GloVe :Global Vectors 全局向量 模型详解 公式推导
在cs224n Lecture 3: GloVe skipgram cbow lsa 等方法对比 / 词向量评估 /超参数调节 总结 中,
我们知道,以往生成词向量有两种算法,一种是基于矩阵分解(Matrix Factorization)的,代表有LSA,改进的HAL算法等;一种是基于滑窗概率(Shallow Window)的,代表有Skip-Gram和CBOW。这两种算法,或多或少都存在一些问题,比如,对于矩阵分解的算法而言,其共现矩阵(Co-occurence)是十分庞大的,而对其进行SVD分解,计算更是复杂,得到的词向量无法处理类比(man is to woman as king is to queen)问题;对于滑窗概率算法而言,虽然解决了计算量上的问题,效果不错,但是没有充分利用到语料的全局统计特性。GloVe算法,就是旨在克服上述两种算法的缺点,对优点“结合”了一下。
GloVe算法的如何诞生的?作者是如何想出这个idea的?大致是这样:
既然要用到语料的全局统计特性,那共现矩阵,自然是不能少的了,所以保留了矩阵分解算法的共现矩阵,就像这样:

我们知道滑窗概率模型是根据概率建模的,如何把共现矩阵跟概率结合起来呢?算一下每个语境词出现在某个中心词的次数不就行了。比如这里的第一行,就是I作为中心词,其它各个词作为语境词的概率,像Like就是2/3,enjoy就是1/3。
作者做了大量实验,发现虽然和“概率”结合了起来,但是这些概率并没有什么卵用:

k是语境词,ice和steam分别是两个中心词,这些概率,很难看出有什么规律。但是,有趣的地方来了!
把这几个概率按列除一下!作者通过大量试验,规律就出来了!

中心词i=ice,中心词j=steam,语境词k分别=solid、gas、water、fashion。
第一列:solid ice,固态冰,虽然别扭,但显然是个合理的词对(两者都有固体之意);solid steam,固态蒸汽,???。在背景词solid下,ice与solid的关系比steam要紧密,P(solid|ice)/P(solid|steam)这个比率很大。
第二列:ice gas,冰气?不合理;gas steam,都是气体,合理。在背景词gas下,steam与gas的关系比ice要紧密,P(gas|ice)/P(gas|steam)这个比率很小。
第三列:ice water,冰水,没问题;water steam,水蒸气,也没问题;ice和steam都与water相关,P(water|ice)/P(water|steam)趋近于1。
第四列:fashion ice,时尚冰?fashion steam,流行蒸汽?wtf?显然八竿子打不着,P(fashion|ice)/P(fashion|steam)也趋近于1。
总结一下,规律就是:
| 比率P(k|i)/P(k|j) | j,k相关 | j,k无关 |
| i,k相关 | 趋近1 | 很大 |
| i,k无关 | 很小 | 趋近1 |
所以,作者发现比率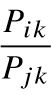 确实能够反映内在的规律。作者现在就想,假设这个比率,可以由词向量通过函数F作用得到:
确实能够反映内在的规律。作者现在就想,假设这个比率,可以由词向量通过函数F作用得到:
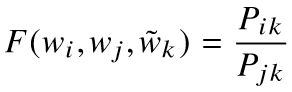
相似相似,如何刻画相似?在词向量空间,对两个向量相减不就行了,所以:

等式的左边是个向量,右边是个标量,如何相等?内积啊!所以:
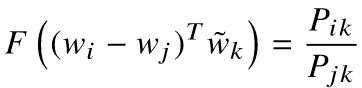
在共现矩阵里面,语境词跟中心词是相对的(角对称阵),那么![]() 、
、![]() 后,应该满足:
后,应该满足:
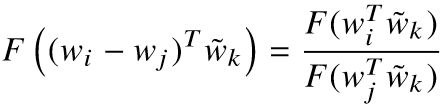 ······①
······①
其中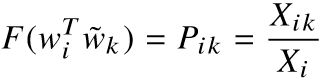 ·······②
·······②
解①,发现F=exp()。
把F=exp,带入②,得到:
![]()
对于j和k,得到的形式是一致的:

既然语境词跟中心词是相对的,把k换成i或者j:


现在,两个等式的左边是相等的(都是内积相乘),右边不等。回到上面的那个共现矩阵,假设i=I,j=like,Xij=Xji=2,但是Xi=3,Xj=4,不等。问题就出在log(Xi)或者log(Xj)项,那么添加偏置bi,bj,用来抵消log(Xi)和log(Xj),两者不就一样了。所以就得到最终的结果:
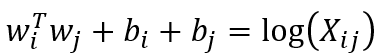
原来我们的目标,是找到一个词向量的函数F,来逼近比率Pik/Pjk:
现在我们已经找到这个函数了,如何来刻画逼近的效果呢?用类似线性回归的MSE(均方误差)不就行了:
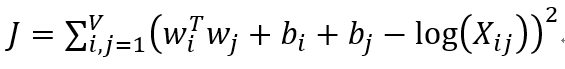
还没有结束!!!
矩阵分解方法,有个缺点,就是各个词的权重是一样的,处理这个问题,就是添加一个根据词频决定的权重项:
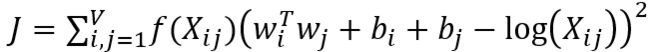
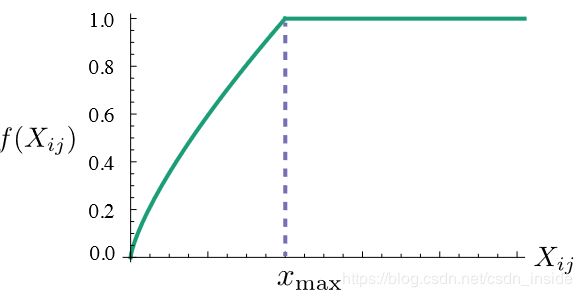
这个权重项f(Xij)应该满足:
①f(0)=0,没出现过的词直接忽略
②f(x)应该是非减函数,比如常出现的词,其权重应该不小,不常见的词,其权重应该不会过大。权重多少跟出现的频次正相关。
③对于大的输入,f(x)应该不至于太大,不然像the、he这类词,权重就会过大。
显然,满足这些条件的函数有很多个,但是作者经过试验,发现下面这个函数,在α=3/4时,效果最好。
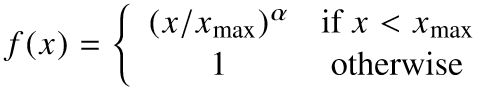
这也是GloVe模型的原理和推导过程了。
至于与其它的模型的效果对比、如何调参可以参考我的:
cs224n Lecture 3: GloVe skipgram cbow lsa 等方法对比 / 词向量评估 /超参数调节 总结
参考资料:
GloVe原论文
理解GloVe模型(+总结)