Tree-structured Kronecker Convolutional Networks for Semantic Segmentation 论文解读
Tree-structured Kronecker Convolutional Networks for Semantic Segmentation
原文地址: TKCN
收录:AAAI2019
代码:
PyTorch
简介:
论文引入了 Kronecker convolution 来解决空洞卷积局部信息丢失问题,除此之外,提出了一个TFA模块,利用树形分层结构进行多尺度与上下文信息整合。论文提出的TKCN在多个数据集上获得了不错的结果。
Abstract
本文提出了Kronecker convolution,用于解决在语义分割领域使用带孔卷积所带来的丢失部分信息的问题。 因此,它可以在不引入额外参数的情况下捕获部分信息并同时扩大滤波器的感知域。其次,我们提出了树状结构特征聚合(TFA)模块,该模块遵循递归规则来扩展并形成分层结构。 因此,它可以自然地学习多尺度对象的表示并在复杂场景中编码分层上下文信息。
实验证明上下文编码模块能够显著的提升语义分割性能,在Pascal-Context上达到了51.7%mIoU, 在 PASCAL VOC 2012上达到了85.9% mIoU,单模型在ADE20K测试集上达到了0.5567。 此外,论文进一步讨论上下文编码模块在相对浅层的网络中提升特征表示的能力,在CIFAR-10数据集上基于14层的网络达到了3.45%的错误率,和比这个多10倍的层网络有相当的表现。
Introduction
Motivation
扩张卷积存在的问题
语义分割是计算机视觉的重大挑战。语义分割的目标是将一个语义标签分配给图像中的每个像素。基于深度卷积神经网络(DCNN)的当前分割模型在几个语义分割基准上实现了良好的性能。 例如完全卷积网络(FCN)。这些模型转移了在ImageNet数据集[28]上预训练的分类网络[30,11],通过删除最大池,改变完全连接的层和添加反卷积层来生成分段预测。最近,采用萎缩卷曲,也称为扩张卷积[38],而不是某些FCN层中的标准卷积已经成为主流,因为扩张卷积可以扩大视野并保持特征图的分辨率。尽管扩张卷积在语义分割中表现出良好的表现,但它缺乏捕获部分信息的能力。为了更好地说明这个问题,我们将有效特征比(VFR)定义为计算中涉及的特征向量的数量与卷积补丁中所有特征向量的特征向量的比率。 VFR可以测量卷积patch中特征的利用率。如图1(a)所示,扩张卷积的VFR相对较低,这意味着忽略了更多的部分信息。如图1(b)所示,我们可以观察到,当采用大的带孔滤f时,带孔卷积失去了重要的部分信息。通常,卷积patch中的81个特征向量中只有9个参与计算。 特别是,当带孔滤非常大并超过特征映射的大小时,3×3滤波器将退化为1×1滤波器而不捕获全局上下文信息,因为只有中心滤波器分支有效。

