SPARK随手笔记
大数据工作笔记 – Spark 篇
Spark Terms
- Driver the process running the main() function of the application, and creating spark context(DagSchedular and TaskSchedular). this is a application level process.
- Yarn Application master (application level service) is a lightweight process that coordinates the execution of tasks of an application and asks the resource manager for resource containers for tasks. it monitor tasks, restarts failed ones, etc. it can run any type of tasks, be them MapReduce tasks or spark tasks.
- Master is the cluster manager of spark standalone cluster, it is an external long running service for acquiring resources on cluster(e.g. standalone, mesos, yarn) at cluster level. Master webui
is the web UI sever for the standalone master
INFO Master: Starting Spark master at spark://japila.local:7077
INFO Master: Running Spark version 1.6.0-SNAPSHOT
Spark Deploy Mode
-
Standalone (Cluster) - spark manage everything/cluster by itself (e.g. cluster manager(master), slaves node). This mode requires each application to run an executor on every node in the cluster by default.
- it will acquire all cores by default in the cluster , which only make sense if you just run one application at a time. you can limit the number of cores by setting spark.cores.max in sparkconf.
- alternatively add following to conf/spark-env.sh on the cluster master process to change the default for application that doesn’t set
spark.cores.max.
export SPARK_MASTER_OPTS="-Dspark.deploy.defaultCores="
-
Yarn - utilizing yarn resource manager
-
Client - when your application is submitted from machine that is physically co-located with your worker machines. Driver is launched directly within the spark-submit process which act as a client to cluster.
-
Cluster - when your application is submitted remotely (e.g. locally from laptop), it is common to use luster mode to minimize network latency between the driver and executor.
-
-
Mesos (TBD)
Spark Yarn Cluster Mode Work Flow
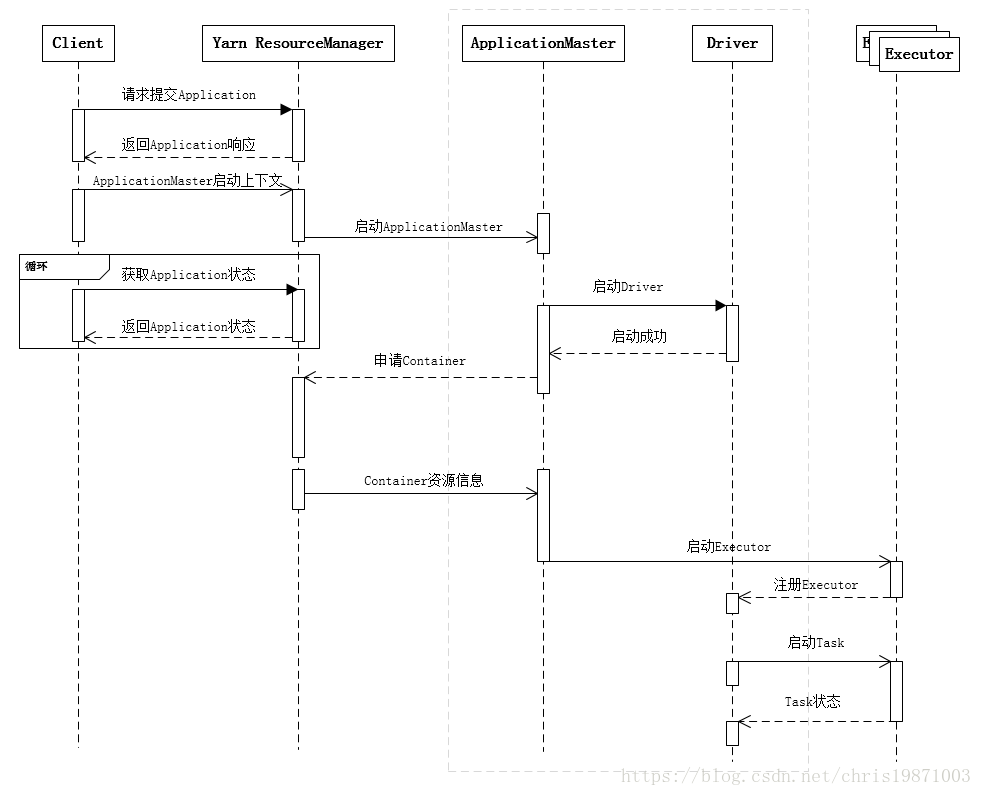
YARN ResourceManager manages the global assignment of compute resources to applications, e.g. memory, cpu, disk, network, etc.
- An application is a YARN client program that is made up of one or more tasks. it can be written in java, scala or Python.
