卷积神经网络图像风格转移 Image StyleTransfer Using Convolutional Neural Networks
卷积神经网络图像风格转移
Image StyleTransfer Using Convolutional Neural Networks
Taylor Guo, 2017年4月24日 星期一
摘要
用不同的风格渲染图像的语义内容是一种比较难的图像处理任务。可以说,之前方法的一个主要局限因素是缺乏明确表示语义信息的图像表示,用于将图像内容从风格中分离。这里用卷积神经网络的图像表示用于物体识别的优化,可以使图像信息更明显。我们介绍了一种艺术风格的神经网络算法可以将图像的内容和图像的自然风格分离和再合并。算法可以提供给人们可以感知到的高质量的新图像,可以将大量众所周知的艺术作品和任意图像结合起来。实验结果提供了卷积神经网络学习的深度学习图像表示,展示了高层图像语义合成和操作的能力。
1 简介
将一幅图像的风格转移到另外一幅图像上被认为是一个图像纹理转移问题。在图像纹理转移中,目标是从一幅源图像中合成纹理,源图像提供了要合成的问题但需要保留目标图像的语义内容。对于纹理合成,有大量强有力的非参数方法,可以通过重新采样给定源纹理图像的像素来合成图像写实自然纹理。之前的大多数纹理转移算法都是采用非参数方法用于纹理合成,没有用其他不同方法保留目标图像的结构。例如,Efros和Freeman引入了一个对应地图,包括了目标图像的特征,比如图像亮度,来约束纹理合成过程。Hertzman用图像模拟从风格图像中将纹理转移到目标图像中。Ashikhmin专注转移高频纹理信息,只保留目标图像的粗糙尺度。Lee在纹理转移过程中添加边缘方向信息来增强算法。
尽管这些算法取得了显著的效果,但都受限于同一个基本问题:它们只使用了目标图像的低层图像特征在纹理转移中。理想情况下,一个风格转移算法应该能够从目标图像中提取图像语义内容(比如,目标和一般场景),通知纹理转移流程根据源图像风格渲染目标图像的语义内容。因此,一个先决条件是要找到图像表示,可以独立对图像语义内容和风格构建模型变量。这样处理的表示方法之前只能是采用自然图像的控制子集来达到,比如不同光照条件的人脸,和不同字体的特征,或者手写数字和门牌号。
但一个通用性的方法将图像的内容从风格中分离开仍然是一个非常困难的问题。然而,最近出现的深度卷积神经网络可以产生强大的计算机视觉系统,可以从图像中学习提取高层语义信息。采用充足标注的数据训练的卷积神经网络在特定任务中,比如物体识别,在一般的特征表示中学习提取高层图像内容,可以在数据集上泛化,甚至也可以应用于其他视觉信息处理任务,包括纹理识别和艺术风格分类。
在这个工作中,我们展示了高性能卷积神经网络如何学习一般的特征表示,用于独立处理和操作图像的内容和风格。我们介绍了艺术风格神经网络算法,一种执行图像风格转移的新算法。思路上,它就是最新的卷积神经网络的特征表示的纹理合成约束下的纹理转移算法。纹理模型基于深度学习图像表示,风格转移方法巧妙地将优化问题减少到一个神经网络中。通过执行图像搜索匹配样本图像的特征表示来生成新图像。再纹理合成之前执行这个方法,增强对深度学习图像表示的理解。事实上,风格转移算法合并了基于图像表示翻转的卷积神经网络的参数纹理模型。
2 深度学习图像表示
以下展示的结果是基于论文28的VGG网络生成的,用于训练执行物体识别和定位,更多细节如论文所示。使用标准的19层VGG网络包含16个卷积层和5个池化层提供的特征空间。按比例改变权重规范化网络,这样每层卷积滤波器在图像和位置上平均激活值就等于1。这种针对VGG网络的按比例缩放不会改变它的输出,因为它只包含修正线性激活函数,在特征地图上没有归一化层和池化层。我们也不使用任何全连接层。模型是公开的,可以在caffe架构中找到。对于图像合成,我们发现用平均池化取代最大池化操作,生成的结果更好,这就是图像使用平均池化层来生成。
2.1 内容表示
通常网络中每层定义了一个非线性滤波,它的复杂度随着每层在网络中的位置而增加。给定一个图像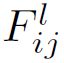 是l层的位置j上的第i个滤波器的激活值。
是l层的位置j上的第i个滤波器的激活值。
为了将图像信息可视化在层级结构的不同层上进行编码,可以在一个带有白噪声的图像上执行梯度下降算法寻找可以匹配原始图像特征响应的另外一个图像(参考图1的内容重建),如论文24所述。令
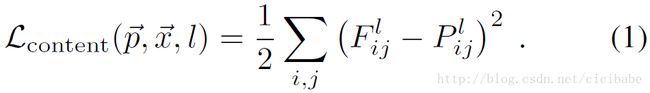
损失函数的偏导数对应的l层的激活函数为:
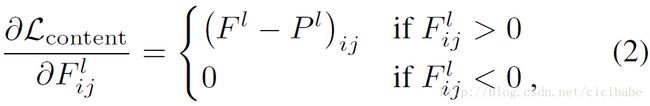
