爬取去哪儿网 6000 多个景点数据告诉你,国庆哪里不是人山人海!

国庆长假已经过去一半啦,朋友们有多少是堵在了景区和路上?
为了方便大家的出游选择,笔者爬取了去哪儿网上面的 6000 多个景点数据,包含景点评级、热度、销量等等数据,汇总成这篇出游参考指南。
![]()
爬虫
爬虫继续用的是最近的心头爱 Selenium,打开去哪儿网站,右键,分析网页。
我们需要的数据非常地清晰:
话不多说,只要定位到自己想要的信息,那么代码非常简单。
from tqdm import tqdm
import time
from selenium import webdriver
from selenium.common.exceptions import TimeoutException, WebDriverException
import pandas as pd
import numpy as np
position = ["北京","天津","上海","重庆","河北","山西","辽宁","吉林","黑龙江","江苏","浙江","安徽","福建","江西","山东","河南","湖北","湖南","广东","海南","四川","贵州","云南","陕西","甘肃","青海","台湾","内蒙古","广西","西藏","宁夏","新疆","香港","澳门"]
name,level,hot,address,num=[],[],[],[],[]
def get_one_page(key,page):
try:
#打开浏览器窗口
option_chrome = webdriver.ChromeOptions()
option_chrome.add_argument('--headless')
driver = webdriver.Chrome(chrome_options=option_chrome)
time.sleep(1)
url = "http://piao.qunar.com/ticket/list.htm?keyword="+str(key)+"®ion=&from=mpl_search_suggest&page="+str(page)
driver.get(url)
infor = driver.find_elements_by_class_name("sight_item")
for i in range(len(infor)):
#获取景点名字
name.append(infor[i].find_element_by_class_name("name").text)
#获取景点评级
try:
level.append(infor[i].find_element_by_class_name("level").text)
except:
level.append("")
#获取景点热度
hot.append(infor[i].find_element_by_class_name("product_star_level").text[3:])
#获取景点地址
address.append(infor[i].find_element_by_class_name("area").text)
#获取景点销量
try:
num.append(infor[i].find_element_by_class_name("hot_num").text)
except:
num.append(0)
driver.quit()
return
except TimeoutException or WebDriverException:
return get_one_page()
for key in tqdm(position):
print ("正在爬取{}".format(key))
#取前10页
for page in range(1,14):
print ("正在爬取第{}页".format(page))
get_one_page(key,page)
sight = {'name': name, 'level': level, 'hot': hot, 'address': address, 'num':num}
sight = pd.DataFrame(sight, columns=['name', 'level', 'hot', 'address', 'num'])
sight.to_csv("sight.csv",encoding="utf_8_sig")
本文仅爬取国内的数据,由于景点数据众多,每个省份仅取了前 13 页。获得景点个数 6630 个。
![]()
数据可视化
热门景区 TOP30:
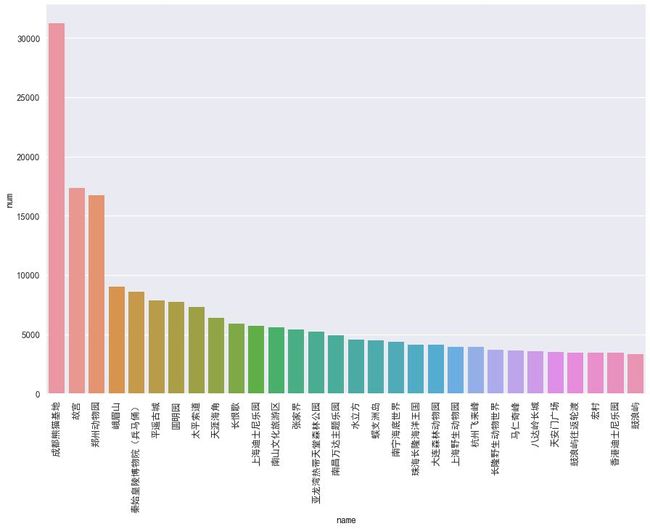
大熊猫不愧为国宝,最热门就是它。其次是故宫、郑州动物园、峨眉山、秦始皇兵马俑等等。因为笔者没有去过多少地方玩,也不知道为什么郑州动物园能排到第三,大家知道的可以分享一下它的特色吗?
