WGAN代码解读及实验总结
GAN作为图像的另一个新领域,本成为21世纪最好的idea。嘿嘿,最近小试牛刀,下载了个WGAN的代码,这里简单分析下,给大家一个参考。
【提示】
本文预计阅读时间5分钟,带灰色底纹的和加粗的为重要部分哦!
(一)WGAN初识
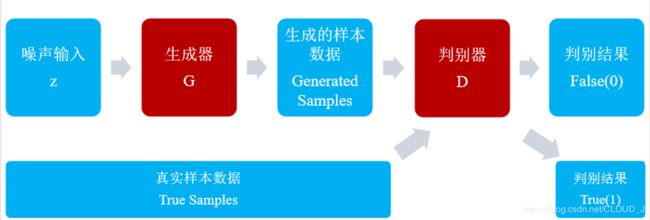


(二)代码分析
2.1 main struct
打开代码后,它的主要结构如下图所示。

我们先看一下wgan_conv主函数,打开之后首先直接到最底main的位置,如下
if __name__ == '__main__':
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
# the dir of pic generated
sample_folder = 'Samples/mnist_wgan_conv'
if not os.path.exists(sample_folder):
os.makedirs(sample_folder)
# net param
generator = G_conv_mnist()
discriminator = D_conv_mnist()
# data param
data = mnist()
# run
wgan = WGAN(generator, discriminator, data)
wgan.train(sample_folder)
这里做几点阐述
1、首先创建了一个目录用来存储你的生成图像,程序会每隔一段时间输出一个图像。
2、搞了三个类,一个generater生成器网络,一个是discriminator判别器类,然后是数据类。
3、又声明一个对象WGAN网络,然后调用它的train函数
OK至此,主函数结构阐述清楚。那此时你会想generater咋定义?discriminator咋定义?
好一个一个看。
2.2 generator
generator是生成器网络,其实就是搭了一个上采样的网络,先将噪声输入一维向量,通过全连接到更多的数据,然后把它展开成二维的图像,这里我们先用的灰度,你也可以改成彩色。然后再上采样,随意搞得,反正最后你要上采样到和你的正样本图像维度一致。如下所示:
class G_conv_mnist(object):
def __init__(self):
self.name = 'G_conv_mnist'
def __call__(self, z):
with tf.variable_scope(self.name) as scope:
#step 1 全连接层,把z白噪声变为8*15*128图
g = tcl.fully_connected(z, 8*15*128, activation_fn = tf.nn.relu, normalizer_fn=tcl.batch_norm,
weights_initializer=tf.random_normal_initializer(0, 0.02))
g = tf.reshape(g, (-1, 8, 15, 128))
#step 2 反卷积/上采样 到16*30*64图 4代表卷积核大小
g = tcl.conv2d_transpose(g, 64, 4,stride=2,
activation_fn=tf.nn.relu, normalizer_fn=tcl.batch_norm, padding='SAME', weights_initializer=tf.random_normal_initializer(0, 0.02))
#step 3 反卷积/上采样 到32*60*1的图,此时和真实手写体的数据是一样的图
g = tcl.conv2d_transpose(g, 1, 4, stride=2,
activation_fn=tf.nn.sigmoid, padding='SAME', weights_initializer=tf.random_normal_initializer(0, 0.02))
print(g.shape)
return g
@property
def vars(self):
return tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.name)
注意:
这里你会看到一个call函数,它是咋用呢?
