Kmeans聚类②——Sklearn数据生成器(make_blobs,make_classification,make_circles,make_moons)
Kmeans系列目录:
Kmeans聚类②——Sklearn数据生成器(make_blob/classification/circles/make_moons)
Kmeans聚类③——Kmeans聚类原理&轮廓系数&Sklearn实现
Kmeans聚类实例④——电商RFM模型聚类
Kmeans聚类实例⑤——直播行业用户质量分析
在学习机器学习中,经常会遇到找不到合适的数据集的情况,后来才发现我们可以自己批量生成各种各样的数据,简直不要太惊喜!这里整理了一些常用的生成数据的方法
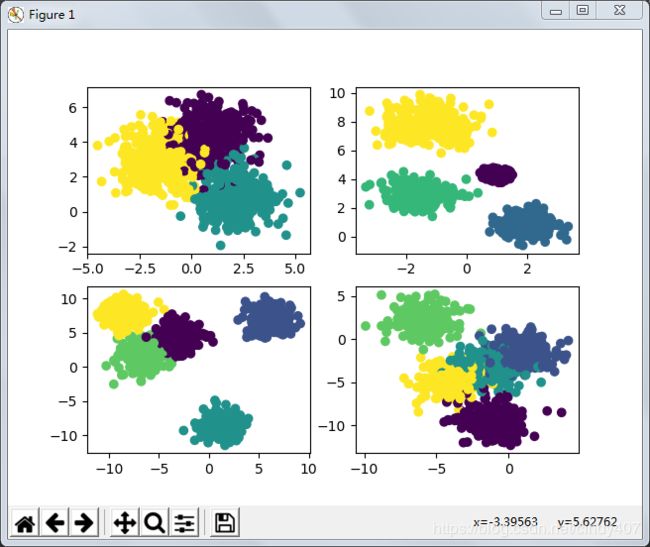
一、Make_blobs(聚类生成器)
n_samples:待生成的样本的总数
n_features:每个样本的特征数,默认为2
centers: 要生成的样本中心(类别)数,默认为3
cluster_std: 每个类别的方差,默认为1
shuffle: 打乱 (default=True)
import matplotlib.pyplot as plt
data1,target1= make_blobs(n_samples=1000,n_features=2,random_state=0) # random_state是随机数种子,便于复现
data2,target2= make_blobs(n_samples=1000,n_features=2,random_state=0,centers=4,cluster_std=[0.2,0.5,0.6,0.8]) # centers是类数量,默认为3
data3,target3 = make_blobs(n_samples=1000,n_features=2,shuffle=True,centers=5,cluster_std=1.2) # cluster_std是标准差,可以设置一样,或每个类设置一个
data4,target4 = make_blobs(n_samples=1000,n_features=2,shuffle=True,random_state=2,centers=5,cluster_std=1.2) # shuffle是可以打乱
fig,axes = plt.subplots(2,2)
axes[0,0].scatter(data1[:,0],data1[:,1],c=target1)
axes[0,1].scatter(data2[:,0],data2[:,1],c=target2)
axes[1,0].scatter(data3[:,0],data3[:,1],c=target3)
axes[1,1].scatter(data4[:,0],data4[:,1],c=target4)
plt.show()
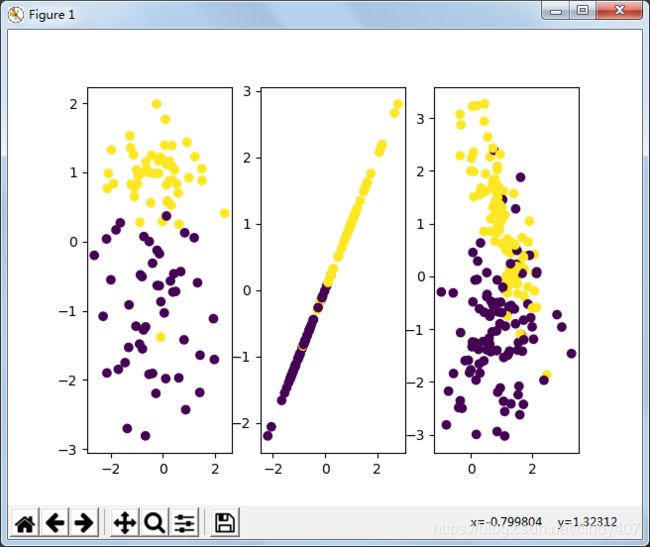
二、Make_classification(分类生成器)
n_features :特征个数= n_informative() + n_redundant + n_repeated
n_informative:多信息特征的个数
n_redundant:冗余信息,informative特征的随机线性组合
n_repeated :重复信息,随机提取n_informative和n_redundant 特征
n_classes:分类类别
n_clusters_per_class :某一个类别是由几个cluster构成的
data1,target1 = make_classification(n_samples=100,n_features=2,n_informative=1,n_redundant=0,n_repeated=0,n_clusters_per_class=1)
