决策树(ID3、C4.5、CART)
一、基本流程
一棵决策树包含一个根节点、若干个内部节点和若干个叶节点,叶节点对应于决策结果,其他每个结点对应于一个属性测试。
决策树的生成是一个递归过程,伪代码如下所示:
输入:训练集D={{x1,y1},{x2,y2}...,{xm,ym}}
属性集A={a1,a2,...ad}
过程:函数TreeGenerate(D,A)
生成节点node;
if D中样本全属于同一类别C then
将node标记为C类叶节点;return
end if
if A为空 then
将node 标记为叶节点,其类别标记为D中样本数最多的类;return
end if
从A中选择最优划分属性a*;
for a*中的每一个值a** do
为node生成一个分支;令Dv表示D中在a*上取值为a**的样本子集;
以TreeGenerate(Dv,A\{a*})为分支结点
end for
输出:以node为根结点的一棵决策树
由此可以看出,决策树学习的关键是从A中选择最优划分属性,因此就存在不同的算法。其实说白了不同的算法只是在“从A中选择最优属性划分属性a*”这儿有所不同,算法的其他部分都不变,即决策树的生成都是一样的,区别只是怎么选a*。
二、ID3
ID3是以信息增益为准则来选择划分属性。
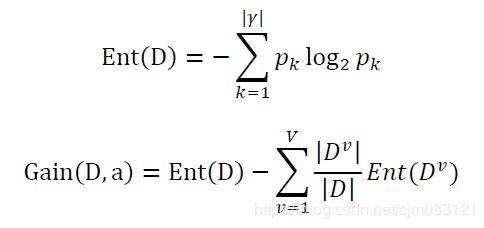
说明:
1、Ent(D)为信息熵,当前样本集合D中第k类样本所占的比例为pk。
2、假设离散属性a有V个可能的取值,若使用a来对样本集D进行划分,则会产生V个分支结点,其中第v个分支结点包含了D中所有在属性a上取值为av的样本,记为Dv。
3、选择信息增益Gain(D,a)最大的属性作为最优划分属性。
三、C4.5
C4.5是以增益率为准则来选择划分属性。
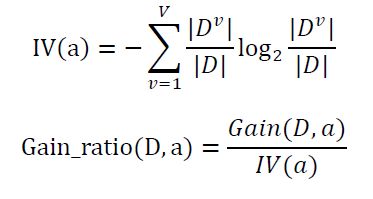
说明:
选择增益率Gain_ratio(D,a)最大的属性作为最优划分属性。
四、CART
CART是以基尼指数为准则来选择划分属性,CART分类和回归都可用,本文是分类树。

说明:
选择基尼指数Gini_index(D,a)最小的属性作为最优划分属性。
五、使用决策树进行分类
对于建立好的决策树,可以将它用于分类。在执行数据分类时,需要使用决策树以及用于构造决策树的标签向量。然后比较测试数据与决策树上的数值,递归执行该过程直到进入叶子节点。代码如下:

说明:
1、使用index方法查找当前列表中第一个匹配fisrtStr变量的元素,并记录它的下标featIndex,递归遍历整棵树,比较testVec[featIndex]与树节点的值,如果达到叶子节点,则返回当前节点的分类标签。
2、这段代码摘自《机器学习实战》,里面的决策树是以字典的形式存储的。
六、决策树可视化
决策树可视化可以使用Python+Graphviz完成。下面的说明来自Graphviz官方文档。
安装Graphviz:
https://blog.csdn.net/cjm083121/article/details/88893580
引入相关模块:
from graphviz import Digraph
Create a graph by instantiating a new Graph or Digraph object:
dot = Digraph(comment='The Round Table')
Add nodes and edges to the graph object using its node() and edge() or edges() methods.The node()-method takes a name identifier as first argument and an optional label:
dot.node('A', 'King Arthur')
dot.node('B', 'Sir Bedevere the Wise')
dot.node('L', 'Sir Lancelot the Brave')
dot.edges(['AB', 'AL'])
dot.edge('B', 'L', constraint='false')
Use the render()-method to save the source code:
dot.render('test-output/round-table.gv', view=True)
Passing view=True will automatically open the resulting (PDF, PNG, SVG, etc.) file with your system’s default viewer application for the file type.
