超参数搜索之网格搜索与并行搜索
超参数搜索
:
所谓的模型配置,一般统称为模型的超参数(Hyperparameters),比如KNN算法中的K值,SVM中不同的核函数(Kernal)等。多数情况下,超参数等选择是无限的。在有限的时间内,除了可以验证人工预设几种超参数组合以外,也可以通过启发式的搜索方法对超参数组合进行调优。称这种启发式的超参数搜索方法为网格搜索。
网格搜索
由于超参数的空间是无尽的,因此超参数的组合配置只能是“更优”解,没有最优解。通常,依靠网格搜索(Grid Search)对各种超参数组合的空间进行暴力搜索。每一套超参数组合被代入到学习函数中作为新的模型,并且为了比较新模型之间的性能,每个模型都会采用交叉验证的方法在多组相同的训练和开发数据集下进行评估。
Python源码:
#coding=utf-8
from sklearn.datasets import fetch_20newsgroups
import numpy as np
from sklearn.cross_validation import train_test_split
from sklearn.svm import SVC
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.pipeline import Pipeline
from sklearn.grid_search import GridSearchCV
#-------------download data
news=fetch_20newsgroups(subset='all')
#-------------select front 3000 data,split data,25% for test
X_train,X_test,y_train,y_test=train_test_split(news.data[:3000],news.target[:3000],test_size=0.25,random_state=33)
#-------------use Pipeline to simplify processing flow,contact wordsVectorizer with classifier model
clf=Pipeline([('vect',TfidfVectorizer(stop_words='english',analyzer='word')),('svc',SVC())])
#-------------create geometric progression,total 4*3 =12 parameters combination
parameters={'svc__gamma':np.logspace(-2,1,4),'svc__C':np.logspace(-1,1,3)}
gs=GridSearchCV(clf,parameters,verbose=2,refit=True,cv=3)
time_=gs.fit(X_train,y_train)
gs.best_params_,gs.best_score_
print 'Best accuracy is:',gs.score(X_test,y_test)

输出说明:使用单线程的网格搜索技术对Naive Bayes Model在文本分类任务中的超参数组合进行调优,共有12组超参数X3折交叉验证=36项独立运行的计算任务。该过程一共进行了3.2min,寻找到的最佳的超参数组合在测试集上所能达成的最高分类准确性为82.27%
由于超参数的验证过程之间彼此独立,因此为并行计算提供了可能。
下面展示如何在在不损失搜索精度的前提下,充分利用多核处理器成倍节约计算时间。
