图计算是大数据领域一个技术分支,可能没有离线分布式计算、流处理、分布式存储那么火热,但是也应用甚广。以我有限的了解,先谈一谈这个领域的现状。

图在生活中其实无处不在,社交媒体、科学中分子结构关系、电商平台的广告推荐、网页信息.etc. 图能够将人、产品、想法、事实、兴趣爱好之间的关系全部转换存储。各种场景下的信息都能转成图来表示,同时我们可以利用图来进行数据挖掘和机器学习,比如识别出有影响力的人和信息、社区发现、寻找产品和广告的投放用户、给有依赖关系的复杂数据构建模型等等这些都可以使用图来完成。
目前开源的图计算框架,主要有Spark GraphX、GraphFrames、GraphLab、Giraph等,由于公司环境以Spark生态为主,所以目前我对GraphX和GraphFrames较熟悉。下面介绍GraphX 和 GraphFrames:
GraphX是Spark中的一个API,主要作用是图(Web-Graphs and Social Networks) 以及图并行计算(PageRank and Collaborative Filtering),可以认为是GraphLab(C++)和Pregel(C++)在Spark(Scala)上的重新实现和优化。与其他分布式图计算框架相比,GraphX最大的优势是:在Spark之上提供了一栈式数据解决方案,可以方便高效地完成一整套流水作业。简而言之,HDFS + Hive + Spark + GraphCompute,甚至还可以 + Neo4j。
GraphFrames 是Spark的一个package,目前出到0.5.0版本(2017/5/25),它提供了基于DataFrame的Graph,目前提供Scala、Python、Java三种语言的API接口,它的目标是利用Spark DataFrame的优势,提供GraphX的功能以及其他扩展功能。这些扩展功能包括主题发现、基于DataFrame的序列化和高效图查询。简而言之:GraphFrames之于GraphX,就像DataFrame之于RDD(GraphX is to RDDs as GraphFrames are to DataFrames.)
简单来说,分布式图框架是将大型图的各种操作封装成接口,让分布式存储、并行计算等复杂问题对上层透明,从而使工程师将焦点放在图相关的模型设计和使用上,而不用关心底层的实现细节。分布式图框架的实现需要考虑两个问题,第一是怎样切分图以更好的计算和保存;第二是采用什么图计算模型。下面分别介绍这两个问题。
1 图切分方式:
图的切分主要有点切分以及边切分两种:
点切分:通过点切分之后,每条边只保存一次,并且出现在同一台机器上。邻居多的点会被分发到不同的节点上,增加了存储空间,并且有可能产生同步问题。但是,它的优点是减少了网络通信。
边切分:通过边切分之后,顶点只保存一次,切断的边会打断保存在两台机器上。在基于边的操作时,对于两个顶点分到两个不同的机器的边来说,需要进行网络传输数据。这增加了网络传输的数据量,但好处是节约了存储空间。
以上两种切分方式虽然各有优缺点,但是点切分还是占有优势。GraphX以及后文提到的Pregel、GraphLab都使用到了点切分。
这里较为详细地介绍点切分与边切分的原理(分布式图计算中的点切分和边切分);这里较为详细地从GraphX源码层面剖析了图的切割和生成,来自于Albert Cheng的Blog(Graphx 源码剖析-图的生成 或者 Graphx 源码剖析-图的生成)。
2 图计算框架:
图计算框架,基本上都遵循分布式皮同步(Bulk Synchronous Parallell,BSP)计算模式。基于BSP模式目前有两种比较成熟的图计算框架: Pregel 和 GraphLab。
