ptr = new ClassA; // create an object explicitly
try {
... // perform some operations
}
catch (...) { // for any exception
delete ptr; // - clean up
throw; // - rethrow the exception
}
delete ptr; // clean up on normal end
}
可以看这样的处理方式非常麻烦,而且随着对象的增加以及可能抛出异常的操作的增加,代码会越来越难以维护。
unique_ptr 解决了这个问题。它可以在自身销毁时释放对象。由于局部对象在栈上,函数结束后会自动销毁。此时就能确保它指向的对象销毁了。
我们可以将上面复杂的代码改写如下:
void f() {
std::unique_ptr u_ptr(new ClassA);
... // perform some operations
}
不再需要 try catch 处理,也不再需要显式调用 delete。
unique_ptr 使用注意事项
- 用户必须自己保证其唯一性。如下程序可以编译通过,但是运行时候会出错。
#include
#include
using namespace std;
int main() {
string *sp = new string("SB, hello");
unique_ptr u_ptr1(sp);
unique_ptr u_ptr2(sp); // 两个 unique_ptr 指向同一个对象
cout << *u_ptr1 << endl;
}
那么引申出一个问题,我们希望用一个 unique_ptr 来给另一个赋值,应该怎么做?答案是使用移动赋值。当然使用过后原来的 u_ptr1 就失效了。
std::unique_ptr u_ptr2(std::move(u_ptr1));