一个类下面有个call函数,你就可以生成一个对象后,直接把它当成方法用。例如
class G():
call(x):
print(x)
这样的话你就A = G(),然后再A(1)就打印了1。
其实就是说这个类弄好了,之后可以直接当函数用。
好,然后我们看一下discriminator
2.3 discriminator
和generator干了差不多的事情,他要把X和GX输进去,然后搭建一个卷积网络判别真假。
class D_conv_mnist(object):
def __init__(self):
self.name = 'D_conv_mnist'
def __call__(self, x, reuse=False):
with tf.variable_scope(self.name) as scope:
if reuse:
scope.reuse_variables()
size = 64
#step 1 卷积4*4卷积核 bzx30x60x1 -> bzx15x30x64
shared = tcl.conv2d(x, num_outputs=size, kernel_size=4,
stride=2, activation_fn=lrelu)
#step 2 卷积4*4卷积核 bzx15x30x64 -> bzx7x15x128
shared = tcl.conv2d(shared, num_outputs=size * 2, kernel_size=4,
stride=2, activation_fn=lrelu, normalizer_fn=tcl.batch_norm)
#step 3 展开向量 bzx7x15x128 -> bzx6372
shared = tcl.flatten(shared)
#step 4 全连接层
d = tcl.fully_connected(shared, 1, activation_fn=None, weights_initializer=tf.random_normal_initializer(0, 0.02))
q = tcl.fully_connected(shared, 128, activation_fn=lrelu, normalizer_fn=tcl.batch_norm)
q = tcl.fully_connected(q, 10, activation_fn=None) # 10 classes
return d, q
@property
def vars(self):
return tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=self.name)
2.4 数据的导入改写
我下载的代码是直接导入的minist数据集,我们可能要导入图片数据集哈,这里我做了一些改变。
这里加了个next_batch函数,先生成随机序列,然后读取batch图像,存到数据集中。
class mnist():
def __init__(self, flag='conv', is_tanh = False):
self.datapath = prefix + 'bus_data/'
self.X_dim = 784 # for mlp
self.z_dim = 100
self.y_dim = 10
self.sizex = 32 # for conv
self.sizey = 60 # for conv
self.channel = 1 # for conv
#self.data = input_data.read_data_sets(datapath, one_hot=True)
self.flag = flag
self.is_tanh = is_tanh
self.Train_nums = 17
def __call__(self,batch_size):
batch_imgs = self.next_batch(self.datapath,batch_size)
#batch_imgs,y = self.next_batch(prefix,batch_size)
if self.flag == 'conv':
batch_imgs = np.reshape(batch_imgs, (batch_size, self.sizex, self.sizey, self.channel))
if self.is_tanh:
batch_imgs = batch_imgs*2 - 1
#return batch_imgs, y
return batch_imgs
def next_batch(self,data_path, batch_size):
#def next_batch(self,data_path, lable_path, batch_size):
train_temp = np.random.randint(low=0, high=self.Train_nums, size=batch_size) # 生成元素的值在[low,high)区间,随机选取
train_data_batch = np.zeros([batch_size,self.sizex, self.sizey]) # 其中[img_row, img_col, 3]是原数据的shape,相应变化
#train_label_batch = np.zeros([batch_size, self.size, self.size]) #
count = 0 # 后面就是读入图像,并打包成四维的batch
#print(data_path)
img_list = os.listdir(data_path)
#print(img_list)
for i in train_temp:
img_path = os.path.join(data_path, img_list[i]) # 图片文件
img = cv.imread(img_path)
gray = cv.cvtColor(img,cv.COLOR_RGB2GRAY)
train_data_batch[count, :, :] = cv.resize(gray,(self.sizey, self.sizex))
count+=1
return train_data_batch#, train_label_batch
def data2fig(self, samples):
if self.is_tanh:
samples = (samples + 1)/2
fig = plt.figure(figsize=(4, 4))
gs = gridspec.GridSpec(4, 4)
gs.update(wspace=0.05, hspace=0.05)
for i, sample in enumerate(samples):
ax = plt.subplot(gs[i])
plt.axis('off')
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.set_aspect('equal')
plt.imshow(sample.reshape(self.sizex,self.sizey), cmap='Greys_r')
return fig
2.5 WGAN网络
首先是搭网络NET,discriminator分别把真实的正样本X投进去,把噪声产生的G_sample投进去,得到正负结果。
# nets
self.G_sample = self.generator(self.z)
self.D_real, _ = self.discriminator(self.X)
self.D_fake, _ = self.discriminator(self.G_sample, reuse = True)
然后就是计算损失。我们利用上面结果分别计算D和G的损失,然后有两个优化器,分别对于D和G
# loss
self.D_loss = - tf.reduce_mean(self.D_real) + tf.reduce_mean(self.D_fake)
self.G_loss = - tf.reduce_mean(self.D_fake)