图像![]() 的梯度可以用标准误差反馈传播计算(如图2右侧)。因此,我们可以改变初始随机图像
的梯度可以用标准误差反馈传播计算(如图2右侧)。因此,我们可以改变初始随机图像![]() 直到卷积神经网络的某一层可以生成与原始图像
直到卷积神经网络的某一层可以生成与原始图像![]() 相同的响应。
相同的响应。
图1. 卷积神经网络中的图像表示。在卷积神经网络的每个处理阶段,一个给定的输入图像表示为滤波过的图像。滤波器的数量沿着处理的层级增加,滤波后的图像用某种降采样机制减少(比如,最大池化),可以减少网络中每层的总数量。内容表示:可以从特定的一个网络层上,在只知道网络响应的情况下重建输入图像,就能够在卷积神经网络的不同处理阶段将信息可视化。在原来的VGG网络中的‘conv1 2’ (a), ‘conv2 2’ (b), ‘conv32’ (c), ‘conv4 2’ (d) ‘conv5 2’ (e) 重建输入图像。可以发现从网络中的低层重建接近完美(a-c)。在网络的高层,细节像素信息会丢失,但高层的图像内容会被保留下来(d,e)。风格表示:在卷积神经网络顶层激活时,使用一个特征空间获取输入图像的纹理信息。风格表示计算了卷积神经网络不同层不同特征间的关系。从卷积神经网络层(‘conv1 1’ (a), ‘conv1 1’ 和‘conv2 1’(b),‘conv1 1’, ‘conv2 1’ and ‘conv3 1’ (c), ‘conv1 1’, ‘conv2 1’, ‘conv3 1’ and‘conv4 1’ (d), ‘conv1 1’, ‘conv2 1’, ‘conv3 1’, ‘conv4 1’and ‘conv5 1’ (e))的不同子集上构建的风格表示重建输入图像的风格。这样创建的图像在一个逐步增加的规模上会匹配给定图像的风格,同时会丢掉场景全局结构信息。
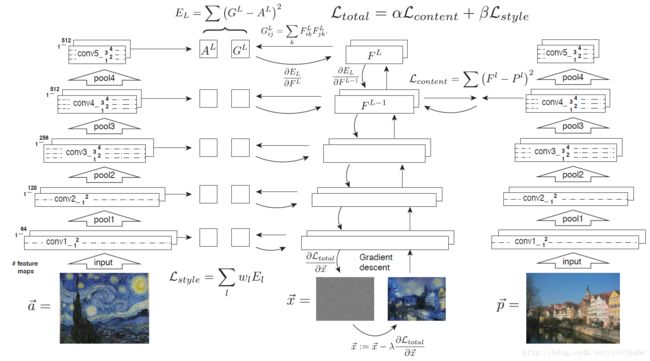
卷积神经网络在物体识别上训练,它们可以生成一个对图像的表示,在网络层级的处理过程中使得物体信息越来越明显,如论文10所示。因此,沿着网络层级处理过程,输入图像会发生转变,对图像的真正内容越来越敏感,但会对精细的外观变得相对不变。网络的高层会捕捉输入图像的高阶内容,比如物体和结构,但不会限制重构过程中的确切像素值(如图1中,内容重建 d,e)。相反,低层重建只是简单地复制原始图像中的确定的像素值(如图1,内容重建 a-c)。我们将网络中高层的特征响应结果作为内容表示。
2.2 风格表示
为了获得输入图像的风格表示,用特征空间获得纹理信息,如论文10所示。这个特征空间可以从网络的任意层中的滤波器响应结果上构建。它由不同滤波器响应结果的相关关系组成,其中期望值从特征地图空间上取值。特征关系用克莱姆矩阵![]() 表示,其中
表示,其中![]() 是l层的向量化特征地图i和j之间的內积:
是l层的向量化特征地图i和j之间的內积:
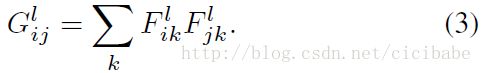
包含了多个网络层的特征相关关系,可以得到一个确定的,多尺度的输入图像的表示,可以获得纹理信息,但没有全局结构信息。同样的,可以匹配给定输入图像的风格表示构建一个图像,可视化在网络不同层构建风格的特征空间上捕捉的信息,(如图1,风格重建)。在白噪声图像上使用梯度下降算法最小化原始图像的克莱姆矩阵和生成图像的克莱姆矩阵的平均平方距离来实现。
令![]() 和
和![]() 分别表示原始图像和生成图像,
分别表示原始图像和生成图像,![]() 和
和![]() 分别表示l层的风格表示。l层相对于总损失的贡献是:
分别表示l层的风格表示。l层相对于总损失的贡献是:
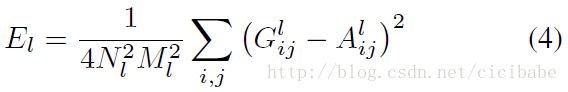
总的风格损失函数:
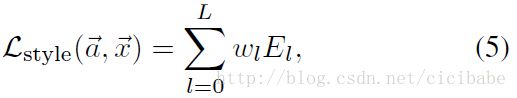
其中wl是每层对总损失函数的贡献权重因子(如下面结果中特定wl的值)。l层的激活函数对应的El的偏导数计算如下:
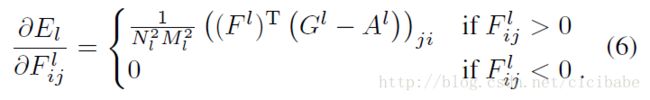
El对像素值![]() 的梯度可以用标准误差反向传播快速计算出来,(如图2 左边所示)。
的梯度可以用标准误差反向传播快速计算出来,(如图2 左边所示)。
2.3 风格转移
为了将艺术照![]() 的风格转移到照片
的风格转移到照片![]() 上,我们同步匹配
上,我们同步匹配![]() 的内容表示和
的内容表示和![]() 的风格表示,合成一个新图像,如图2所示。 因此,可以联立从卷积神经网络的一层的图像内容表示和大量层上定义的绘画风格表示的白噪声图像的特征表示求解最小化距离。需要最小化的损失函数是:
