R语言实现RMF模型
RMF模型说明
RMF模型是客户管理中,常被用来衡量客户价值和客户创利能力的重要方法。它主要考量三个指标:
最近一次消费-Recency:近期购买的客户倾向于再度购买
消费频率-Frequency:经常购买的客户再次购买概率高
消费金额-Monetary:消费金额较多的客户再次消费可能性更大
根据上述三个维度,对客户做细分,假定每个维度划分成五个等级,得到客户的R值(1-5),F值(1-5),M值(1-5)。那么客户就被分作5*5*5 <- 125个细分群,我们可以根据客户交易行为的差异针对不同群体做不同的推荐。
或者进一步针对不同的业务场景,对R、F、M赋予不同权重Wr、Wf、Wm,得到每个用户的得分:W=Wr*R+Wf*F+Wm*M。根据最终得分W排序,再划分等级,采用不用的营销策略。
RFM模型其实很简单,其重点应该是在:一,如何做划分,不管是针对三个维度的划分还是三个维度取不同权重的和W的划分,都要依据实际业务场景情况确定。二,针对不同的客户群如何选定合适的营销手段,这个则需要对每个客户群体有正确的解读,并且对实际业务场景理解比较深入。
参考:http://shenhaolaoshi.blog.sohu.com/143275752.html
http://shenhaolaoshi.blog.sohu.com/201923838.html
R语言实现RMF
用来做分析的数据应该是一段时间里累计的客户的消费记录,每笔记录至少需要客户名称、消费时间、消费金额三个要素。
用R生成模拟随机消费记录数据。客户编号为1000-1999共100人,消费记录10000条,消费记录产生时间在2014-01-01到2015-12-29之间。
sales <-data.frame(sample(1000:1999,replace=T,size=10000),abs(round(rnorm(10000,178,55)))+1)#随机第一列产生用户ID,第二列产生用户消费数据
sales.dates<- as.Date("2014/1/1") + 728*sort(stats::runif(10000)) # runif(n,min = 0, max = 1)产生随机数
sales<- cbind(sales,sales.dates)
names(sales)<- c("用户ID","消费金额","消费时间")
str(sales)#查看data.frame的格式
根据上述消费记录,得到Recency、Frequency、Monetary的值。
sales$距离时间 <- round(as.numeric(difftime(Sys.Date(),sales[,3],units="days")))
salesM<- aggregate(sales[,2],list(sales$用户ID),sum) #总消费金额
names(salesM)<- c("用户ID","Monetization")
salesF<- aggregate(sales[,2],list(sales$用户ID),length) #消费次数
names(salesF)<- c("用户ID","Frequency")
salesR<- aggregate(sales[,4],list(sales$用户ID),min) #最近一次消费时间
names(salesR)<- c("用户ID","Recency")
test1<- merge(salesF,salesR,"用户ID")
salesRFM<- merge(salesM,test1,"用户ID")
#均值划分
salesRFM0<- salesRFM
salesRFM0$rankR<- cut(salesRFM0$Recency, 5,labels=F)
salesRFM0$rankR<- 6-salesRFM0$rankR #rankR,5是最近,1是最远
salesRFM0$rankF<- cut(salesRFM0$Frequency, 5,labels=F) #rankF,1是最少,5是最频繁
salesRFM0$rankM<- cut(salesRFM0$Monetization, 5,labels=F) #rankM,1是最少,5是最多
salesRFM0$rankRMF<- 0.5*rankR + 0.3*rankF + 0.2*rankM
对Receny、Frequency、Monetary标准化后,以权重权重0.5,0.3,0.2来求客户最终得分,客户最终得分在0-1之间。
#标准化后划分
salesRFM1<- salesRFM
salesRFM1$rankR<-(salesRFM1$Recency-min(salesRFM1$Recency))/(max(salesRFM1$Recency)-min(salesRFM1$Recency))
salesRFM1$rankR<- 1-salesRFM1$rankR #rankR,1是最近,0是最远
salesRFM1$rankF<-(salesRFM1$Frequency-min(salesRFM1$Frequency))/(max(salesRFM1$Frequency)-min(salesRFM1$Frequency))#rankF,0是最少,1是最频繁
salesRFM1$rankM<- (salesRFM1$Monetization-min(salesRFM1$Monetization))/(max(salesRFM1$Monetization)-min(salesRFM1$Monetization))#rankM,0是最少,1是最多
salesRFM1$rankRMF<- 0.5*salesRFM1$rankR + 0.3*salesRFM1$rankF + 0.2*salesRFM1$rankM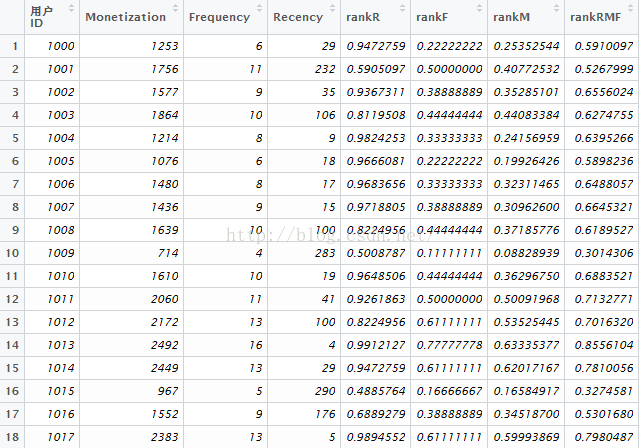
以上用到的权重需要根据实际情况考量选定。得到的客户评分rankRMF,是客户细分的一个参考依据,实际场景中,我们可能还有客户的其他数据,可以综合来看。
参考:
http://www.idatacamp.com/2015/10/09/r%E8%AF%AD%E8%A8%80%E5%AE%9E%E7%8E%B0rfm%E6%A8%A1%E5%9E%8B/
有任何问题或建议欢迎提出,转载请注明来源!