前几天英伟达开源了DG-Net的源码。让我们来回顾一下这篇CVPR19 Oral的论文。
论文是英伟达(NVIDIA), 悉尼科技大学(UTS), 澳大利亚国立大学(ANU)的研究人员 在CVPR19上口头报告的文章《 Joint Discriminative and Generative Learning for Person Re-identification》。 深度学习模型训练时往往需要大量的标注数据,但收集和标注大量的数据往往比较困难。作者在行人重识别这个任务上探索了 利用生成数据来辅助训练的方法。通过生成高质量的行人图像,将其与行人重识别模型融合,同时提升行人生成的质量和行人重识别的精度。
论文链接:https://arxiv.org/abs/1904.07223
B 站视频: https://www.bilibili.com/video/av51439240/
腾讯视频: https://v.qq.com/x/page/t0867x53ady.html
代码:https://github.com/NVlabs/DG-Net

Why: (之前论文的痛点有哪些?)
- 生成高质量的行人图像有一定难度。之前一些工作生成的行人图像质量相对低(如上图)。主要体现在两个方面:1.生成的真实度:行人不够真实, 图像模糊, 背景不真实; 2. 需要额外的标注来辅助生成:需要额外的人体骨架或者属性标注。
- 若使用这些低质量的行人生成图像来训练行人重识别模型,会引入与原始数据集之间的差异(bias)。故之前的工作,要么仅仅把所有生成的行人图像看成outlier来正则网络; 要么额外- 训练一个生成图像的模型,和原始模型做融合; 要么就是完全不用生成的图像去训练。
- 同时,由于数据集的标注难度,行人重识别的训练集(如Market和DukeMTMC-reID)数据量一般在2W左右,远小于ImageNet等数据集,容易过拟合的问题也一直没有很好解决。
What: (这篇论文提出了什么,解决了什么问题)
-
不需要额外标注(如姿态pose,属性attribute,关键点keypoints等),就能生成高质量行人图像。通过交换提取出的特征,来实现两张行人图像的外表互换。这些外表都是训练集中真实存在的变化,而不是随机噪声。

-
不需要部件匹配来提升行人重识别的结果。仅仅是让模型看更多训练样本就可以提升模型的效果。给定N张图像,我们首先生成了NxN的训练图像,用这些图像来训练行人重识别模型。(下图第一行和第一列为真实图像输入,其余都为生成图像)
- 训练中存在一个循环: 生成图像喂给行人重识别模型来学习好的行人特征,而行人重识别模型提取出来的特征也会再喂给生成模型来提升生成图像的质量。
How:(这篇文章是怎么达到这个目标)
- 特征的定义:
在本文中,我们首先定义了两种特征。一种为外表特征,一种为结构特征。外表特征与行人的ID相关,结构特征与low-level的视觉特征相关。

- 生成的部分:
- 同ID重构:相同人不同照片的appearance code应该是相同的。如下图,
我们可以有一个自我重构的loss(上方,类似auto-encoder),还可以用同ID的postive sample来构建生成图像。这里我们用了pixel-level的L1 Loss。
- 同ID重构:相同人不同照片的appearance code应该是相同的。如下图,

- 不同ID生成:
这是最关键的部分。给定两张输入图像,我们可以交换他们的appearance 和 structure code来生成有意思的两个输出,如下图。对应的损失有: 维持真实性的GAN Loss, 生成图像还能重构出对应的a/s的特征重构损失。我们的网络中没有随机的部分,所以生成图像的变化都是来自训练集本身。故更接近原始的训练集。
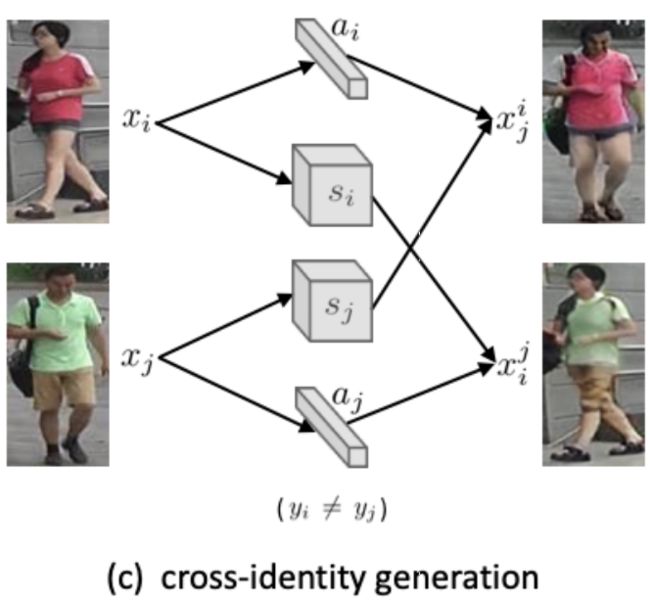
- reID的部分:
对于真实图像,我们仍旧使用分类的cross entropy loss。
对于生成图像,我们使用了两个loss,一个为L{prime},通过训好的baseline模型当老师,来提供生成图像的soft label,最小化预测结果和老师模型的KL距离。另一个loss,来挖掘一些图像变了appearance后,仍保留的细节信息,为L{fine}。(具体细节可以见论文。)

