迷糊糊的Trie树 - 中英文字典树
英文字典树
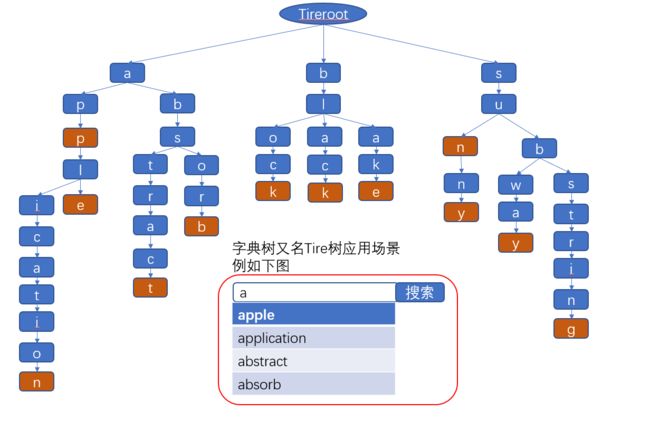
英文字典树的结构图是这样的。按照树型结构存储字符串,每个结点存一个字符,自顶向下做标记的就是词的词尾,比如,app,apple,application,abstract,absorb,block,black,blake... 等等
介绍一下英文字典树的结点数据结构:
1.词频 int型变量记录词频
2.结点型数组,长度26下标对应0 - 25(也就是当前字符 ' ? ' - ' a ' 用字符ASCII码做运算,值域 0 - 25)
3.flag标记,当前结点是否构成单词
4.结点值
中文字典树:
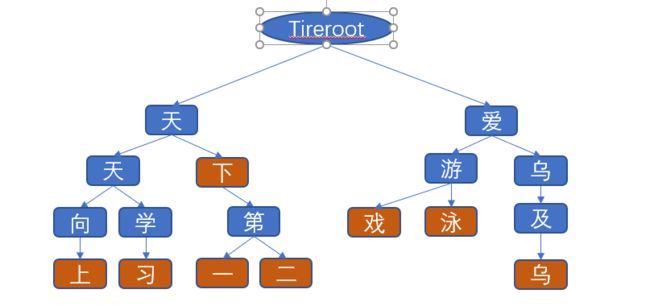
结构和英文字典树相似,但是因为中文的原因,我们没有使用数组,用字符+-的方式来计算显然不行了。所以这里我用的hashmap存的下一位的孩子们。
看一下中文字典树的图:
数据结构:
public Integer frequency; //词频
public Boolean isWords; //是否是词
public Character values; //值
public HashMap childNodes ; //孩子们
插入:
拿到一个词,拆开,从词的第一个字开始找,找到了就拿第二个字继续往下找,找不到拿当前做比较的字开辟结点。
插入时注意好维护每个结点的词频,而且还要看是否是最后一个字,插入最后一个字的时候要标记当前字为词结点。
查找:
也就是拿词拆开,挨个比较,找到了就输出并返回true。
删除词:
在找词的过程中把孩子 > 1的结点压入栈,找到词后把栈顶元素和当前词相关的元素抹去就ok了。

中文字典树源代码:
package com.cccl.datastruct.Tree.tiretree;
import com.cccl.datastruct.queue.MyLinkedQueue;
import java.util.*;
public class Trie {
private static Integer[] level = { 1,0,0,0, 0,0,0,0 }; //trie树 词应该不会超过8的长度 树也最高也就五六层 词语
private TrieNode trieRoot;
public Trie(){
trieRoot = new TrieNode();
trieRoot.frequency = 0;
}
/**
* 插入中文词组
* @param data
* @return
*/
public Boolean insert(String data){
ArrayList arrays = toStringArrays(data);
TrieNode point = trieRoot;
TrieNode nextChild = null;
String nowArraysStr = "";
for (int i = 0; i < arrays.size(); i++) {
point.frequency++;
nowArraysStr = arrays.get(i);
nextChild = point.childNodes.get(nowArraysStr);
if (nextChild == null){
TrieNode addTire = new TrieNode(nowArraysStr.charAt(0));
if (i == arrays.size()-1){
addTire.isWords = true;
addTire.frequency = 1;
point.childNodes.put(nowArraysStr,addTire);
level[i+1]++;
break;
}
point.childNodes.put(nowArraysStr,addTire);
level[i+1]++;
point = addTire;
}else {
point = nextChild;
}
}
return true;
}
/**
* 查询词组
* @param data
* @return
*/
public Boolean searchWords(String data){
ArrayList arrays = toStringArrays(data);
TrieNode point = trieRoot;
TrieNode nextChild = null;
String s = "";
for (int i = 0; i < arrays.size(); i++) {
nextChild = point.childNodes.get(arrays.get(i));
if (nextChild == null){
return false;
}else {
point = nextChild;
showPointInfo(point);
s += point.values;
}
}
System.out.println(s);
return true;
}
/**
* 查询前缀词频
* @param data
* @return
*/
public boolean searchPreWord(String data){
ArrayList arrays = toStringArrays(data);
TrieNode point = trieRoot;
TrieNode nextChild = null;
String s = "";
for (int i = 0; i < arrays.size(); i++) {
nextChild = point.childNodes.get(arrays.get(i));
if (nextChild == null){
System.out.println("没有此前缀!");
return false;
}else {
point = nextChild;
}
}
showPointInfo(point);
return true;
}
/**
* 层序遍历trie树
*/
public void showTrieTree(){
TrieNode point = trieRoot;
MyLinkedQueue queue = new MyLinkedQueue();
queue.enQueue(point);
Integer lev = 0;
Integer count = 0;
while (queue.getCount()>0){
TrieNode trieNode = queue.deQueue();
Collection childs = trieNode.childNodes.values();