的风格表示,合成一个新图像,如图2所示。 因此,可以联立从卷积神经网络的一层的图像内容表示和大量层上定义的绘画风格表示的白噪声图像的特征表示求解最小化距离。需要最小化的损失函数是:![]()
其中α和β分别是内容和风格重建的权重因子。对像素值的梯度 可以作为某些优化策略的输入值。这里使用论文32中的L-BFGS,可以非常好的应用于图像合成中。为了提取图像信息,在计算特征表示之前,需要经常改变风格图像大小与内容图像大小一样。最后,注意与论文24不同,我们并不用图像信息来规范化合成结果。可以讨论一下,从网络中低层提取的纹理特征可以作为风格图像的特定图像先验信息。另外,使用不同的网络架构和优化算法,在图像合成上也会有不同结果。
可以作为某些优化策略的输入值。这里使用论文32中的L-BFGS,可以非常好的应用于图像合成中。为了提取图像信息,在计算特征表示之前,需要经常改变风格图像大小与内容图像大小一样。最后,注意与论文24不同,我们并不用图像信息来规范化合成结果。可以讨论一下,从网络中低层提取的纹理特征可以作为风格图像的特定图像先验信息。另外,使用不同的网络架构和优化算法,在图像合成上也会有不同结果。
3 结果
本文主要的发现是卷积神经网络中的内容表示和风格表示可以很好地分离。也就是说,可以独立地操作两种表示生产有意义的新图像。为了演示这个发现,我们从两个不同的源图像中生成混合内容表示和风格表示的图像。具体来说,我们匹配了德国图宾根内卡河的照片的内容表示和几种出名的不同时期的艺术画的风格表示,如图3所示。图3所示的图像通过匹配网络层‘conv42’的内容表示和网络层 ‘conv1 1’, ‘conv2 1’, ‘conv3 1’, ‘conv4 1’and ‘conv5 1’(这些层中wl = 1/5, 其他层中 wl = 0 )的风格表示合成图像。α/β的比值分别是1 × 10−3 (Fig 3 B), 8 × 10−4 (Fig 3 C), 5 × 10−3(Fig 3 D), 或者 5 × 10−4 (Fig 3 E, F)。
图3:合并照片内容和几种出名的艺术照生成的照片。同时匹配照片内容表示和艺术绘画的风格表示生成图像。A图是德国图宾根内卡河照片。左下角面板里面提供了生成图像的风格的绘画。B是1805年英国画家约瑟夫·玛罗德·威廉·特纳的《运输船遇难》。C是1889年文森特·梵高《星月夜The Starry Night》。D是1893年爱德华·蒙克《尖叫》。E是1910年巴勃罗·毕加索Femme nue assise 。F是1913年瓦西里·康定斯基CompositionVII。
3.1 内容和风格之间的取舍
当然,图像内容和风格不可能完全解绑。用另外一个图像风格合并一个图像的内容生成新图像时,通常不存在一个图像可以同时完全匹配两种约束。然而,既然在合成图像中,最小化的损失函数是内容和风格损失函数的线性组合,可以平滑地规范化强调内容重建或风格重建,如图4所示。强烈强调风格会导致图像匹配艺术品的外观,有效地提供了一个纹理版本的图像,但几乎没有图像的内容(α/β = 1 × 10−4,如图4,左上)。当强调内容时,可以清晰地识别照片,但绘画的风格无法很好地匹配(α/β = 1 × 10−1,如图4,右下)。对特定的内容图像和风格图像,可以调整内容和风格之间的取舍来创造令人满意的视觉效果的图像。
图4:匹配源图像的内容和风格的相对权重。内容和风格比值α/β从左上到右下依次增加。特别强调风格会生成风格图像的纹理版本(左上)。特别强调内容会生成有很少风格的图像(右下)。实际上,可以在两个极值间平滑插值。
3.2 卷积神经网络不同层的效果
图像合成过程中另外一个重要的因素是选择匹配内容和风格表示的网络层。如上所示,风格表示是一个多尺度表示,包含了神经网络中的多层。这些层的数量和位置决定了风格匹配的局部尺度,产生不同视觉体验(如图1中的风格重建)。我们发现将风格表示匹配到网络的高层在一个增大的尺度上可以保留局部图像结构,生成更平滑、更连续的视觉体验。因此,大部分视觉上令人满意的图像通常是将风格表示匹配到网络高层创建的,这就是为什么我们生成的图像会在网络层‘conv1 1’, ‘conv2 1’, ‘conv3 1’, ‘conv4 1’ 和‘conv5 1’匹配风格特征。
为了分析不同层匹配内容特征的效果,我们在相同艺术图片和参数配置(α/β = 1 × 10−3)情况下对照片风格化,展示了风格转移的结果,但是一个是在conv2_2层上匹配内容特征,在另外一个的conv4_2层上,如图5所示。当在网络的低层上匹配内容,算法会匹配照片上的大部分像素细节信息,生成的图像似乎艺术图的纹理几乎不融合进照片中(如图5中间部分)。相反,在网络高层上匹配内容特征,照片的像素细节信息没有很强的约束,艺术画的纹理和照片的内容恰当地融合在一起(如图5下面)。也就是说,图像中明确的结构,比如边缘和颜色地图会被改变,使用艺术画的风格和照片的内容,如图5下面所示。
