今天心血来潮,写了一个 Markdown 转换器。
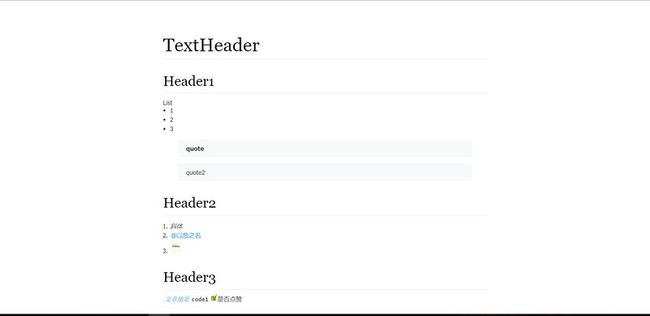
import os, re,webbrowser text = ''' # TextHeader ## Header1 List - 1 - 2 - 3 > **quote** 》 quote2 ## Header2 1. *斜体* 2. [@以茄之名](https://www.jb51.net/people/e4f87c3476a926c1e2ef51b4fcd18fa3) 3、  ## Header3 `*[文章地址](https://zhuanlan.zhihu.com/p/39742445)*` ・**code1**・ - [x]是否点赞 '''
程序开头先处理一些行内的语法,比如 code、strong、i 等,用正则直接替换:
text = re.sub(re.compile('([\`・])([^`・]+)[\`・]'), r'\2', text)
text = re.sub(re.compile('\*\*([^\*]+)\*\*'), r'\1', text)
text = re.sub(re.compile('([^\*])\*([^\*]+)\*'), r'\1\2', text)
接着是复杂一点的图片和链接:
text = re.sub(re.compile('([^\!])\[([^\]]+)\]\(([^)]+)\)'),
r'\1\2', text)
text = re.sub(re.compile('\!\[([^\]]*)\]\(([^)]+)\)'),
r' ', text)
', text)
接着就处理其他的语法,先把文本按每一行分开:
lines = text.split('\n')
html = ''
list_flag = ''
处理列表和待办事项的问题:
for line in lines:
line = line.strip(' ')
if re.match('- \[[ x]\]', line):
print('matched')
p_html = ''
if re.match('- \[x\]', line):
p_html = ' checked="checked"'
line = re.sub('- \[[ x]\]', '', line)
html += '''''' % (p_html, line)
因为有序列表和无序列表的区别是头尾的ol和ul,所以要用 list_flag 变量来判断
elif re.match('[\+\-\*] ', line):
if list_flag == '':
html += '- \n'
list_flag = 'ul'
line = re.sub('[\+\-\*] ', '', line)
html += '
- %s \n' % (line) elif re.match('[\d]+[.、] ', line): if list_flag == '': list_flag = 'ol' html += '
- %s \n' % (line)
- \n'
line = re.sub('[\d]+[.、] ', '', line)
html += '
处理完后处理其他的语法:
else:
if list_flag != '':
html += '\n' % list_flag
list_flag = ''
if re.match('\#+', line):
well = re.match('\#+', line).group().count('#')
line = re.sub('\#+', '', line)
html += '%s \n' % (well, line, well)
elif re.match('[>》 ]', line):
line = re.sub('^\s*[>》 ]', '', line)
html += '%s
\n' % (line)
# elif re.match('[>》 ]', line):
# line = re.sub('^\s*[>》 ]', '', line)
# html += '%s
\n' % (line)
else:
html += line
这里我稍微修改了一点,让 > 和 》 都可以转换成引用,主要是切换中英文标点太难了。
然后就是添加 CSS,自己改了一点马克飞象的进去,因为他的引用做得很漂亮:
with open('markdown.html', 'w', encoding='utf-8')as f:
f.write('''
''')
f.write(html)
f.write('')
用 Chrome 打开网页:
webbrowser.get('C:/Program Files (x86)/CentBrowser/Application/chrome.exe %s').open(
'file:///'+os.getcwd()+'/markdown.html')
话说这里也是个坑,系统自带的 Edge 一直打开失败,用那个注册器注册 Chrome 也没办法用 ,最后还是在外网找到了解决方案。
最后的效果:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。