省份与评级:

说实话,这个图的配色真的是太丑了,主要是笔者过于懒惰,不想好好配色了。
热力图:
热力图根据省份和城市分别作图,其次在根据销量和热度两类图,这里采用的是 Python 调用高德地图 API 实现经纬度换算、地图可视化一文的方式,调用高德地图 API 完成。
首先是省份和景区热度:
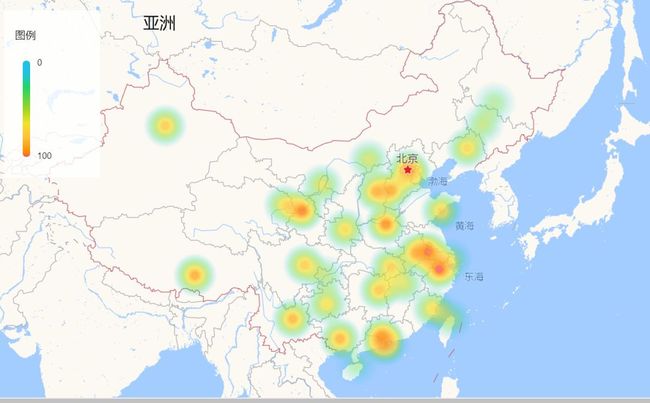
然后是省份和销量:
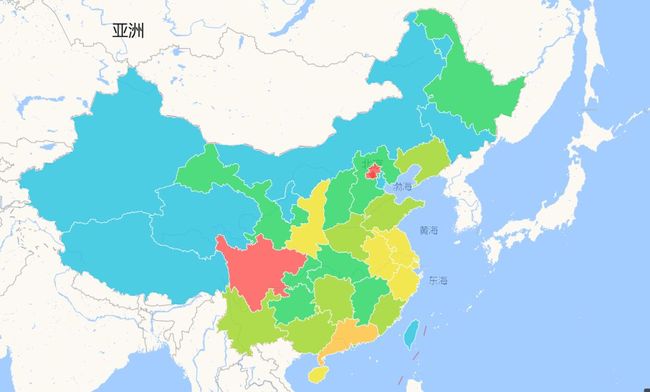
接下来是城市和景区热度:

最后是城市和景区销量:

值得注意的是,城市和销量一图热力范围不明显,原因为景区之间销量天差地别,一些太少的统计下来,作图非常的不明显了。若大家不喜欢用高德地图 API 作图,那么人生苦短,我要用 pyecharts 画图的方法也非常适合做热力图,比如这里笔者做了一张省份和销量的图:

综合来看,北京、四川及沿海地区都是旅游的热门省份。建议大家尽量避免去这些省份游玩。
推荐景区:
知道了需要避免的景区和省份城市,那么可以去哪些人少的地方呢?这里笔者根据景区分级,分别推荐 15 个人少的景区:
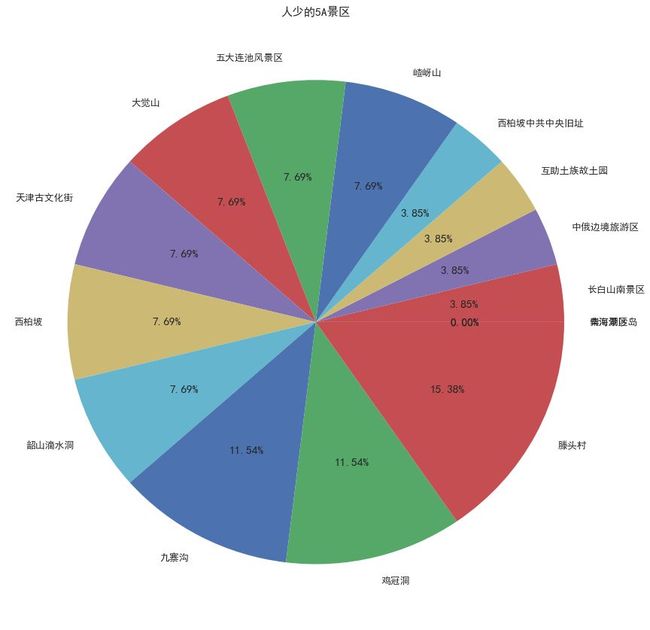
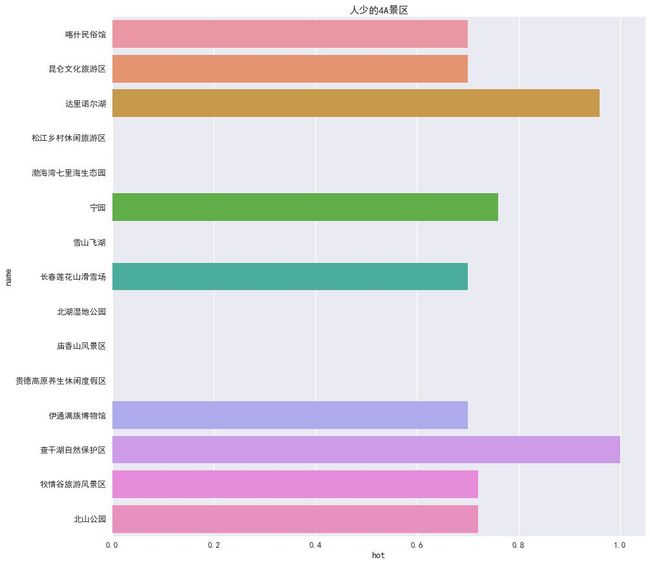
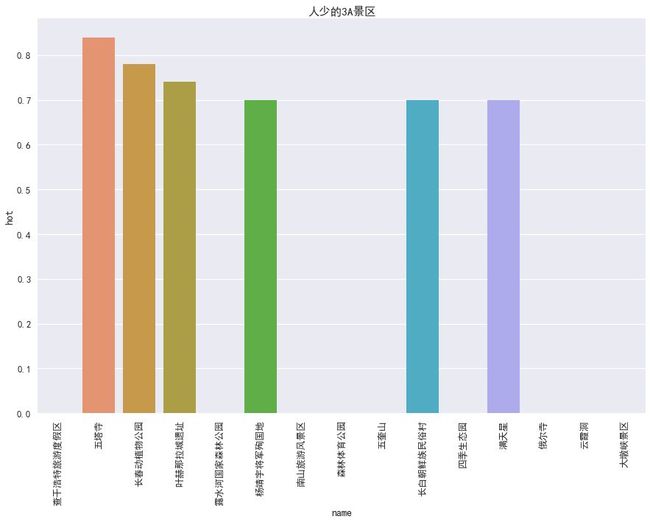
最后两张图是根据热度做的图,没有条形的则是热度为 0,那么大家可以选择上述景点中热度较高的进行游玩。
可视化代码:
data = pd.read_csv("sight.csv")
data = data.fillna(0)
data = data.drop(columns=['Unnamed: 0'])
#将地址分为省,市,区
data["address"] = data["address"].apply(lambda x: x.replace("[","").replace("]",""))
data["province"] = data["address"].apply(lambda x: x.split("·")[0])
data["city"] = data["address"].apply(lambda x: x.split("·")[1])
data["area"] = data["address"].apply(lambda x: x.split("·")[-1])
#销量最多的前30景点
num_top = data.sort_values(by = 'num',axis = 0,ascending = False).reset_index(drop=True)
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']#指定默认字体
plt.rcParams['axes.unicode_minus'] =False # 解决保存图像是负号'-'显示为方块的问题
sns.set(font='SimHei') # 解决Seaborn中文显示问题