图5:网络不同层匹配内容表示的效果。匹配conv2_2的内容保留了原始照片更多的清楚的结构,生成的图像看上去绘画的纹理简单和融合到照片中(图中间所示)。匹配conv4_2层的内容时,绘画的纹理和照片的内容就合并起来,照片的内容就显示出绘画的风格(图中下面所示)。两幅图是用相同的参数(α/β = 1 × 10−3)生成的。绘画作为风格图像,如左下角所示,1915年莱昂内尔·法宁格的Jesuiten III。
3.3 梯度下降初始化
这些图像初始化都带有白噪声。然而,初始化图像时也可以将内容图像和风格图像合成起来。我们也探索了这两种方案(图6A,B):尽管他们对最终图像与初始化时图像在空间结构上有偏向,不同的初始化方法看起来对最后的合成图像的结果并没有很大影响。可以注意到的是带噪声的初始化可以生成任意数量的新图像(图6 C)。带固定图像的初始化完全生产相同的结果(取决于梯度下降过程的随机性)。
图6:梯度下降的初始化。A从内容图像初始化。B从风格图像初始化。C 4个样本从不同的白噪声图像初始哈。对所有图像α/β = 1 × 10−3。
3.4 写实风格转移
到目前为止,本文主要关注艺术风格转移。通常,算法可以在任意两张图像上转移风格。比如,我们可以转移纽约夜晚的风格到伦敦白天的图像上去(图7)。尽管照片的真实度无法弯曲保留,合成的图像非常像风格图像的颜色和光照,显示出伦敦夜晚的照片。

图7. 真实性图像风格转移。从纽约夜晚的照片风格转移到伦敦白天的照片上。图像合成用内容图像初始化,α/β = 1 × 10−2。
4 讨论
本文演示了如何在高性能的卷积神经网络上用特征表示在任意两个图像上转移图像风格。我们可以显示出高感知质量,算法上仍然有一些技术限制。
可能最大的限制是合成的图像的分辨率。优化问题的维度和卷积神经网络中的单元数量都是随着像素数量线性增长的。合成过程的速度严重依赖于图像分辨率。本文中展示的合成照片的分辨率是512×512像素,合成过程在nvidiaK40 GPU上大概1个小时(取决于确切图像大小和梯度下降的停止标准)。这样的性能目前可以在线演示,也可以交互应用,未来深度学习算法的增强都将增加这个方法的性能。
另外一个问题是合成的图像有时会有一些低层噪音。这个问题在艺术风格转移中比较少,当内容图像和风格图像是照片或者生成写实图像受到影响的时候,更加明显。然而,噪声非常有特点,比较像网络中的单元的滤波器。因此,可以构建有效的去噪方法在优化过程结束后对图像进行后处理。
图像的艺术风格处理是计算机图形学的非写实渲染的传统研究问题。与纹理转移工作不同,传统的方法是用特别的算法在一个给定的风格上渲染源图像。最近的综述可以参考论文21。
从风格中分离图像内容在一个定义好的问题上不是必要的。这主要是因为究竟图像风格是什么无法清晰定义。它可能是绘画上笔刷的粗细,色彩地图,某种形式和形状,但也有可能是场景的组成,图像的主题,甚至可能是他们的混合,或许更多。因此,通常图像内容和风格不可能完全清晰地分离,如果可以,又怎么分离呢?比如,如果没有像星星一样的图像结构,就不可能将一副图像渲染成梵高的星月夜。在实际工作中,如果图像看起来像某种风格但图像内容中的物体和场景不同,我们认为风格转移也是成功的。我们完全认识到这种评判标准,在数学上不精确,也不具有通用型。
然而,我们发现一个令人激动的现象,神经系统训练执行生物视觉的一个核心计算任务,可以自动地学习图像表示,至少在某种程度上可以将图像内容从风格上分离。一个可能的解释是当学习物体识别时,网络变得对图像变化具有不变性,保留了物体辨别力。图像内容和外观变化这一任务具有非常强的实践性。优化的人工神经网络和生物视觉有非常惊人的相似之处,因此可以观察人类从风格中提取内容的能力,创造和享受艺术,可能对我们的视觉系统的推理能力非常重要。
Taylor Guo @Shanghai - 2017年4月29日-15:30
参考文献
[1] N. Ashikhmin. Fast texture transfer. IEEE Computer Graphics and Applications,23(4):38–43, July 2003. 1
[2] M. Berning, K. M. Boergens, and M. Helmstaedter.SegEM: Efficient Image Analysis for High-Resolution Connectomics. Neuron,87(6):1193–1206, Sept. 2015. 2
