人工智能资料库:第54辑(20170515)
作者:chen_h
微信号 & QQ:862251340
微信公众号:coderpai
1.【博客】Handling imbalanced dataset in supervised learning using family of SMOTE algorithm
简介:
Consider a problem where you are working on a machine learning classification problem. You get an accuracy of 98% and you are very happy. But that happiness doesn’t last long when you look at the confusion matrix and realize that majority class is 98% of the total data and all examples are classified as majority class. Welcome to the real world of imbalanced data sets!!
Some of the well-known examples of imbalanced data sets are
1 - Fraud detection: where number of fraud cases could be much smaller than non-fraudulent transactions.
2- Prediction of disputed / delayed invoices: where the problem is to predict default / disputed invoices.
3- Predictive maintenance data sets, etc
原文链接:http://www.datasciencecentral.com/profiles/blogs/handling-imbalanced-data-sets-in-supervised-learning-using-family
2.【资料】Top 15 Python Libraries for Data Science in 2017
简介:

Core Libraries.
- NumPy
- SciPy
- Pandas
Visualization.
- Matplotlib
- Seaborn
- Bokeh
- Plotly
Machine Learning.
- SciKit-Learn
Deep Learning - Keras / TensorFlow / Theano
- Theano
- TensorFlow
原文链接:https://activewizards.com/blog/top-15-libraries-for-data-science-in-python/
3.【论文】Accurate and reproducible invasive breast cancer detection in whole-slide images: A Deep Learning approach for quantifying tumor extent
简介:
With the increasing ability to routinely and rapidly digitize whole slide images with slide scanners, there has been interest in developing computerized image analysis algorithms for automated detection of disease extent from digital pathology images. The manual identification of presence and extent of breast cancer by a pathologist is critical for patient management for tumor staging and assessing treatment response. However, this process is tedious and subject to inter- and intra-reader variability. For computerized methods to be useful as decision support tools, they need to be resilient to data acquired from different sources, different staining and cutting protocols and different scanners. The objective of this study was to evaluate the accuracy and robustness of a deep learning-based method to automatically identify the extent of invasive tumor on digitized images. Here, we present a new method that employs a convolutional neural network for detecting presence of invasive tumor on whole slide images. Our approach involves training the classifier on nearly 400 exemplars from multiple different sites, and scanners, and then independently validating on almost 200 cases from The Cancer Genome Atlas. Our approach yielded a Dice coefficient of 75.86%, a positive predictive value of 71.62% and a negative predictive value of 96.77% in terms of pixel-by-pixel evaluation compared to manually annotated regions of invasive ductal carcinoma.
原文链接:https://www.nature.com/articles/srep46450
4.【博客】Neural networks for algorithmic trading 1.2 — Correct time series forecasting + backtesting
简介:
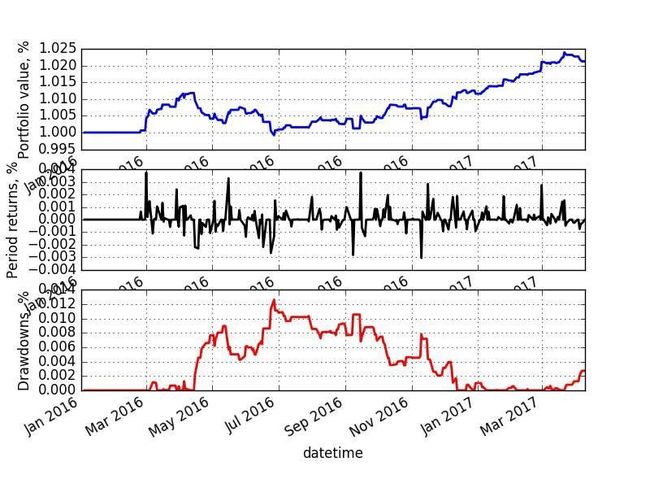
Hi everyone! Some time ago I published a small tutorial on financial time series forecasting which was interesting, but in some moments wrong. I have spent some time working with different time series of different nature (applying NNs mostly) in HPA, that particularly focuses on financial analytics, and in this post I want to describe more correct way of working with financial data. Comparing to previous post, I want to show different way of data normalizing and discuss more issues of overfitting (which definitely appears while working with data that has stochastic nature). We won’t compare different architectures (CNN, LSTM), you can check them in previous post. But even working only with simple feed-forward neural nets we will see important things. If you want to jump directly to the code — check out IPython Notebook. For Russian speaking readers, it’s a translation of my post here and you can check webinar on backtesting here.
原文链接:https://medium.com/@alexrachnog/neural-networks-for-algorithmic-trading-1-2-correct-time-series-forecasting-backtesting-9776bfd9e589
5.【课程】I Dropped Out of School to Create My Own Data Science Master’s — Here’s My Curriculum
简介:
I dropped out of a top computer science program to teach myself data science using online resources like Udacity, edX, and Coursera. The decision was not difficult. I could learn the content I wanted to faster, more efficiently, and for a fraction of the cost. I already had a university degree and, perhaps more importantly, I already had the university experience. Paying $30K+ to go back to school seemed irresponsible.
原文链接:https://medium.com/@davidventuri/i-dropped-out-of-school-to-create-my-own-data-science-master-s-here-s-my-curriculum-1b400dcee412