sns.set_context("talk")
fig = plt.figure(figsize=(15,10))
sns.barplot(num_top["name"][:30],num_top["num"][:30])
plt.xticks(rotation=90)
fig.show()
#省份与景区评级
data["level_sum"] =1
var = data.groupby(['province', 'level']).level_sum.sum()
var.unstack().plot(kind='bar',figsize=(35,10), stacked=False, color=['red', 'blue','green','yellow'])
#根据省、市统计销量和
pro_num = data.groupby(['province']).agg('sum').reset_index()
city_num = data.groupby(['city']).agg('sum').reset_index()
#基于数据做热力图
import requests
def transform(geo):
key = 'bb9a4fae3390081abfcb10bc7ed307a6'
url="http://restapi.amap.com/v3/geocode/geo?key=" +str(key) +"&address=" + str(geo)
response = requests.get(url)
if response.status_code == 200:
answer = response.json()
try:
loc = answer['geocodes'][0]['location']
except:
loc = 0
return loc
pro_num["lati"] = pro_num["province"].apply(lambda x: transform(x))
city_num["lati"] = city_num["city"].apply(lambda x: transform(x))
pro_num.to_csv("pro_num.csv",encoding="utf_8_sig")
city_num.to_csv("city_num.csv",encoding="utf_8_sig")
from pyecharts import Map
map=Map("省份景点销量热力图", title_color="#fff", title_pos="center", width=1200, height=600, background_color='#404a59')
map.add("",pro_num["province"], pro_num["num"], maptype="china", visual_range=[5000, 80000], is_visualmap=True, visual_text_color='#000', is_label_show=True)