data2,target2= make_classification(n_samples=100,n_features=2,n_informative=1,n_redundant=0,n_repeated=1,n_clusters_per_class=1)
data3,target3= make_classification(n_samples=200,n_features=2,n_informative=2,n_redundant=0,n_repeated=0,n_clusters_per_class=1)
fig,axes = plt.subplots(1,3)
axes[0].scatter(data1[:,0],data1[:,1],c=target1)
axes[1].scatter(data2[:,0],data2[:,1],c=target2)
axes[2].scatter(data3[:,0],data3[:,1],c=target3)
plt.show()
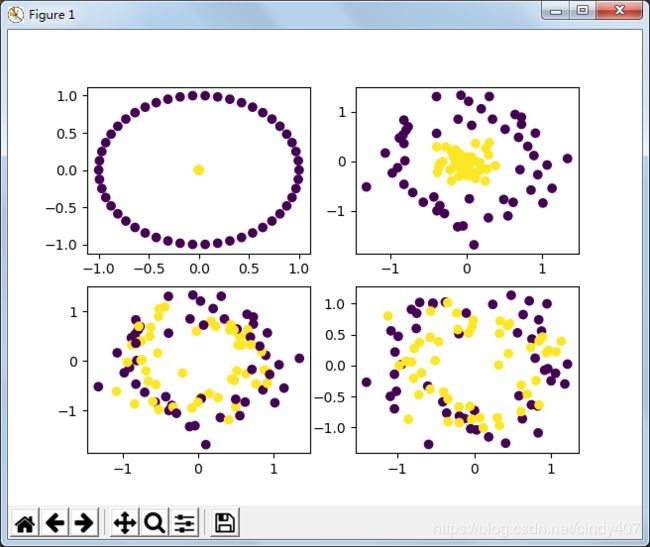
三、Make_circles(圆环图)
前3个没啥可说的,noise是指添加高斯噪音,factor是指内环与外环的接近成都,值越接近1,两环距离越近
data1,target1=make_circles(n_samples=100,shuffle=True,noise=0,random_state=0,factor=0)
data2,target2= make_circles(n_samples=100,shuffle=True,noise=0.2,random_state=0,factor=0)
data3,target3= make_circles(n_samples=100,shuffle=True,noise=0.2,random_state=0,factor=0.8)
data4,target4= make_circles(n_samples=100,shuffle=False,noise=0.2,random_state=56,factor=0.8)
fig,axes = plt.subplots(2,2)
axes[0,0].scatter(data1[:,0],data1[:,1],c=target1)
axes[0,1].scatter(data2[:,0],data2[:,1],c=target2)
axes[1,0].scatter(data3[:,0],data3[:,1],c=target3)
axes[1,1].scatter(data4[:,0],data4[:,1],c=target4)
plt.show()
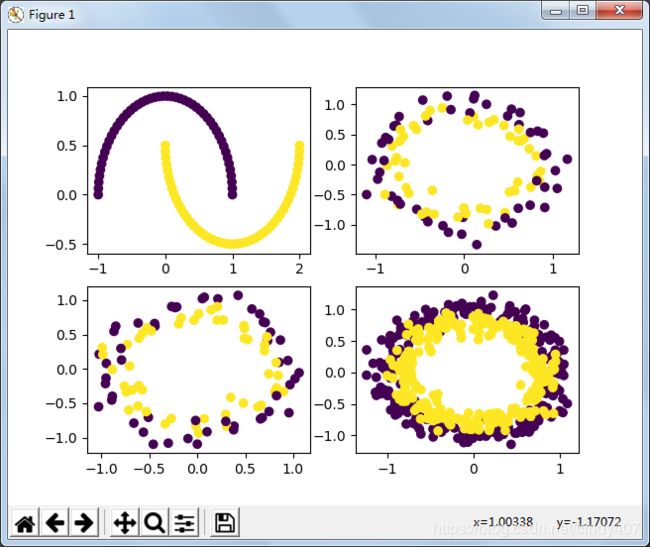
四、Make_Moons(月亮图)
与Make_circles相比,就少了一个factor
data1,target1=make_moons(n_samples=100,shuffle=True,noise=0,random_state=0)
data2,target2= make_circles(n_samples=100,shuffle=True,noise=0.1,random_state=0)
data3,target3= make_circles(n_samples=100,shuffle=True,noise=0.1,random_state=2)
data4,target4= make_circles(n_samples=500,shuffle=False,noise=0.1,random_state=2)
fig,axes = plt.subplots(2,2)
axes[0,0].scatter(data1[:,0],data1[:,1],c=target1)
axes[0,1].scatter(data2[:,0],data2[:,1],c=target2)
axes[1,0].scatter(data3[:,0],data3[:,1],c=target3)
axes[1,1].scatter(data4[:,0],data4[:,1],c=target4)
plt.show()