[3] C. F. Cadieu, H. Hong, D. L. K. Yamins, N. Pinto,D. Ardila, E. A. Solomon, N. J. Majaj, and J. J. DiCarlo. Deep Neural NetworksRival the Representation of Primate IT Cortex for Core Visual ObjectRecognition. PLoS Comput Biol, 10(12):e1003963, Dec. 2014. 8
[4] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy,and A. L. Yuille.SemanticImage Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv:1412.7062 [cs], Dec. 2014. arXiv: 1412.7062. 2
[5] M. Cimpoi, S. Maji, and A. Vedaldi. Deep filter banks for texture recognition andsegmentation.In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,pages 3828–3836, 2015. 2
[6] J. Donahue, Y. Jia, O. Vinyals, J. Hoffman, N.Zhang, E. Tzeng, and T. Darrell.DeCAF:A Deep Convolutional Activation Feature for Generic Visual Recognition. arXiv:1310.1531 [cs], Oct. 2013. arXiv: 1310.1531. 2
[7] A. Efros and T. K. Leung. Texture synthesis by nonparametric sampling. In Computer Vision, 1999. The Proceedings of theSeventh IEEE International Conference on, volume 2, pages 1033–1038. IEEE,1999. 1
[8] A. A. Efros and W. T. Freeman. Image quilting for texture synthesis and transfer. In Proceedings of the 28th annual conference onComputer graphics and interactive techniques, pages 341–346. ACM, 2001. 1
[9] D. Eigen and R. Fergus. Predicting Depth, SurfaceNormals and Semantic Labels With a Common Multi-Scale Convolutional Architecture.pages 2650–2658, 2015. 2
[10] L. A. Gatys, A. S. Ecker, and M. Bethge. Texture Synthesis Using Convolutional Neural Networks. In Advances in Neural Information Processing Systems28, 2015. 3, 4
[11] U. G¨uc¸l ¨u and M. A. J. v. Gerven. Deep NeuralNetworks Reveal a Gradient in the Complexity of Neural Representations acrossthe Ventral Stream. The Journal of Neuro-science, 35(27):10005–10014, July2015. 8
[12] D. J. Heeger and J. R. Bergen. Pyramid-based Texture Analysis/Synthesis. In Proceedings of the 22Nd Annual Conference onComputer Graphics and Interactive Techniques, SIGGRAPH ’95, pages 229–238, New York,NY, USA, 1995. ACM. 3