map.render(path="pro_num.html")
map=Map("省份景点热度热力图", title_color="#fff", title_pos="center", width=1200, height=600, background_color='#404a59')
map.add("",pro_num["province"], pro_num["hot"], maptype="china", visual_range=[25,80], is_visualmap=True, visual_text_color='#000', is_label_show=True)
map.render(path="pro_hot.html")
#人少的5A景点,4A景点,3A景点
top_5A = data[data["level"] == "5A景区"].sort_values(by = 'num',axis = 0,ascending = True).reset_index(drop=True)
top_4A = data[data["level"] == "4A景区"].sort_values(by = 'num',axis = 0,ascending = True).reset_index(drop=True)
top_3A = data[data["level"] == "3A景区"].sort_values(by = 'num',axis = 0,ascending = True).reset_index(drop=True)
fig = plt.figure(figsize=(15,15))
plt.pie(top_5A["num"][:15],labels=top_5A["name"][:15],autopct='%1.2f%%')
plt.title("人少的5A景区")
plt.show()
fig = plt.figure(figsize=(15,15))
ax = sns.barplot(top_4A["hot"][:15],top_4A["name"][:15])
ax.set_title("人少的4A景区")
fig.show()
fig = plt.figure(figsize=(15,10))
ax = sns.barplot(top_3A["name"][:15],top_3A["hot"][:15])
ax.set_title("人少的3A景区")
plt.xticks(rotation=90)
fig.show()
![]()
结语
爬虫采集于 2018.9.27,可能因为采集时间不同,结果会有偏差。需要注意的是,若采用 pyecharts 做城市和景区热度、销量的图时,需要考虑 pyecharts 无法获得一些景区位置,解决办法可以参考《狄仁杰之四大天王》影评分析(爬虫+词云+热力图)一文。
分析完了之后,笔者反正决定国庆节都呆在家里了,不想出门,只想当快乐的肥宅。最后,祝大家国庆快乐,珍惜剩下不多的假期!!!
本文为经管人学数据分析(ID:DAT-2017)投稿,作者:胡萝卜酱。

![]()