基于DL4J的CNN分类,平台:Spark(对平台的一些调试:在单机和集群件转换)
免责声明:本文仅代表个人观点,如有错误,请读者自己鉴别;如果本文不小心含有别人的原创内容,请联系我删除;本人心血制作,若转载请注明出处
平台:Spark
深度学习库:DL4J
分类器:softmax
数据集:Minist、MSTAR、Calteck-256
我所使用的例子是在GitHub上下载的,所用的例子是:JavaMnistClassification
1、处理数据集
训练数据:train-images-idx3-ubyte
训练标签:train-labels-idx1-ubyte
如Minist数据,Image size 28*28
训练数据:存放格式是前16位存放关于数据的说明:数据类型、数据样本数、行数、列数(各4位)
训练标签:前8位是对标签的说明:数据类型、标签数目(各4位)
下面讲解一下怎么将普通数据集转换成上述格式
Minist:Image size 28*28(我是通过MATLAB转的)
Data(1:16,1)=[0 0 8 3 0 0 2 88 0 0 0 28 0 0 0 28]';
1-4位:0 0 8 3(无符号整型),这里维持不变就好
5-8位:样本数=Data(8)*(256^3)+Data(7)*256*256+Data(6)*256+Data(5)
9-12位:行数=Data(12)*(256^3)+Data(11)*256*256+Data(10)*256+Data(9)
13-16位:列数=Data(16)*(256^3)+Data(15)*256*256+Data(14)*256+Data(13)
Lab(1:8)=[0 0 8 1 0 0 2 88]';
1-4位:0 0 8 1(无符号整型)
5-8位:标签数(与样本数对应)=Lab(8)*(256^3)+Lab(7)*256*256+Lab(6)*256+Lab(5)
代码如下:

上述代码只是对简单的对一个次类型数据的读写,以这种方式可以转换任何数据,但是需要注意的是无论是数据还是标签都要转换成无符号整型(MATLAB里是uint8格式)
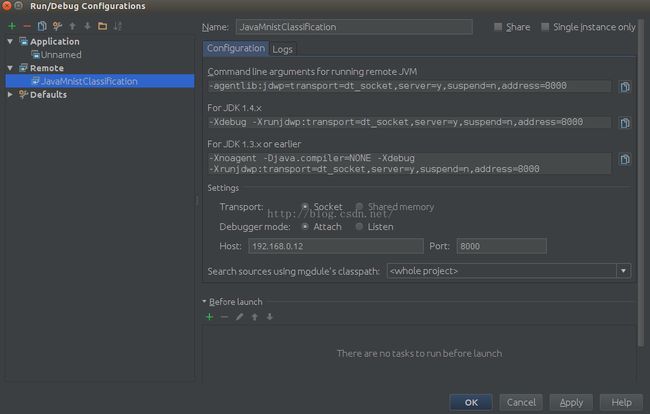
2、设置集群模式和单机模式
因为spark好后就是集群模式,反而难以配置的是单机模式,所以我们主要讲解单机配置,只有在单机模式下才可以进行单步调试
设制单机模式,将模式设置为"local"模式![]()
修改spark-env.sh
![]()
再做如下设置
3、代码解析
代码部分主要分为:设置模式,加载数据,设置训练测试数据,设置输入、输出、分类,模型
1)、设置模式,与普通spark代码基本相同

2)、加载数据(设置加载路径,数据分区)

3)、设置训练数据和测试数据
![]()
4)、设置输入、输出、分类
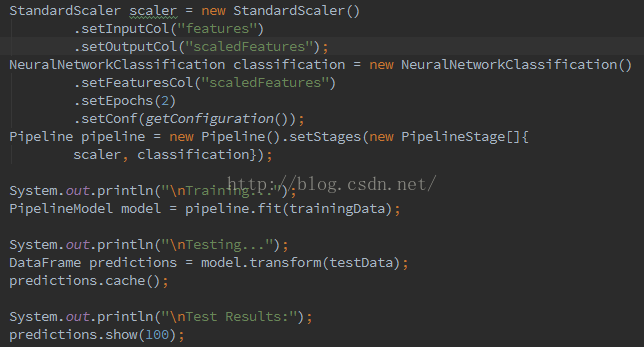
上述四步最重要的是要将数据转换成spark的数据库类型DataFrame(spark的并行都是基于这个数据库),然后要建立pipeline(管道),这才是spark实现并行的具体方式
5)、模型(卷积,池化,非线性变换,dropout,分类器等等)

4、结果(迭代次数设置高一些,效果肯定会更好)

总结
这是一个在spark平台上的深度学习实验,所以我们要做的是将数据导入到spark平台,按照spark的平台风格搭建深度模型,其中最关键的是:数据导入,数据库建立,并行,模型等