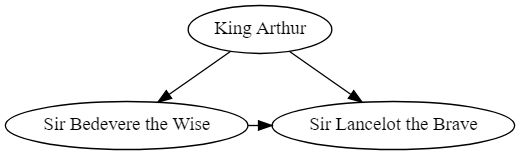
使用Graphviz画出的决策树(使用递归):
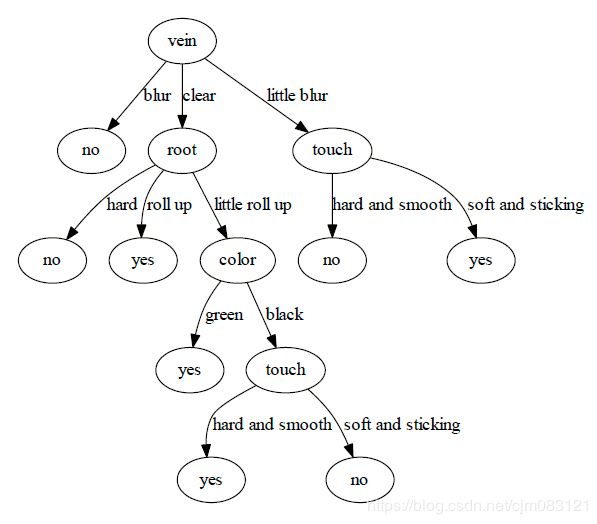
注:要想在边上加一些文字说明,可以在edge()函数的参数里加一个label参数指定你要添加的内容,比如:
dot.node('A','vein')
dot.node('B','no')
dot.edge('A', 'B', label='blur')
七、利用sklearn进行决策树分类
使用sklearn里的决策树进行分类,初始化对象时,默认是使用基尼指数作为准则来划分属性的。以下内容来自sklearn官方文档。
from sklearn.datasets import load_iris
from sklearn import tree
iris = load_iris()
clf = tree.DecisionTreeClassifier()
clf = clf.fit(iris.data, iris.target)
结合Graphviz进行可视化:
import graphviz
dot_data = tree.export_graphviz(clf, out_file=None)
graph = graphviz.Source(dot_data)
graph.render("iris")
或者更加精细一些:
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
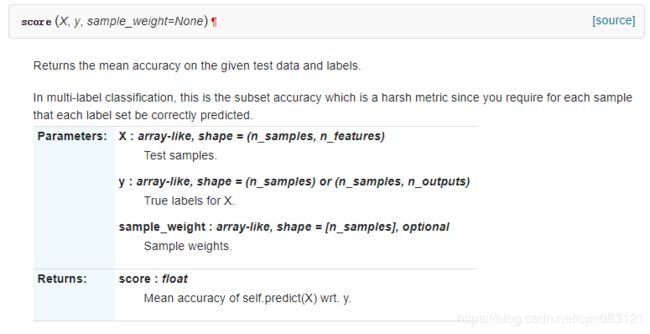
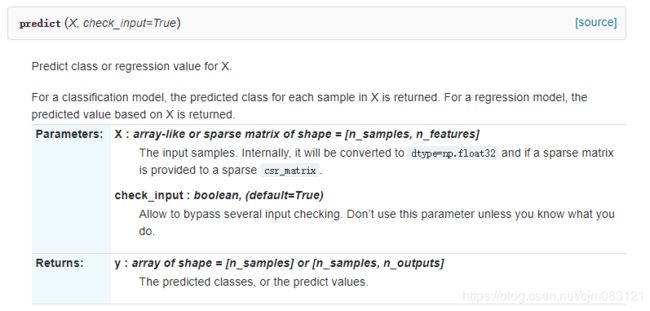
对于训练好的分类器,可以进行预测,使用predict(X),X是要预测的样本:
也可以计算分类准确率score(X,y),X是要计算的样本,y是这个样本的正确类标签: