一、首先介绍Spark的基本概念
1、Cluster Manager:Spark集群的资源管理中心
1>Standalone模式:Cluster Manager为Spark原生的资源管理器,由Master节点负责资源的分配;
2>Haddop Yarn模式:Cluster Manager由Yarn中的ResearchManager负责资源的分配
3>Messos模式:Cluster Manager由Messos中的Messos Master负责资源管理。
2、Worker Node:Spark集群中可以运行Application代码的工作节点。
3、Executor:是运行在工作节点(Worker Node)上的一个进程,负责执行具体的任务(Task),并且负责将数据存在内存或者磁盘上。
4、Application:Spark Application,是用户构建在 Spark 上的程序
如图:
1>包含了Driver,和一批应用独立的Executor进程
2>每一个Application包含多个作业Job,每个Job包含多个Stage阶段,每个stage包含多个Task。
3>Job:作业,一个Job包含多个RDD及作用于相应RDD上的各种操作。
4>Stage:阶段,是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为“阶段”。
5>TaskScheduler:任务调度器
6>Task:任务,运行在Executor上的工作单元,是Executor中的一个线程。
5、Driver Program:驱动程序
1>运行应用Application的 main() 方法并且创建了 SparkContext;
2>Driver 分为 main() 方法和 SparkContext两部分。6、DAG:是Directed Acyclic Graph(有向无环图)
1>用于反映RDD之间的依赖关系。
2>工作内容如图:
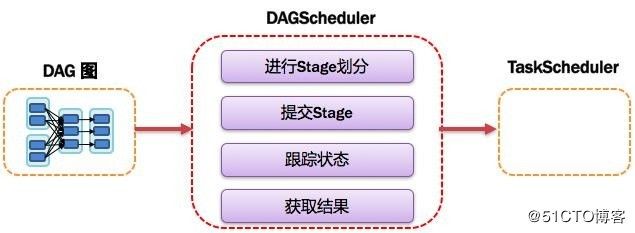
7、DAGScheduler:有向无环图调度器
1>基于DAG划分Stage,并以TaskSet的形势提交Stage给TaskScheduler;
2>负责将作业拆分成不同阶段的具有依赖关系的多批任务;
3>计算作业和任务的依赖关系,制定调度逻辑。
4>在SparkContext初始化的过程中被实例化,一个SparkContext对应创建一个DAGScheduler
5>工作内容如图:
二、Spark服务是如何执行任务的?
官方流程如图: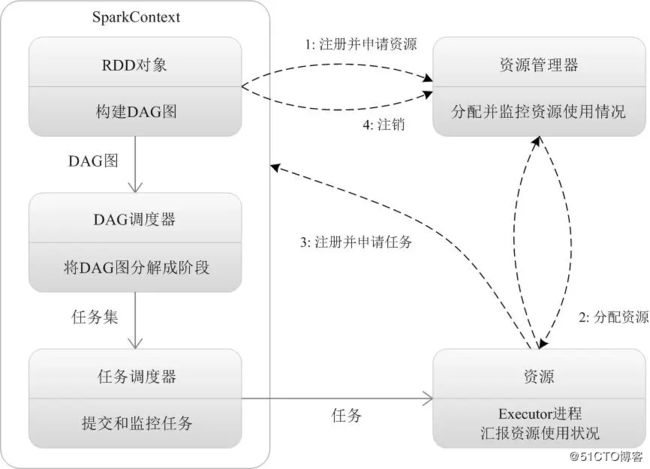
下面,我们对每一步做详细说明:
1、客户端提交作业:spark-submit
2、创建应用,运行Application应用程序的main函数,创建SparkContext对象(准备Spark应用程序的运行环境),并负责与Cluster Manager进行交互。
3、通过SparkContext向Cluster manager(Master)注册,并申请需要运行的Executor资源。
4、Cluster manager按资源分配策略进行分配。
5、Cluster manager向分配好的Worker Node发送,启动Executor进程指令。
6、Worker Node接收到指令后,启动Executor进程。
7、Executor进程发送心跳给Cluster manager。
8、Driver程序的SparkContext,构建成DAG图。
9、SparkContext进一步,将DAG图分解成Stage阶段(即任务集TaskSet)。
10、SparkContext进一步,将Stage阶段(TaskSet)发送给任务调度器(TaskScheduler)。
11、Executor向TaskScheduler申请任务(Task)。
12、TaskScheduler将Task任务发放给Executor运行,SparkContext同时将Application应用代码发放给Executor。
13、Executor运行应用代码,Driver进行执行任务监控。
14、Execurot运行任务完毕后,向Driver发送任务完成信号。
15、Driver负责将SparkContext关闭,并向Cluster manager发送注销信号。
15、Cluster manager收到Driver的注销信号后,向Worker Node发送释放资源信号。
16、Worker Node对应的Executor程序停止运行,资源释放。