为了解决上述问题,我们提出了Kronecker在计算和应用数学方面受Kronecker产品启发的卷积。我们提出的Kronecker卷积不仅可以继承带孔卷积的优点,还可以减轻其限制。所提出的Kronecker卷积使用Kronecker积来扩展标准卷积核,以便捕获由于带孔卷积被忽略的特征向量,如图1(c)所示。 Kronecker卷积有两个因素,即扩张因子r1和内共享因子r2。一方面,扩张因子控制插入核中的孔的数量。因此,Kronecker卷积具有扩大感受野并保持特征图分辨率的能力,即Kronecker卷积可以继承带孔卷积的优点。另一方面,内共享因子控制子区域的大小以捕获特征向量并共享滤波器向量。因此,Kronecker卷积可以在不增加参数数量的情况下考虑部分信息并增加VFR,如图1(a)和(c)所示。
图像的上下文信息
图像中的场景具有分层结构,可以分解为小范围场景或局部场景(例如单个对象),中场场景(例如多个对象)和大范围场景(例如整个图像))。如何在复杂场景中有效地捕获分层上下文信息对于语义分割是重要的并且仍然是一个挑战。基于此观察,我们提出了树状结构特征聚合(TFA)模块来编码分层上下文信息,这有利于更好地理解复杂场景并提高分割准确性。我们的TFA模块遵循递归规则进行扩展,并形成树形和层次结构。 TFA模型中的每个层都有两个分支,一个分支保留当前区域的特征,另一个分支在较大范围内聚合空间依赖性。
所提出的TFA模块有两个主要优点:(1)面向复杂场景中的层次结构,TFA模块可以有效地捕获分层上下文信息; (2)与现有的基于预设尺度的多尺度特征融合方法相比,依靠固有网络结构,TFA模块可以自然地通过树形结构学习多尺度对象的表达。
Contribution
基于以上观察,我们提出了用于语义分割的Trees tructured Kronecker卷积网络(TKCN),它采用Kronecker卷积和TFA模块形成统一的框架。 我们在三个主流的语义分割基准上进行实验,包括PASCAL VOC 2012,Cityscapes和PASCAL-Context。 实验结果验证了我们提出的方法的有效性。 我们的主要贡献可归纳为三个方面:
-
我们提出了Kronecker卷积,它可以有效地捕获部分细节信息并同时扩大感受野,而无需引入额外的参数。
-
我们开发树形结构特征聚合模块以捕获分层上下文信息并表示多尺度对象,这有助于更好地理解复杂场景。
-
在没有任何后处理步骤的情况下,我们设计的TKCN在PASCAL VOC 2012,Cityscapes和PASCALContext的基准测试中取得了令人瞩目的成果。
Proposed Approaches
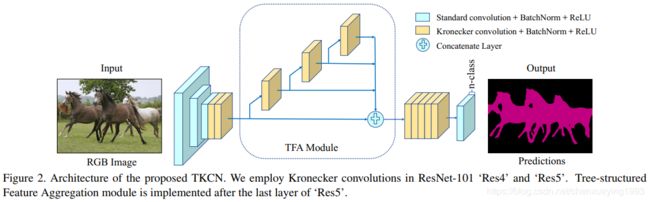
针对语义分割设计了 Tree-structured Kronecker Convolutional Network (TKCN) . 如下图:
Kronecker Convolution:

使用Kronecker convolution来解决空洞卷积局部信息丢失问题,以r1=4、r2=3为例,KConv将每个标准卷积的元素都乘以一个相同的矩阵,该矩阵由0,1组成,这样参数量是不增加的。该矩阵为:

这样每个元素乘以矩阵后变为上面右图所示的图。因此,可以看出r1控制空洞的数量,也即扩大了感受野,而r2控制的是每个空洞卷积忽视的局部信息。当r2=1时,其实就是空洞卷积,当r2=r1=1时就是标准卷积。
总体效果mIOU提升了1%左右。
Tree-structured Feature Aggregation Module:
为了捕获分层上下文信息并在复杂场景中表示多个尺度的对象,我们提出了TFA模块。 TFA模块将骨干网提取的特征作为输入。 TFA模块遵循扩展和堆叠规则,以有效编码多尺度特征。 如图3的左侧子图所示,在每个扩展步骤中,输入被复制到两个分支。 一个分支保留当前比例的特征,另一个分支在较大范围内探索空间依赖性。 同时,当前步骤的输出特征通过串联与先前特征堆叠在一起。 此扩展和堆叠规则可以表述为:
![]()
这里面![]() 是第n步的输出。
是第n步的输出。![]() 是第n步TFA模块的结果,g代表concatenation操作。在提出的TFA模块中,我们采用具有不同的扩展因子和内部共享因子的Kronecker卷积来捕获多尺度特征,然后是批量标准化BN和ReLU层。最后,将汇总所有分支的功能。如图3的右侧子图所示,在我们的实验中,我们利用TFA模块进行了三个扩展步骤,因此最终将所有分支的特征连接起来。特别地,为了在计算复杂度和模型能力之间进行权衡,如果TFA模块的输入特征映射具有C的信道,则将TFA模块中的每个卷积层的输出信道减少为C / 4。
是第n步TFA模块的结果,g代表concatenation操作。在提出的TFA模块中,我们采用具有不同的扩展因子和内部共享因子的Kronecker卷积来捕获多尺度特征,然后是批量标准化BN和ReLU层。最后,将汇总所有分支的功能。如图3的右侧子图所示,在我们的实验中,我们利用TFA模块进行了三个扩展步骤,因此最终将所有分支的特征连接起来。特别地,为了在计算复杂度和模型能力之间进行权衡,如果TFA模块的输入特征映射具有C的信道,则将TFA模块中的每个卷积层的输出信道减少为C / 4。
遵循上述扩展和堆叠规则,TFA模块形成树形和分层结构,可以有效地捕获分层上下文信息并从多个尺度聚合特征。此外,可以在后续步骤中重新研究从先前步骤中学到的特征,这些特征优于具有多个单独分支的现有并行结构。

Experiment