self.D_solver = tf.train.RMSPropOptimizer(learning_rate=1e-4).minimize(self.D_loss, var_list=self.discriminator.vars)
self.G_solver = tf.train.RMSPropOptimizer(learning_rate=1e-4).minimize(self.G_loss, var_list=self.generator.vars)
这里网络就搭建好了,我们要看一下train函数。其主要是先优化D再优化G这个步骤,这里我么此优化G和D的次数相同,你也可以去调整这个n_d。
for epoch in range(training_epoches):
# update D
n_d = 20 if epoch < 250 or (epoch+1) % 500 == 0 else 10
for _ in range(n_d):
#X_b, _ = self.data(batch_size)
X_b= self.data(batch_size)
self.sess.run(self.clip_D)
self.sess.run(
self.D_solver,
feed_dict={self.X: X_b, self.z: sample_z(batch_size, self.z_dim)}
)
# update G
for _ in range(n_d):
#X_b, _ = self.data(batch_size)
X_b= self.data(batch_size)
self.sess.run(self.clip_D)
self.sess.run(
self.G_solver,
feed_dict={self.z: sample_z(batch_size, self.z_dim)}
)
对于WGAN的全部代码如下
class WGAN():
def __init__(self, generator, discriminator, data):
self.generator = generator
self.discriminator = discriminator
self.data = data
self.z_dim = self.data.z_dim
self.sizex = self.data.sizex
self.sizey = self.data.sizey
self.channel = self.data.channel
self.X = tf.placeholder(tf.float32, shape=[None, self.sizex, self.sizey, self.channel])
self.z = tf.placeholder(tf.float32, shape=[None, self.z_dim])
# nets
self.G_sample = self.generator(self.z)
self.D_real, _ = self.discriminator(self.X)
self.D_fake, _ = self.discriminator(self.G_sample, reuse = True)
# loss
self.D_loss = - tf.reduce_mean(self.D_real) + tf.reduce_mean(self.D_fake)
self.G_loss = - tf.reduce_mean(self.D_fake)
self.D_solver = tf.train.RMSPropOptimizer(learning_rate=1e-4).minimize(self.D_loss, var_list=self.discriminator.vars)
self.G_solver = tf.train.RMSPropOptimizer(learning_rate=1e-4).minimize(self.G_loss, var_list=self.generator.vars)
# clip
self.clip_D = [var.assign(tf.clip_by_value(var, -0.01, 0.01)) for var in self.discriminator.vars]
gpu_options = tf.GPUOptions(allow_growth=True)
self.sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
def train(self, sample_folder, training_epoches = 100000, batch_size = 5):
i = 0
self.sess.run(tf.global_variables_initializer())
for epoch in range(training_epoches):
# update D
n_d = 20 if epoch < 250 or (epoch+1) % 500 == 0 else 10
for _ in range(n_d):
#X_b, _ = self.data(batch_size)
X_b= self.data(batch_size)
self.sess.run(self.clip_D)
self.sess.run(
self.D_solver,
feed_dict={self.X: X_b, self.z: sample_z(batch_size, self.z_dim)}
)
# update G
for _ in range(n_d):
#X_b, _ = self.data(batch_size)
X_b= self.data(batch_size)
self.sess.run(self.clip_D)
self.sess.run(
self.G_solver,
feed_dict={self.z: sample_z(batch_size, self.z_dim)}
)
# print loss. save images.
if epoch % 100 == 0 or epoch < 100:
D_loss_curr = self.sess.run(
self.D_loss,
feed_dict={self.X: X_b, self.z: sample_z(batch_size, self.z_dim)})
G_loss_curr = self.sess.run(
self.G_loss,
feed_dict={self.z: sample_z(batch_size, self.z_dim)})
print('Iter: {}; D loss: {:.4}; G_loss: {:.4}'.format(epoch, D_loss_curr, G_loss_curr))
if epoch % 1000 == 0:
samples = self.sess.run(self.G_sample, feed_dict={self.z: sample_z(16, self.z_dim)})
print(samples.shape)
fig = self.data.data2fig(samples)
plt.savefig('{}/{}.png'.format(sample_folder, str(i).zfill(3)), bbox_inches='tight')
i += 1
plt.close(fig)
(三)实验结果
我找了17张车的图片~~原谅我比较懒,如下图所示。基本都是差不多样子的。

然后代码跑起来~我们把它resize到(30,60),主要是为了让我的机器跑快些,本来就怂。
一开始是一堆噪声图如下图所示。
其实在训练一段时间后如下所示,可以看出具有一定车的样子,中间黑车身,貌似也能看到个车轱辘。哈哈。初见效果~

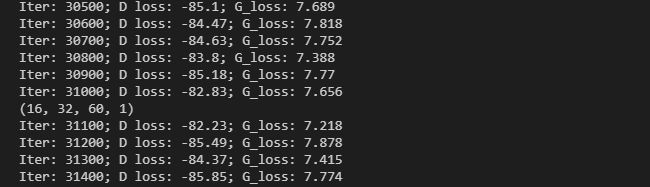
损失的结果如下所示:
(四)总结
通过这个实验对于GAN有了初步的了解,如果有什么写的不对的地方,还请指出。这里附上代码:
https://github.com/Harryjun/wgan_demo