在 TensorFlow 中实现简单的自动编码器
作者:chen_h
微信号 & QQ:862251340
微信公众号:coderpai
生成对抗网络(GAN)最近已经成为了一个非常受欢迎的网络架构,最初这个网络架构的流行是因为通过模仿著名画家的艺术风格,但最近通过 DeepFake ,它可以无缝的替换视频中的面部表情,同时保持高质量的输出。
GAN 中最重要的一个组成部分是自动编码器。自动编码器是具有两个部分的神经网络架构:输入编码器和输出解码器,并且数据相同。起初,这可能听起来令人困惑和无用,但是通过训练神经网络来复制输入数据。我们真正做的是让网络学习数据的"压缩版本”,就是把数据进行压缩,然后我们再通过解压来还原输入的数据。用行话来说,这种转换是找到我们数据的 “潜在空间“ 表示。
在这篇文章中,我们将解释如何在 Python 中实现自动编码器,以及如何在时间中使用它来编码和解码数据。你可以先安装一下 Python 3 的环境,以及 TensorFlow 的环境,因为后续我们会采用代码的形式来进行学习。
对于一个自动编码器来说,如果是好的编码器,它必须满足以下四个要求:
- 压缩数据,即潜在数据维度 < 输入数据;
- 需要很好的复制输入数据,保留原始大部分数据特征;
- 允许我们很容易的获得编码层数据;
- 允许我们很容易的进行解码操作,还原输入数据;
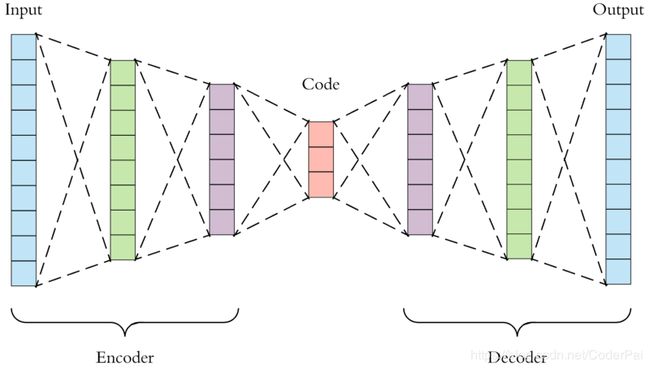
我将向你展示两种表示方法,利用底层接口和高层接口来实现这个功能。底层接口就是直接采用 TensorFlow API 来进行编写,高层接口我们会利用 keras API 来实现我们的功能。如果你想要更多的了解底层模型逻辑,我还是建议你使用 TensorFlow API 来进行实现。
这篇文章中,我们将直接使用 TensorFlow core API 来进行操作,这需要一些必备知识。我们先来简单解释三个基本概念:tf.placeholder,tf.Variable 和 tf.Tensor 。
tf.placeholder 只是一个变量,它将是模型的输入,但不会模型本身的一部分。它基本上允许我们告诉模型它应该预期某个类型和某个维度的变量。这与强类型语言中的变量声明非常类似。
tf.Variable 与其他编程语言中的变量几乎相同,其声明类似于大多数强类型语言的声明。例如,网络的权重是tf.Variables。
tf.Tensor 稍微复杂一点。在我们的例子中,我们可以将它视为包含操作的符号表示的对象。例如,给定占位符 X 和权重变量 W ,矩阵乘法W*X的一般表示是张量,但是给定特定值 X 和 W 的结果不是张量。
既然已经进行了介绍,那么构建网络的过程就会相当简单了,但可能会有点迂回。我们将使用 MNIST数据集,该数据集是存储为 28*28 图片的手写数字的数据集。我们将 D 定义为输入数据,在这种情况下,将图像尺寸拉长为 784 维度,并且把压缩后的编码长度设置为 128 ,用 d 来表示,然后忘了具有以下尺寸的3层网络:D -> d -> D 。
我们现在将实现一个简单的自动编码器类,并且进行逐层解释。
首先,我们需要一个占位符来输入数据:
self.X = tf.placeholder(tf.float32, shape=(None, D))
然后,我们通过定义第一层权重(带有额外偏差)作为变量来开始编码阶段:
self.W1 = tf.Variable(tf.random_normal(shape=(D,d)))
self.b1 = tf.Variable(np.zeros(d).astype(np.float32))
请注意,权重的维度是 D*d,从较高维度到最低维度。接下来,我们为编码层创建张量,作为输入和权重之间的乘法,并且加上偏差,所有这些都由 relu 激活函数激活。
self.Z = tf.nn.relu( tf.matmul(self.X, self.W1) + self.b1 )
然后我们进入解码阶段,这与编码相同,但是从较低维度到较高维度扩展。
self.W2 = tf.Variable(tf.random_normal(shape=(d,D)))
self.b2 = tf.Variable(np.zeros(D).astype(np.float32))
最后,我们定义输出张量,自己预测变量。选择 sigmoid 激活函数是为了简单,因为它总是在区间 [0,1] 中,这与输入的归一化图像素的范围相同。
logits = tf.matmul(self.Z, self.W2) + self.b2
self.X_hat = tf.nn.sigmoid(logits)
这就是一整个网络!我们只需要一个损失函数和一个优化器,我们就可以很开心的开始训练。选择的损失函数是 sigmoid交叉熵,这意味着我们将问题视为像素级的二元分类,这对于黑白图像的数据集是有意义的。
关于优化,这是非常常见的一种方式,也许我们应该创建一个模型,在出现问题时输出哪个优化器是最好的??
