常见的激励函数和损失函数
Hello,又是一个分享的日子,博主之前写了一篇推文码前须知---TensorFlow超参数的设置,介绍了我们训练模型前需要设定的超参数如学习率(learning rate)、优化器(optimizer)及防止过拟合的几种工具如Dropout和正则化L1、L2。这一期博主将介绍我们在训练过程中常用的激励函数(activation function)和损失函数(loss function),更进一步帮助小伙伴们将整体的超参数知识体系补充完整。
本期内容概要:
激励函数的原理
常见的激励函数(activation function)
常见的损失函数(loss function)
激励函数
原理
![]()
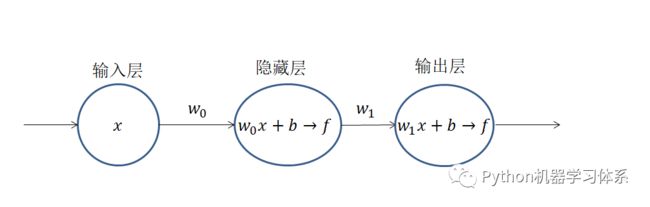
在谈及常见的激励函数前,我们得先知道激励函数是干啥用的。如上图,神经元的输出值会经历一个f函数,我们将这个函数叫做激励函数(activation function)。加入激励函数的目的也非常纯粹,就是为了让神经网络模型能够逼近非线性函数。倘若我们去掉激励函数,神经元就只有线性函数y=wx+b,这样的神经网络就只能逼近线性函数了。假如在不加激励函数的前提下,我们要训练一个分类模型,倘若数据是非线性可分的,那么模型的准确率会相当低,因为我们的模型训练不出一个非线性函数去拟合我们的数据。

常见的激励函数
![]()
1.Sigmoid
如下图所示,sigmoid函数可以将神经元的输出值压缩到(0, 1)之间,是早期常用的激励函数之一。但是随着算力的提升,人们开始搭建多层神网络模型,sigmoid的缺点也就暴露出来了。我们知道每一个神经元的输出值是经过激励函数之后,传递给下一个神经元的,也就是说,层与层之间的神经元是连乘的关系,倘若我们在多层神经网络层使用sigmoid函数,它将每一层的神经元输出值压缩至(0, 1),那么连乘的结果就会越来越小,直至为0,也就是我们常说的梯度消失。
与之有类似缺点的激励函数还有tanh函数,因此现在经常将sigmoid和tanh用在层数较少的神经网络模型中,或者放在回归模型输出层中用作回归的激励函数,亦或者放在分类模型输出层中用作计算概率的激励函数。
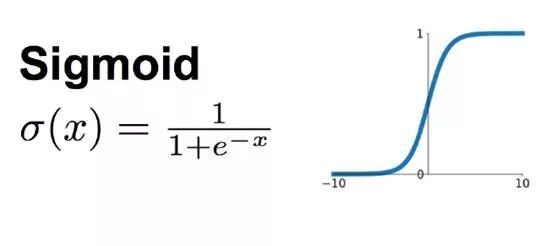
Sigmoid函数
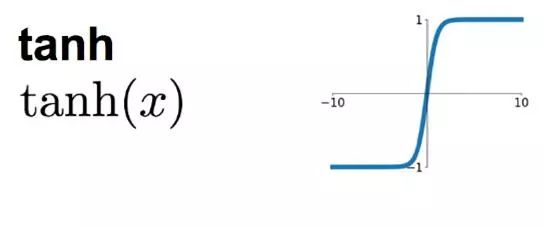
tanh函数
2.Linear
线性激活函数,即不对神经元的输出值进行处理,直接输出。通常用在回归模型的输出层中。
3.Softmax
通常用在分类模型的输出层中。原理如下:
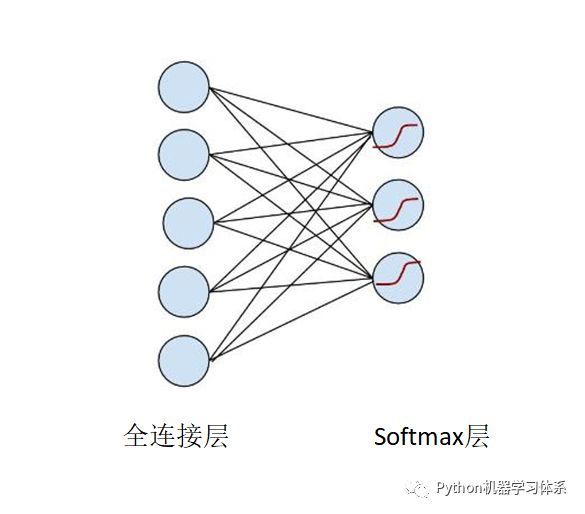
softmax层的每一个节点的激励函数
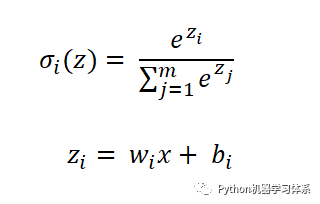
并且

