决策树分类与回归 手动实现
决策树离散值分类
path = "xigua.csv"
import pandas as pd
df = pd.read_csv(path,na_values='?')
#计算占比
def calculate_f(feature,value,df):
data = df[df[feature] == value]
f = len(data)/len(df)
return f
#计算熵
import math
def calculate_ent(list_f):
ent = 0
for f in list_f:
ent += f * math.log(f,2)
return -ent
# #计算根结点中label=0的占比
f1 = calculate_f('label',0,df)
# #计算根结点中label=1的占比
f2 = calculate_f('label',1,df)
#计算根结点香农熵
ent = calculate_ent([f1,f2])
##获取x1=青绿的样本集合
df1 = df[df['x1']== '青绿']
# 计算x1=青绿的样本集合下label=0的占比
f1 = calculate_f('label',0,df1)
#计算x1=青绿的样本集合下label=1的占比
f2 = calculate_f('label',1,df1)
#计算x1=青绿的样本集合下香农熵
ent1 = calculate_ent([f1,f2])
#获取x1=乌黑的样本集合
df2 = df[df['x1']== '乌黑']
#计算x1=乌黑的样本集合下label=0的占比
f1 = calculate_f('label',0,df2)
#计算x1=乌黑的样本集合下label=1的占比
f2 = calculate_f('label',1,df2)
#计算x1=乌黑的样本集合下香农熵
ent2 =calculate_ent([f1,f2])
##获取x1=浅白的样本集合
df3 = df[df['x1']== '浅白']
##计算x1=浅白的样本集合下label=0的占比
f1 = calculate_f('label',0,df3)
##计算x1=浅白的样本集合下label=1的占比
f2 = calculate_f('label',1,df3)
##计算x1=浅白的样本集合下香农熵
ent3 = calculate_ent([f1,f2])
##计算香农熵增益
result = ent -len(df1)/len(df)*ent1 - len(df2)/len(df)*ent2-len(df3)/len(df)*ent3
result
决策树连续值分类
path = "xigua.csv"
import pandas as pd
df = pd.read_csv(path,na_values='?')
#计算占比
def calculate_f(feature,value,df):
data = df[df[feature] == value]
f = len(data)/len(df)
return f
#计算熵
import math
def calculate_ent(list_f):
ent = 0
for f in list_f:
ent += f * math.log(f,2)
return -ent
#按照密度进行排序
df = df.sort_values(by = 'x2')
# #计算根结点中label=0的占比
f1 = calculate_f('label',0,df)
# #计算根结点中label=1的占比
f2 = calculate_f('label',1,df)
#计算根结点香农熵
ent = calculate_ent([f1,f2])
import math
max_gain = 0
for i in range(len(df)-1): #遍历所有划分点
df1 = df[0:i+1] #获取左子树的样本
f1 = len(df1[df1['label']==0])/len(df1) # 计算样本左子树中label=0的占比
f2 = 1-f1# 计算左子树中label=1的占比
if f1 ==0:
f1 = 0.00001
if f2 ==0:
f2 = 0.00001
ent1 = -1 *(f1*math.log2(f1) + f2*math.log2(f2))# 计算左子树的香农熵
df2 = df[i+1:len(df)]#获取右子树的样本
f1 =len(df2[df2['label']==0])/len(df2) # 计算样本右子树中label=0的占比
f2 = 1-f1 # 计算右子树中label=1的占比
if f1 ==0:
f1 = 0.00001
if f2 ==0:
f2 = 0.00001
ent2 = -1 *(f1*math.log2(f1) + f2*math.log2(f2))# 计算右子树的香农熵
result = ent -len(df1)/len(df)*ent1 - len(df2)/len(df)*ent2
if(result > max_gain):
max_gain = result
print(max_gain) 决策树连续值回归
import pandas as pd
import numpy as np
path = "xigua.csv"
df = pd.read_csv(path,na_values='?')