并行搜索
网格搜索结合交叉验证的方法,寻找更好的超参数组合的过程非常耗时;然而,一旦获取比较好的超参数组合,可以保持一段时间的使用。这是值得推荐并且相对一劳永逸的性能提升方法。由于各个新模型在执行交叉验证的过程中相互独立,可以充分利用多核处理器甚至是分布式的资源来从事并行搜索(Parallel Grid Search),可以成倍的节省运算时间。下面是并行搜索的过程:
Python源码:
#coding=utf-8
from sklearn.datasets import fetch_20newsgroups
import numpy as np
from sklearn.cross_validation import train_test_split
from sklearn.svm import SVC
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.pipeline import Pipeline
from sklearn.grid_search import GridSearchCV
#-------------download data
news=fetch_20newsgroups(subset='all')
#-------------select front 3000 data,split data,25% for test
X_train,X_test,y_train,y_test=train_test_split(news.data[:3000],news.target[:3000],test_size=0.25,random_state=33)
#-------------use Pipeline to simplify processing flow,contact wordsVectorizer with classifier model
clf=Pipeline([('vect',TfidfVectorizer(stop_words='english',analyzer='word')),('svc',SVC())])
#-------------create geometric progression (等比数列),total 4*3 =12 parameters combination
parameters={'svc__gamma':np.logspace(-2,1,4),'svc__C':np.logspace(-1,1,3)}
#-------------n_jobs=-1 means use all available CPU
gs=GridSearchCV(clf,parameters,verbose=2,refit=True,cv=3,n_jobs=-1)
time_=gs.fit(X_train,y_train)
gs.best_params_,gs.best_score_
print 'Best accuracy is:',gs.score(X_test,y_test)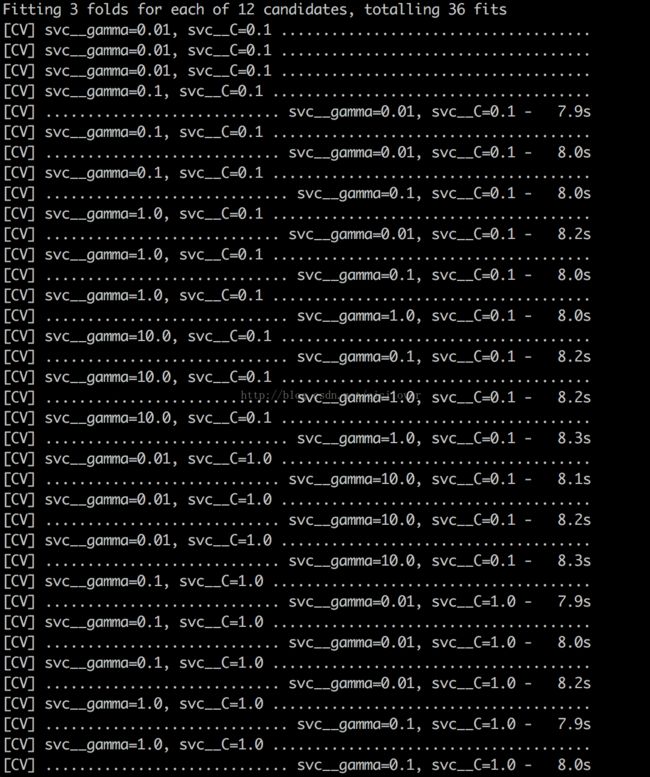
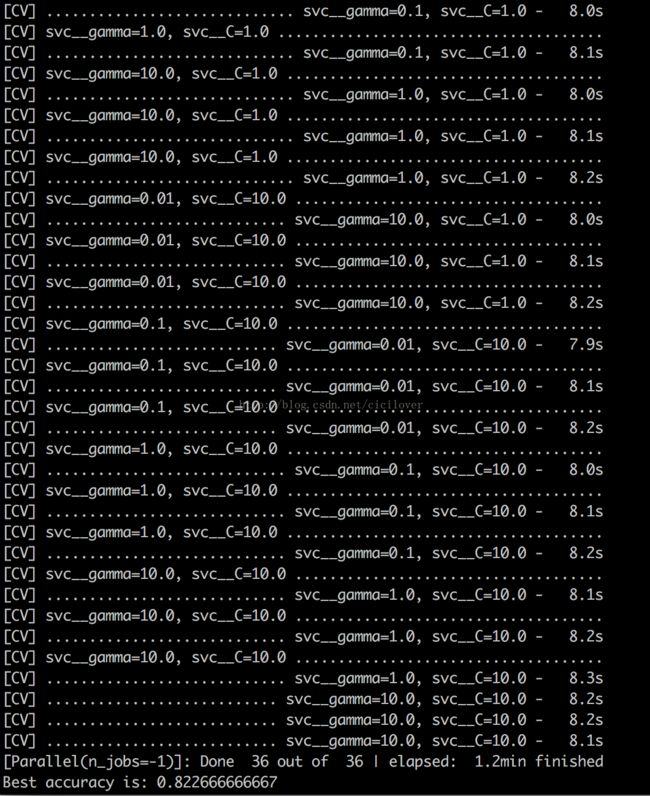
同样是网格搜索,使用多线程并行搜索技术,执行同样的36项任务一共只花费了1.2min,寻找到的最佳的超参数组合在测试ji上的最高分类准确性依然为82.27%。在没有影响准确性的情况下,几乎3倍的提升了运算速度!
P.S:关于Pipeline,后面会单独介绍
可以参考:http://scikit-learn.org/stable/modules/pipeline.html#pipeline-chaining-estimators