Iterator iterator = childs.iterator();
while (iterator.hasNext()){
queue.enQueue(iterator.next());
}
System.out.print(trieNode.values + " ");
count++;
if (count == level[lev]){
System.out.println();
lev++;
count = 0;
}
}
}
/**
* 主函数
* @param args
*/
public static void main(String[] args) {
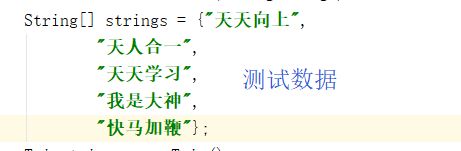
String[] strings = {"天天向上","天人合一","天天学习","我是大神","快马加鞭"};
Trie trie = new Trie();
for (String s:
strings) {
trie.insert(s);
}
// trie.searchWords("天天向上");
// trie.searchPreWord("天天");
trie.showTrieTree();
}
public class TrieNode {
public TrieNode(){
childNodes = new HashMap(8);
isWords = false;
frequency = 0;
values = '根';
}
public TrieNode(Character data) {
childNodes = new HashMap(8);
isWords = false;
frequency = 0;
values = data;
}
public Integer frequency;
public Boolean isWords;
public Character values;
public HashMap childNodes ;
@Override
public String toString() {
return "TrieNode{" +
"frequency=" + frequency +
", isWords=" + isWords +
", values=" + values +
", childNodes=" + childNodes.toString() +
'}'+'\n';
}
}
private void showPointInfo(TrieNode point){
System.out.println("当前 结点值:" + point.values);
System.out.println("当前结点词频:" + point.frequency);
System.out.print("当前结点孩子:");
Set chs = point.childNodes.keySet();
Iterator iterator = chs.iterator();
while (iterator.hasNext()){
System.out.print(" " + iterator.next());
}
System.out.println();
}
private static ArrayList toStringArrays(String data){
ArrayList result = new ArrayList(data.length());
for (int i = 0; i < data.length(); i++) {
result.add("" + data.charAt(i));
}
return result;
}
@Override
public String toString() {
return "Trie{" +
"trieRoot=" + trieRoot.toString() +
'}';
}
}
因为层序遍历用到了队列,队列代码:
package com.cccl.datastruct.queue;
/**
* Created by 小H on 2018/3/21.
*/
public class MyLinkedQueue {
public Node front = null;
public Node rear = null;
private Integer count = 0;
public Integer getCount() {
return count;
}
public MyLinkedQueue(){
initQueue();
}
/**
* 初始化队列
*/
private void initQueue(){
front = new Node();
rear = front;
}
/**
* 销毁队列
*/
public void destroyQueue(){
front = null;
rear = null;
}
/**
* 入队
* @param data
* @return
*/
public boolean enQueue(T data){
try {
Node node = new Node(data);
node.pre = rear;
rear.next = node;
rear = rear.next;
count++;
return true;
}catch (Exception e){
e.printStackTrace();
return false;
}
}
/**
* 出队
* @return
*/
public T deQueue(){
try {
if(front == rear) {
System.out.println("没有元素了,不能出队了");
return null;
}
front = front.next;
count--;
return front.data;
}catch (Exception e){
e.printStackTrace();
return null;
}
}
/**
* 返回队头元素
* @return
*/
public T getQueue(){
try {
if(front == rear) {
System.out.println("没有元素了,不能找到队头元素了");
return null;
}
return front.next.data;
}catch (Exception e){
e.printStackTrace();
return null;
}
}
private static class Node{
public Node pre = null;
public Node next = null;
public T data = null;
public Node(){}
public Node(T d){
data = d;
}
}
}