#按照密度进行排序
df = df.sort_values(by = 'x2')
ent = np.var(df['score'])
for i in range(len(df)-1): #遍历所有划分点
df1 = df[0:i+1] #获取左子树的样本
ent1 = np.var(df1['score'])#计算离差平方和
df2 = df[i+1:len(df)]#获取右子树的样本
ent2 = np.var(df2['score'])#计算离差平方和
result = ent -len(df1)/len(df)*ent1 - len(df2)/len(df)*ent2
# print(ent1,ent2)
print(result)直接调库
import pandas as pd
from math import log2
path = "xigua.csv"
df = pd.read_csv(path)
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor(max_depth=1)
model.fit(df[["x2"]],df["score"])
from IPython.display import Image
from sklearn import tree
import pydotplus
dot_data = tree.export_graphviz(model, out_file=None,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png()) 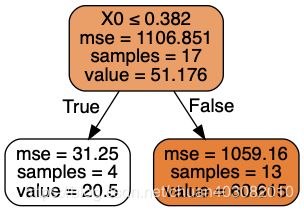
#决策树不能捕获异或关系 异或:相同为1
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
df = pd.DataFrame([[0,0,1],[1,1,1],[1,0,0],[0,1,0]])
X = df.iloc[:,0:-1]
Y = df.iloc[:,-1]
model = DecisionTreeClassifier().fit(X,Y)
model.predict(X)
model
from IPython.display import Image
from sklearn import tree
import pydotplus
dot_data = tree.export_graphviz(model, out_file=None,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png()) 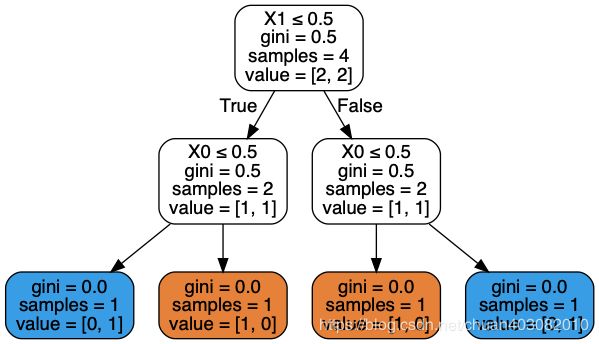
## 编程——决策树综合案例之森林植被类型预测
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
df = pd.read_csv("datas/covtype.data",sep=",",header=None)
## 构建X和Y
X = df.iloc[:,0:-1]
Y = df.iloc[:,-1]
## 划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.3)
model = DecisionTreeClassifier()
model.fit(X_train,Y_train)
print(model.score(X_test,Y_test))
pd.crosstab(Y_test,model.predict(X_test),rownames=["label"],colnames=["predict"])
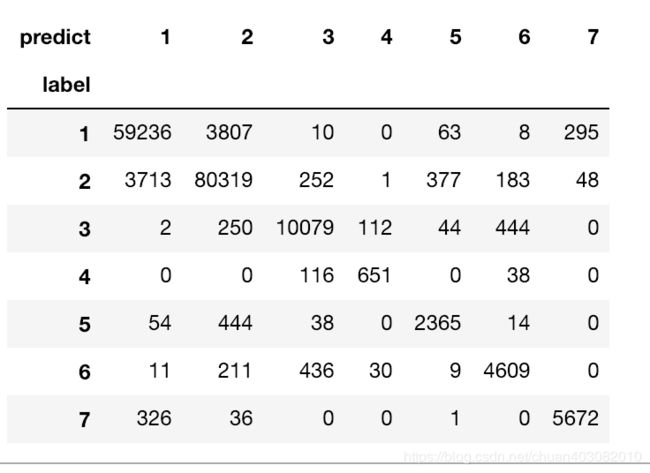
## 编程——决策树回归案例之共享单车租赁数量预测
import pandas as pd
df = pd.read_csv("hour.csv", sep=",")
## 删除无用的列
del df["instant"]
del df["dteday"]
del df["casual"]
del df["registered"]
## 构建X和Y
X = df.iloc[:,0:-1]
Y = df.iloc[:,-1]
## 划分训练集和测试集
from sklearn.model_selection import train_test_split
import numpy as np
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.3)
from sklearn.tree import DecisionTreeRegressor
model = DecisionTreeRegressor()
model.fit(X_train,Y_train)
from sklearn.metrics import mean_squared_error
print("DT:",mean_squared_error(Y_test.values, model.predict(X_test)))