[13] A. Hertzmann, C. E. Jacobs, N. Oliver, B.Curless, and D. H. Salesin.Image analogies. In Proceedings of the 28th annual conference onComputer graphics and interactive techniques, pages 327–340. ACM, 2001. 1
[14] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J.Long, R. Girshick, S. Guadarrama, and T. Darrell.Caffe:Convolutional architecture for fast feature embedding. In Proceedings of the ACM International Conferenceon Multimedia, pages 675–678. ACM, 2014. 3
[15] S. Karayev, M. Trentacoste, H. Han, A. Agarwala,T. Darrell, A. Hertzmann, and H. Winnemoeller.Recognizing image style. arXiv preprint arXiv:1311.3715, 2013. 2
[16] S.-M. Khaligh-Razavi and N. Kriegeskorte. DeepSupervised, but Not Unsupervised, Models May Explain IT Cortical Representation.PLoS Comput Biol, 10(11):e1003915, Nov. 2014. 8
[17] D. P. Kingma, S. Mohamed, D. Jimenez Rezende, andM. Welling. Semi-supervised Learning with Deep Generative Models. In Z.Ghahramani, M.Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger,editors, Advances in Neural Information Processing Systems 27, pages 3581–3589.Curran Associates, Inc., 2014. 2
[18] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neuralnetworks. In Advancesin neural information processing systems, pages 1097–1105, 2012. 2
[19] M. K¨ummerer, L. Theis, and M. Bethge. Deep GazeI: Boosting Saliency Prediction with Feature Maps Trained on ImageNet. In ICLRWorkshop, 2015. 2, 8
[20] V. Kwatra, A. Sch¨odl, I. Essa, G. Turk, and A.Bobick. Graphcut textures: image and video synthesis usinggraph cuts.In ACM Transactions on Graphics (ToG), volume 22, pages 277–286. ACM, 2003. 1
[21] J. E. Kyprianidis, J. Collomosse, T. Wang, and T.Isenberg. Stateof the ”Art”: A Taxonomy of Artistic Stylization Techniques for Images andVideo. Visualizationand Computer Graphics, IEEE Transactions on, 19(5):866–885, 2013. 8
