LVQ 学习向量量化 聚类 python 实现 以及 一些 思考
思路就不多说了。。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def LVQ(X,y,n_clusters,learning_rate=0.1):
#随机选择n_clusters个样本作为p向量
idx=np.random.choice(X.shape[0],n_clusters)
p=X[idx,:]
#获取p的标签
py=y[idx]
#画图用
fig,ax=plt.subplots(3,3,figsize=(12,12),sharex=True,sharey=True)
j=-1
for i in range(4501):
#随机选择一个样本xi
idx=np.random.choice(X.shape[0],1)
xi=X[idx,:]
#计算xi到各个p向量的距离
dist=np.sqrt(np.sum(np.square(xi-p),axis=1))
#找到最小距离p向量的索引
minIdx=np.argmin(dist)
#如果xi的标签与该向量的标签相等,则靠近,不然就原理
if y[idx]==py[minIdx]:
p[minIdx]=p[minIdx]+learning_rate*(xi-p[minIdx])
else:
p[minIdx]=p[minIdx]-learning_rate*(xi-p[minIdx])
#每循环500次画图
if (i>0) & (i%500==0):
j+=1
clusters=[]
#对于样本里的每一个x,找到它属于哪个类
for x in X:
dist=np.sqrt(np.sum(np.square(x-p),axis=1))
label=np.argmin(dist)
clusters.append(label)
if j<3 :
k=0
elif j<6 :
k=1
else:
k=2
ax[k,j%3].scatter(X[:,0],X[:,1],c=clusters)
ax[k,j%3].scatter(p[:,0],p[:,1],marker='x',color='red',s=100)
ax[k,j%3].set_title("Iteration: %d" % i)
ax[k,j%3].set_xlim(xlim)
ax[k,j % 3].set_ylim(ylim)先用西瓜书的西瓜4.0跑一下看看
###TEST with watermelon datasets###
data=pd.read_csv('data/watermelon.csv',header=None)
data['y']=np.zeros((data.shape[0],1),dtype=int)
data.iloc[9:22,2]=1
X=data.iloc[:,:2].values
y=data.iloc[:,2].values
plt.scatter(X[:,0],X[:,1],c=y)
xlim=(plt.axis()[0],plt.axis()[1])
ylim=(plt.axis()[2],plt.axis()[3])
LVQ(X,y,5)
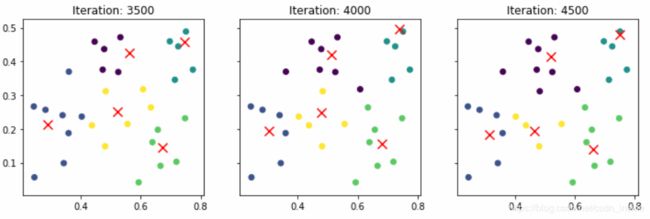
似乎还是有点效果,循环到后面基本也收敛了。
再看看两个类,嗯,效果也比较理想。

再用sklearn随机生成一组数据看看
###TEST WITH RANDOM DATASETS###
from sklearn.datasets import make_blobs
X, Y = make_blobs(n_samples=200, n_features=2,centers=5, cluster_std=1.0,random_state=1)
C=np.ones(200)
C[35:145]=0
plt.scatter(X[:,0],X[:,1],c=Y)
xlim=(plt.axis()[0],plt.axis()[1])
ylim=(plt.axis()[2],plt.axis()[3])
### USing C ###
LVQ(X,C,n_clusters=5)
### USing Y ###
LVQ(X,Y,n_clusters=5)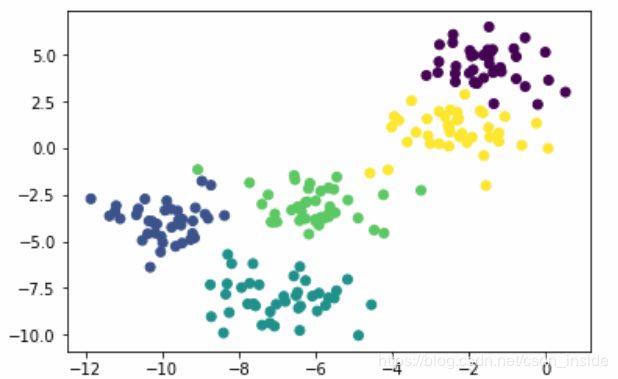
这里有个问题,西瓜书的例子是假设数据集有两类,一类C1,一类C2。但如果是这个数据集,它有5个类。
如果只用两个类,也就是让X的标签,变成非0即1,那么聚类的效果,要比直接用Y(5个类)效果好。
效果见下:
![]()
用两个假设类来聚类:

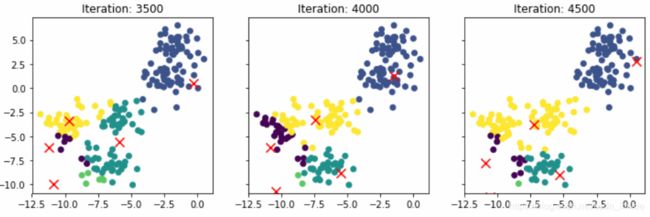
用五个假设来聚类:明显失败了。。。但是换个初始值,有时候又会成功,不像用C,基本每次都能成功聚类。

思考了一下,觉得问题的蹊跷在:如果用五个分类,随机选择的5个P向量标签比较分散,极端的情况就是[1,2,3,4,5],每个P都属于不同的类,每个样本进来之后,只有1/5的概率与标签的相等,那么大多数情况下,都在远离,越跑越远,所以聚类失败。如果只有2个类,P的取值不是0就是1,那么相等的概率就会提高很多,聚类的成功率也会提高。