- For each running application, a special piece of code called an ApplicationMaster helps coordinate tasks on the YARN cluster. The ApplicationMaster is the first process run after the application starts.
- An application in YARN comprises three parts:
- The application client, which is how a program is run on the cluster.
- An ApplicationMaster which provides YARN with the ability to perform allocation on behalf of the application.
- One or more tasks that do the actual work (runs in a process) in the container allocated by YARN.
- An application running tasks on a YARN cluster consists of the following steps:
- The application starts and talks to the ResourceManager (running on the master) for the cluster.
- The ResourceManager makes a single container request on behalf of the application.
- The ApplicationMaster starts running within that container.
- The ApplicationMaster requests subsequent containers from the ResourceManager that are allocated to run tasks for the application. Those tasks do most of the status communication with the ApplicationMaster.
- Once all tasks are finished, the ApplicationMaster exits. The last container is de-allocated from the cluster.
- The application client exits. (The ApplicationMaster launched in a container is more specifically called a managed AM).
- The ResourceManager, NodeManager, and ApplicationMaster work together to manage the cluster’s resources and ensure that the tasks, as well as the corresponding application, finish cleanly.
Spark Dataset
- Dataset is introduced in spark release 21.6, and only available in Scala and Java.
- Spark dataset provides type-safe and object oriented programming interface.
it is a strongly typed collection of domain-specified objects that can be transformed in parallel using functional or relational operations. Also, performance benefits of the catalyst query optimizer and of a dataframe API. - Dataset also have an untyped view called a Dataframe, which is Dataset of Row.
- Operations available on Dataset are divided into transformations (e.g. map, filter, select, aggregate) and actions (e.g. show, count or writing data to file). Transformations are the ones that produce new Dataset, on the other hand actions are responsible for trigger computation and return result.
- Datasets are “lazy”, computations and transformations are only triggered when an action is invoked. For example, function in map() or filter() only triggered by action like show() or count();
- to efficiently support domain-specific object, an Encoder is required, the encoder maps the domain specific type T to spark internal type system.
Spark Transformation
When using custom MapPartitionsFunction
Spark streaming
Spark Streaming receives live input data streams and divides the data into batches
Spark load file format
- make sure use correct file format for input file.
For example, if you use “com.databricks.csv” for txt file without specify any delimiter, it will split row items use coma separator by default. - spark only support single character separator, so if your file use multiple character delimiter, you can load file as text file and foreach partition of Dataset, apply custom logic to split line into list.
Spark Main not found when running oozie job
java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.oozie.action.hadoop.SparkMain not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2349)
at org.apache.oozie.action.hadoop.LauncherMapper.map(LauncherMapper.java:233)
at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:54)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:459)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:343)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1924)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
Caused by: java.lang.ClassNotFoundException: Class org.apache.oozie.action.hadoop.SparkMain not found
at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:2255)
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2347)
make sure spark version under sharelib for oozie is same as version of spark job
spark-submit cannot find class which is specified by command line
- Cause: Using springboot fat jar plugin in maven, and all class files are placed under boot-info folder, which spark-submit cannot find it.
- solution: switched to maven shade plugin to package jar
Oozie spark action
${jobTracker}
${nameNode}
yarn
cluster
Fim validation
com.anz.pdl.validator.fim.Application
${nameNode}/user/xxxx/lib/xxxx.jar
-D
fim.input=${nameNode}/user/xxx/xxx
-D
fim.output=${nameNode}/user/xxx/xxx/output
- if jar file use apache common command line lib, remember to split arg
into two lines
- remember to have jar file lib folder
Spark map, mapPartitions calculate repeatedly
have to cache or persist map result, with persist specific storage level can be defined
Spark persist and cache
One of the most important capabilities in Spark is persisting (or caching) a dataset in memory across operations.
spark cache is fault-tolerant if any partition of an RDD is lost, it will automaticaly be recomputed using the transformations that originally created it.
use rdd.unpersisit() to remove a rdd manually.
Spark standalone cluster mode supervise flag
Spark standalone cluster mode supports restarting application automatically if it exited with non-zero exist code. you may pass -supervise flag to spark-submit when launching application.
Kryo Serialization
Serialization is happening when cache or persist rdd to disk (Note - not include of memory) and shuffles data between nodes.
if no explicit registration of custom classes, kryo will still work, but it will have to store the full class name with each object, which is not ideal.
Spark repartition and coalesce
Repartition and coalesce can cause a shuffle.
Shuffle is an expensive operation since it involves disk I/O, data serialization and network I/O
Coalesce cannot increase partition, but repartition can.
Spark shared variables
spark provide two limited types of shared variables for two common usage patterns: broadcast and accumulators.