Results:
- 定性指标:
- 外表互换,我们在三个数据集上测试了结果,可以看到对于遮挡/大的光照变化,我们的方法都相对鲁棒。
- 外表插值。网络是不是记住了生成图像的样子。故我们做了一个逐渐改变appearance的实验,可以看到外表是逐渐并且smooth地改变的。

- 失败的案例。不常见的图案如logo无法还原。

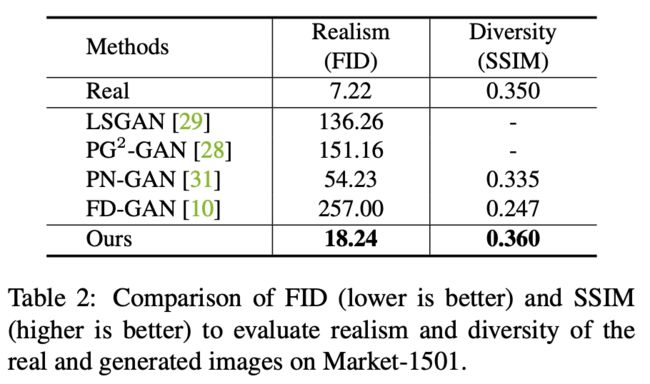
- 定量指标:
- 生成图像的真实度(FID)和多样性(SSIM)比较。FID越小越好,SSIM越大越好。
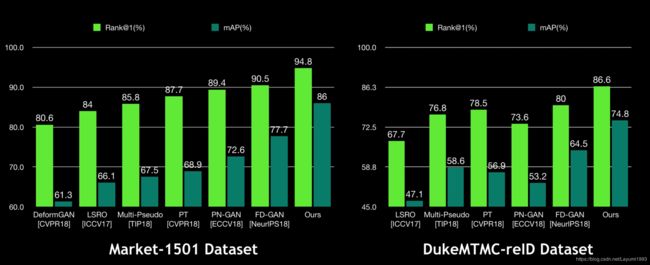
- 在多个数据集上的reID结果 (Market-1501, DukeMTMC-reID, MSMT17, CUHK03-NP)。

附:视频Demo
B 站视频备份: https://www.bilibili.com/video/av51439240/
腾讯视频备份: https://v.qq.com/x/page/t0867x53ady.html
最后,感谢大家看完。因为我们也处在初步尝试和探索阶段,所以不可避免地会对一些问题思考不够全面。如果大家发现有不清楚的地方,欢迎提出宝贵意见并与我们一起讨论,谢谢!
参考文献
[1] Z. Zheng, L. Zheng, and Y. Yang. Unlabeled samples generated by gan improve the person re-identification baseline in vitro. ICCV, 2017.
[2] Y. Huang, J. Xu, Q. Wu, Z. Zheng, Z. Zhang, and J. Zhang. Multi-pseudo regularized label for generated samples in person reidentification. TIP, 2018.
[3] X. Qian, Y. Fu, T. Xiang, W. Wang, J. Qiu, Y. Wu, Y.-G. Jiang, and X. Xue. Pose-normalized image generation for person reidentification. ECCV, 2018.
[4] Y. Ge, Z. Li, H. Zhao, G. Yin, X. Wang, and H. Li. Fd-gan: Pose-guided feature distilling gan for robust person re-identification. In NIPS, 2018.
作者简介
本文的第一作者郑哲东是悉尼科技大学计算机科学学院的博士生,预计2021年 6 月毕业。该论文是其在英伟达实习期间的成果。
郑哲东目前已经发表8篇论文。其中一篇为ICCV17 spotlight,被引用超过了300次。首次提出了利用GAN生成的图像辅助行人重识别的特征学习。一篇TOMM期刊论文被Web of Science选为2018年高被引论文,被引用超过200次。同时,他还为社区贡献了行人重识别问题的基准代码,在Github上star超过了1000次,被广泛采用。
另外,论文的其他作者包括英伟达研究院的视频领域专家 - 杨晓东、人脸领域专家禹之鼎(Sphere Face,LargeMargin作者)、行人重识别专家郑良博士,郑哲东的导师杨易教授(今年有三篇 CVPR oral 中稿)、和英伟达研究院的VP Jan Kautz等。
郑哲东个人网站:http://zdzheng.xyz/