self.cost = tf.reduce_sum(
tf.nn.sigmoid_cross_entropy_with_logits(
# Expected result (a.k.a. itself for autoencoder)
labels=self.X,
logits=logits
)
)
self.optimizer = tf.train.RMSPropOptimizer(learning_rate=0.005).minimize(self.cost)
最后一个稍微技术性的术语:session(会话),这是一个作为上下文管理器和后端连接器的对象,需要初始化:
self.init_op = tf.global_variables_initializer()
if(self.sess == None):
self.sess = tf.Session()
self.sess = tf.get_default_session()
self.sess.run(self.init_op)
现在我们需要训练模型,但是不用担心,这在 TensorFlow 中非常简单:
# Prepare the batches
epochs = 10
batch_size = 64
n_batches = len(X) // bs
for i in range(epochs):
# Permute the input data
X_perm = np.random.permutation(X)
for j in range(n_batches):
# Load data for current batch
batch = X_perm[j*batch_size:(j+1)*batch_size]
# Run the batch training!
_, costs = self.sess.run((self.optimizer, self.cost),
feed_dict={self.X: batch})
最后一行真的是唯一有趣的一行。它告诉 TensorFlow 使用批处理作为占位符输入 X 运行训练步骤,并使用给定的优化器和损失函数来执行权重更新。
让我们看看这个网络输出的一些例子:
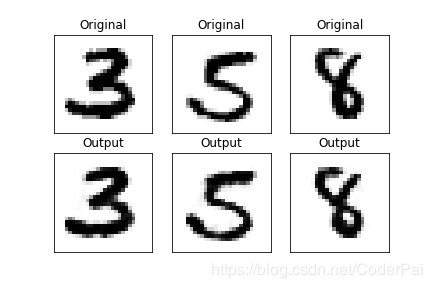
现在这一切看起来都非常完美,但目前我们只编写了一个可以重建自己的网络。那么,我们怎样才能真正使用自动编码器? 我们需要定义另外两个操作,编码和解码。这实际上非常简单:
def encode(self, X):
return self.sess.run(self.Z, feed_dict={self.X: X})
在这里我们告诉 TensorFlow 来计算 Z,如果你回头看,你会发现是代表编码的张量。解码过程也非常简单:
def decode(self, Z):
return self.sess.run(self.X_hat, feed_dict={self.Z: Z})
这一次,我们明确的给出了通过 Z 进行编码的张量流,我们之前使用编码函数计算过,我们告诉它计算预测输出 X_hat 。
现在你可以看到,即使是一个简单的网络,但是代码也非常长。当然我们可以对每个权重进行参数化并使用列表,而不是单个变量。但是当我们需要快速或者自动的测试多个结构时会发生什么?这会变得非常复杂。但是不用担心,我们采用高层 API 可以轻松的完成所有这些工作!这个接口就是 keras。
所有网络定义,损失,优化和训练拟合都可以用几行代码搞定:
t_model = Sequential()
t_model.add(Dense(256, input_shape=(784,)))
t_model.add(Dense(128, name='bottleneck'))
t_model.add(Dense(784, activation=tf.nn.sigmoid))
t_model.compile(optimizer=tf.train.AdamOptimizer(0.001),
loss=tf.losses.sigmoid_cross_entropy)
t_model.fit(x, x, batch_size=32, epochs=10)
就是这样,我们有一个训练好的网络。生活多美好啊
但是整个编码和解码怎么样呢?是的,看起来有点棘手,但是不要担心,人家帮我们解决了。我们需要一些东西:
- 一个会话变量;
- 输入张量,用于制定 feed_dict 参数中的输入;
- 编码的张量,用于检索编码,并用作解码 feed_dict 参数的输入;
- 解码的张量,用来检索解码值;
胡言乱语一下
我们通过从感兴趣的层获得所需的张量来实现这一目标!请注意,通过命名编码层,我们可以很容易的进行检索。
session = tf.get_default_session()
if(self.sess == None):
self.sess = tf.Session()
# Get input tensor
def get_input_tensor(model):
return model.layers[0].input
# get bottleneck tensor
def get_encode_tensor(model):
return model.get_layer(name='encode').output
# Get output tensor
def get_output_tensor(model):
return model.layers[-1].output
现在给出一个训练好的模型,你可以通过以下获取所需的所有变量:
t_input = get_input_tensor(t_model)
t_enc = get_bottleneck_tensor(t_model)
t_dec = get_output_tensor(t_model)
session = tf.get_default_session()
# enc will store the actual encoded values of x
enc = session.run(t_enc, feed_dict={t_input:x})
# dec will store the actual decoded values of enc
dec = session.run(t_dec, feed_dict={t_enc:enc})
完整版代码,请点击这里
原文链接,请点击这里