上面的公式,我们可以理解为每个节点输出一个概率,所有节点的概率加和等于1,这也是选择softmax层进行分类的原因所在,可以将一张待分类的图片放进模型,softmax输出的概率中,最大概率所对应的标签便是这张待分类图的标签。
这时候,博主给小伙伴们举个例子就明白了。现在我们的softmax层有3个神经元,也就是说我们可以训练一个分三类的分类器,现在假设我们有一组带标签的训练样本,他们的标签可以如此标记,对应节点标记1,其他标记0。(其实就是onehot编码)
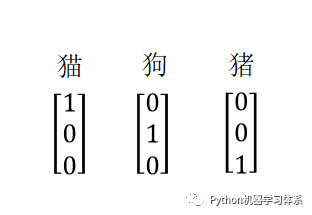
训练的时候将训练样本图片放入输入层,标签向量放入输出层,最终训练出一个模型。
此时,博主将一张待分类的图片放入我们的模型中,最后softmax层输出的结果是这样的。

这时,小伙伴就明白了上诉公式的含义了吧,0.85对应着最大概率,说明这张图片是猫,所有概率加起来等于1,这样是不是好理解很多啦。
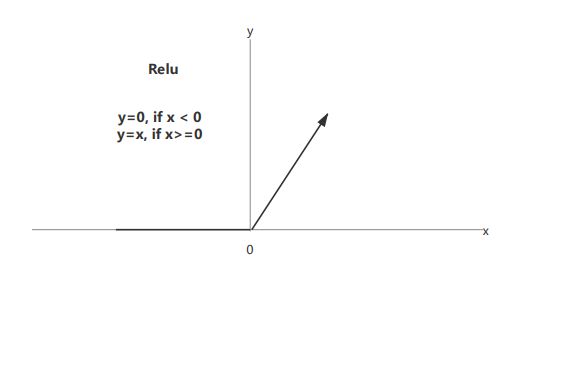
4.Relu
上面提到sigmoid和tanh激励函数容易导致多层神经网络模型在训练过程中出现梯度消失的现象。为此,有人提出了Relu激励函数来弥补它们的不足之处,因此relu函数及其变种(leaky relu 、pre relu等)经常放在多层神经网络的中间层。
且relu函数的计算速度比sigmoid和tanh快。从下图可知,relu函数只需要判断神经元的输出值是否小于0,然后输出相应的值即可,因此整体网络的收敛速度会比较快。
损失函数
![]()
在谈及损失函数之前,我们先复习下整个神经网络的训练过程。它是基于梯度下降的方法去不断缩小预测值与真实值之间差值的过程。而这个差值就是损失(loss),计算这个损失的函数就是损失函数(loss function)了。且损失函数是和神经网络输出层的激励函数相配套的。下面博主根据我们训练的任务来讲解常见的损失函数。
1.回归任务
损失函数(loss function):mse
输出层配套激励函数:linear, sigmoid, tanh
输出层神经元个数:1个
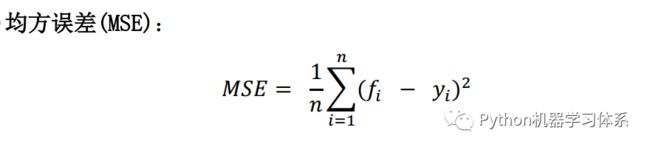
其中, fi是模型预测值,yi是实际值,通过计算两者的均方误差来衡量模型的有效性。
2.二分类任务
损失函数:binary_crossentropy
输出层配套激励函数:softmax
输出层神经元个数:2个
损失函数:binary_crossentropy
输出层配套激励函数:sigmoid or tanh
输出层神经元个数:1个
这个损失函数(二分类交叉熵)要求训练样本标签必须为独热编码(one hot encode),拟合损失的过程在上文有写,这里就不赘述了。
3.多分类任务
损失函数:categorical_crossentropy
输出层配套激励函数:softmax
输出层神经元个数:几分类便对应几个神经元
这个损失函数(多分类交叉熵)要求训练样本标签(label)必须为独热编码(one hot encode),拟合损失的过程在上文有写,这里就不赘述了。
独热编码
损失函数:sparse_categorical_crossentropy
输出层配套激励函数:softmax
输出层神经元个数:几分类便对应几个神经元
这个损失函数与(多分类交叉熵)相同,不过要求训练样本标签(label)必须为数字编码。

数字编码
Bilibili视频
![]()
视频卡顿?bilibili值得拥有~(っ•̀ω•́)っ✎⁾⁾ 我爱学习
https://www.bilibili.com/video/av61427973/
总结
![]()
好了,到这里,结合码前须知---TensorFlow超参数的设置这篇推文,博主已经将深度学习的超参数的知识点讲解完了。大家在掌握了整体的超参数设置的知识体系后,就可以构建神经网络模型时添加适当的超参数,让整模型的训练更加的高效,从而得到更加准确的结果。
当然啦,小伙伴们也可以创造属于自己的激励函数或者损失函数,要是能设计出比常用的还要优秀的函数,这就是轰动AI领域的大事了。
如果需要,小伙伴们可以去keras官网查看更多的参数含义与用途,不过博主建议大家在需要的时候去翻阅一下即可,因为几乎不可能都记住的。
Keras官网
https://keras.io/
如果本期推文有用,那就点个赞吧,你们的点赞是博主持续更新的动力,感谢每一位小伙伴的关注~
图片来源于网络,侵删
留言
![]()
博主刚弄的一个留言功能,欢迎各位小伙伴踊跃留言~


