Task not serializable是Spark开发过程最令人头疼的问题之一,这里记录下出现这个问题的两个实例,一个是自己遇到的,另一个是stackoverflow上看到。等有时间了再仔细探究出现Task not serialiazable的各种原因以及出现问题后如何快速定位问题的所在,至少目前阶段碰到此类问题,没有什么章法
1.
package spark.exampl
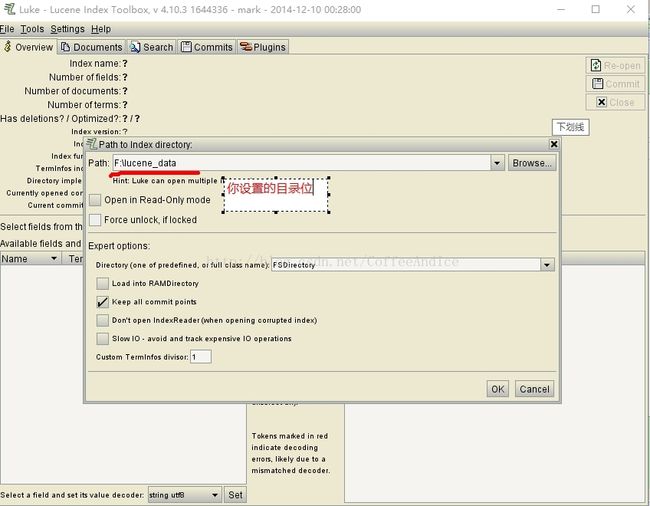
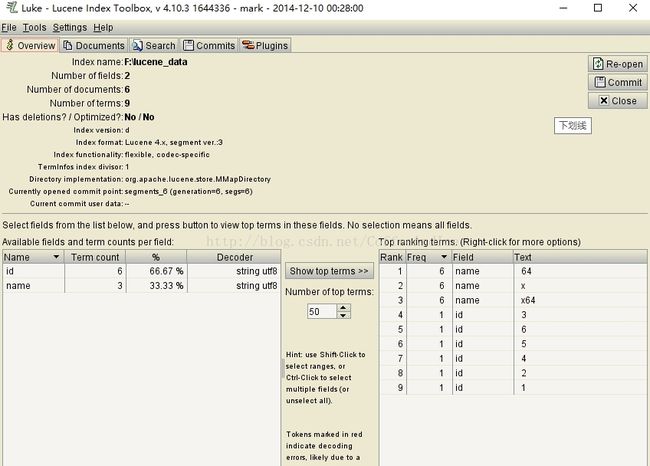
mysql 查看当前正在执行的操作,即正在执行的sql语句的方法为:
show processlist 命令
mysql> show global status;可以列出MySQL服务器运行各种状态值,我个人较喜欢的用法是show status like '查询值%';一、慢查询mysql> show variab
1. 只有Map任务的Map Reduce Job
File System Counters
FILE: Number of bytes read=3629530
FILE: Number of bytes written=98312
FILE: Number of read operations=0
FILE: Number of lar
import java.util.LinkedList;
import java.util.List;
import ljn.help.*;
public class BTreeLowestParentOfTwoNodes {
public static void main(String[] args) {
/*
* node data is stored in
本文介绍Java API 中 Date, Calendar, TimeZone和DateFormat的使用,以及不同时区时间相互转化的方法和原理。
问题描述:
向处于不同时区的服务器发请求时需要考虑时区转换的问题。譬如,服务器位于东八区(北京时间,GMT+8:00),而身处东四区的用户想要查询当天的销售记录。则需把东四区的“今天”这个时间范围转换为服务器所在时区的时间范围。
入口脚本
入口脚本是应用启动流程中的第一环,一个应用(不管是网页应用还是控制台应用)只有一个入口脚本。终端用户的请求通过入口脚本实例化应用并将将请求转发到应用。
Web 应用的入口脚本必须放在终端用户能够访问的目录下,通常命名为 index.php,也可以使用 Web 服务器能定位到的其他名称。
控制台应用的入口脚本一般在应用根目录下命名为 yii(后缀为.php),该文