2.1 BSP
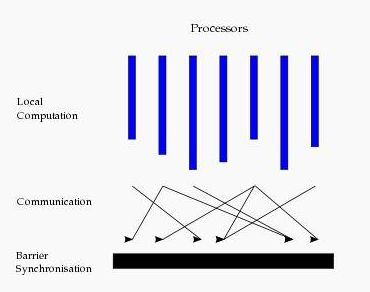
BSP模式的准则是批量同步(bulk synchrony),其独特之处在于超步(superstep)概念的引入。如上图所示,一次计算过程由一系列全局超步组成,每一个超步包含并行计算(local computation)、全局通信(非本地数据通信)以及栅栏同步(等待通信行为结束)三个阶段。
BSP模型的几个特点:
1 将计算划分为一个一个的超步(superstep),有效避免死锁;
2 将处理器和路由器分开,强调了计算任务和通信任务的分开,而路由器仅仅完成点到点的消息传递,不提供组合、复制和广播等功能,这样做既掩盖具体的互连网络拓扑,又简化了通信协议;
3 采用障碍同步的方式、以硬件实现的全局同步+可控的粗粒度级,是执行紧耦合同步式并行算法的有效方式。
2.2 Pregel框架
Pregel是一种面向图算法的分布式编程框架,采用迭代的计算模型:在每一轮,每个顶点处理上一轮收到的消息,并发出消息给其它顶点,并更新自身状态和拓扑结构(出、入边)等。有意思的是,Pregel 这个名字的来源,是纪念著名的欧拉七桥问题,这七座桥就位于Pregel这条河上。
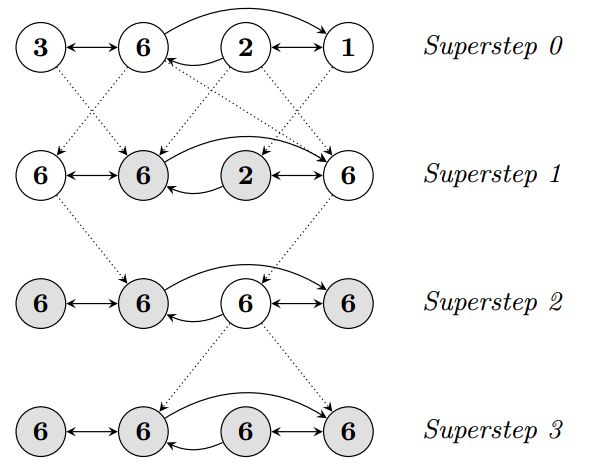
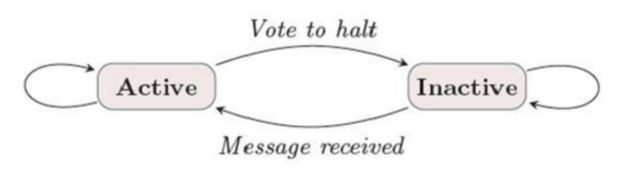
典型的Pregel计算流程是这样的:读取输入--->初始化图--->初始化完成--->运行一系列超步--->计算结束,其中从全局的角度看,每一个超步都是独立运行的。在以上的过程中,不难想象每一个节点会存在两种属性:活跃Active和非活跃Halt。当某个节点接收到了消息并且消息告知它需要执行计算了,那么该节点会将自己设置为Active状态;反之当某节点没有接收到消息或者“接收到了消息但是并不需要进行计算”,则将自己设置成Halt状态。该机制如下图所示:
Pregel的计算大致是这样一个过程:输入图数据且初始化---->所有节点置为Active且向周围节点SendMessage(包括正向边反向边双向边)----->每个节点接收消息切根据预定义的计算函数对消息进行处理随后更新自身信息或者设置为Inactive(Halt)---->每个活跃节点按照SendMessage函数继续发送消息---->下一个SuperStep开始----->直到所有节点Hale/Inactive结束计算。
下面还是以这幅图为例:下图中共4节点,从左到右依次为节点A/B/C/D。圈中的数字为节点的属性值,实线为节点之间的边(包含方向),虚线是不同超步之间的信息发送,带阴影的圈是不活跃的节点。我们的目的是让图中所有节点的属性值都变成最大的那个属性值。
superstep 0:首先所有节点设置为活跃,并且沿正向边向相邻节点发送自身的属性值(SendMessage)。
Superstep 1:所有节点接收到信息,节点A和节点D发现自己接受到的值比自己的大,所以更新自己的节点(这个过程可以看做是计算),并保持活跃。但是节点B和C没有接收到比自己大的值,所以不计算、不更新。活跃节点继续向相邻节点发送当前自己的属性值。
Superstep 2:节点C接受信息并计算,其它节点没接收到信息或者接收到但是不计算,所以接下来只有节点3活跃并发送消息。
Superstep 3:节点B和D接受到消息但是不计算所以不活跃,所有节点均不活跃,所以计算结束。
可以看出,在pregel计算框架中有两个核心的函数:sendmessage函数和F(Vertex)节点计算函数。
以下链接详细分析Spark GraphX 中Pregel函数的源码:http://www.jianshu.com/p/d926150542df