[22] H. Lee, S. Seo, S. Ryoo, and K. Yoon. DirectionalTexture Transfer. In Proceedings of the 8th International Symposium onNon-Photorealistic Animation and Rendering, NPAR ’10, pages 43–48, New York,NY, USA, 2010. ACM. 1
[23] J. Long, E. Shelhamer, and T. Darrell. Fully Convolutional Networks for SemanticSegmentation. pages3431–3440, 2015. 2
[24] A. Mahendran and A. Vedaldi. Understanding Deep Image Representations by Inverting Them. arXiv:1412.0035 [cs], Nov. 2014. arXiv: 1412.0035.3, 6
[25] J. Portilla and E. P. Simoncelli. A Parametric Texture Model Based on Joint Statisticsof Complex Wavelet Coefficients. International Journal of Computer Vision,40(1):49–70, Oct. 2000. 3, 4
[26] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh,S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L.Fei-Fei.ImageNet Large Scale Visual Recognition Challenge. arXiv:1409.0575 [cs], Sept. 2014. arXiv: 1409.0575.3
[27] K. Simonyan, A. Vedaldi, and A. Zisserman. DeepInside Convolutional Networks: Visualising Image Classification Models andSaliency Maps. arXiv:1312.6034 [cs], Dec. 2013. 3
[28] K. Simonyan and A. Zisserman. Very DeepConvolutional Networks for Large-Scale Image Recognition. arXiv:1409.1556 [cs],Sept. 2014. arXiv: 1409.1556. 3
[29] J. B. Tenenbaum and W. T. Freeman. Separatingstyle and content with bilinear models. Neural computation, 12(6):1247–1283,2000. 2
[30] L. Wei and M. Levoy. Fast texture synthesis using tree structured vectorquantization.In Proceedings of the 27th annual conference on Computer graphicsand interactive techniques, pages 479–488. ACM Press/Addison-Wesley PublishingCo., 2000. 1
[31] D. L. K. Yamins, H. Hong, C. F. Cadieu, E. A.Solomon, D. Seibert, and J. J. DiCarlo. Performance-optimized hierarchical modelspredict neural responses in higher visual cortex. Proceedings of the NationalAcademy of Sciences, page 201403112, May 2014. 8
[32] C. Zhu, R. H. Byrd, P. Lu, and J. Nocedal.Algorithm 778: L-BFGS-B: Fortran subroutines for large-scale bound constrained optimization. ACM Transactions on Mathematical Software (TOMS),23(4):550–560, 1997. 6