Java 11 中 11 个不为人知的瑰宝


作者 | Nicolai Parlog
译者 | 罗昭成
出品 | CSDN(ID:CSDNnews)
我们已经迎来了 Java 11,尽管它的升级介绍里没有什么跨时代的特性,但却有一些不为人知的瑰宝,像沙砾中的钻石一般。当然,你肯定了解到了一些特性,比如说响应式的 HTTP/2 的 API ,不需要编译就可以直接运行源代码等。但是,你是否有去尝试过 String 、Optional、Collection 等常用类的扩展,如果还没有,那么恭喜你,你将从本文中了解到 Java 11 不为人知的 11 个像钻石般宝贵的知识点。
![]()
Lambda 表达式的参数类型推断
当我们在写 Lambda 表达式时,你可以指定具体类型,或者直接省略它:
ction append = string -> string + " ";
Function append = (String s) -> s + " ";
在 Java 10 中添加了一个 var 关键字,但是你并不能在 Lambda 表达示中使用:
// compile error in Java 10
Function append = (var string) -> string + " ";
然而,我们在 Java 11 中却可以。来思考一下,为什么可以如此使用?它不仅仅是在省略类型的变量前面加一个 var ,在这种写法中,有以下两个新的特性:
-
通过去除特殊情况,使 var 变得更加统一;
-
允许在 Lambda 的参数上添加注解,而不需要写上完整的变量类型名称。
举个例子,来看一下这两点:
List> types = /*...*/;
types.stream()
// this is fine, but we need @Nonnull on the type
.filter(type -> check(type))
// in Java 10, we need to do this ~> ugh!
.filter((@Nonnull EnterpriseGradeType type) -> check(type))
// in Java 11, we can do this ~> better
.filter((@Nonnull var type) -> check(type))
我们可以在 Lambda 表达式中同时使用清晰的、不明确的 、var 声明的变量,像如下代码:
(var type, String option, index) -> ...
虽然也可以这样实现,但是它会让代码看起来很复杂。因此,笔者建议选取其中一种方式并坚持使用下去。只是为了其中一个参数可添加注解,让所有的参数都加上 var ,这样做的确有点烦人,但笔者认为这是可以忍受的。
![]()
"String::lines" 获取数据行数
你有一个多行的字符串,想要对每一行进行单独操作,你可以使用 String::lines 来实现:
var multiline = "This\r\nis a\r\nmultiline\r\nstring";
multiline.lines()
// we now have a `Stream`
.map(line -> "// " + line)
.forEach(System.out::println);
// OUTPUT:
// This
// is a
// multiline
// string
上面例子中的字符串中的换行使用的是 Windows 中的 \r\n 。尽管我是在 Linux 中使用, lines() 依然可以拆分他们。在不同的操作系统中,lines() 这个方法都会把 \r ,\n , \r\n 作为终止符。即使我们在 string 中混合使用他们。
数据行里面不包含终止符自己,但是可以为空("like\n\nin this\n\ncase" ,它有五行),如果终止符在字符串末尾,lines() 方法会忽略掉它(like\nhere\n ; 只有两行)
与 split("\R") 不同, lines() 是惰性的。
使用更快的搜索方式来搜索新的终止符以提高性能。
如果有人使用 JMH 来验证这一点,请告诉我结果。
不仅如此,它可以更好的传达意思并返回更方便的数据结构(不是数组,而是流)。
![]()
使用"String::strip"来移除空格
一直以来,String 使用 trim 来移除空白字符,此方法认为所有的内容都是使用了大于 U+0020 的 Unicode 值。BACKSPACE (U+0008) 是空白,BELL (U+0007) 也是,但是换行符(U+2028) 不是空白字符。
Java 11 引入了 strip ,它与 trim 有一些细微的差别,它使用 Java 5 中的 "Character::isWhitespace" 来识别要移除的内容。它的文档如下:
SPACESEPARATOR, LINESEPARATOR, PARAGRAPH_SEPARATOR, but not non-breaking space
HORIZONTAL TABULATION (U+0009), LINE FEED (U+000A), VERTICAL TABULATION (U+000B), FORM FEED (U+000C), CARRIAGE RETURN (U+000D)
FILE SEPARATOR (U+001C), GROUP SEPARATOR (U+001D), RECORD SEPARATOR(U+001E), UNIT SEPARATOR (U+001F)
基于此逻辑,这儿还有两个移除方法: stripLeading 、stripTailing ,你按照你自己想要的结果来选择对应的方法。
最后,如果你需要知到去掉空白字符后,是否为空,你不需要执行 strip 操作,只需要使用 isBlank 来判断:
" ".isBlank()); // space ~> true
" abc ".isBlank()); // non-breaking space ~> false
![]()
使用“String::repeat” 来复制字符串
生活大妙招:
-
第一步:深入了解 JDK 的发展与变更

JDK 文档
-
第二步:在 StackOverflow 搜索相关问题的答案
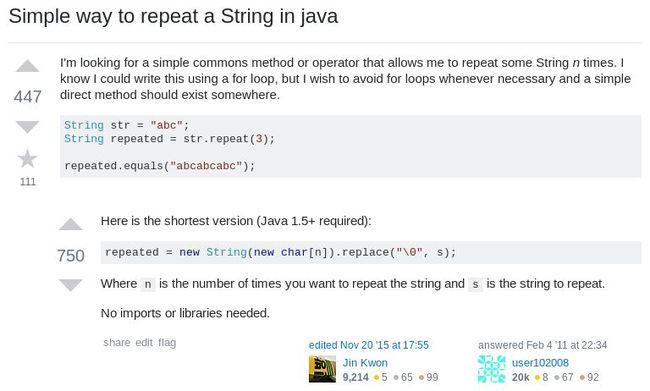
StackOverflow 结果
-
第三步:根据即将到来的变更去回复对应的答案
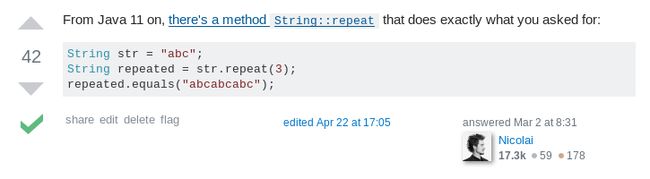
回答答案
-
第四步:
¯\_(ツ)_/¯
-
第五步:

如你所见, String 现在有一个 repeat(int) 的方法。毋庸置疑,它的行为和我们理解的一模一样,完全没有可以争议的地方。
![]()
使用"Path::of"来创建路径
我非常喜欢 Path 这个 API,它解决了我们在路径 、URI 、URL 、FILE 来回切换的麻烦问题。在 Java 11 中,我们可以使用 Paths::get 和 Path::of 来让它们变得很统一:
Path tmp = Path.of("/home/nipa", "tmp");
Path codefx = Path.of(URI.create("http://codefx.org"));
这两个方法,被作为标准方法来使用。
![]()
使用‘Files::readString’和‘Files::writeString’来进行文件读写
如果你需要从一个非常大的文件里面读取内容,我一般使用 Files::lines ,他返回一个惰性数据流。同样,如果要将不可能同时出来在内容存储在文件里,我一般通过传递一个 Interable 来使用 Files::write 写到文件中。
但是我要如何很方便的处理一个简单的字符串呢?使用 Files::readAllBytes 和 Files::write 并不是特别方便, 因为这两个方法都只能处理 byte 数组。
在 Java 11 中给 Files 添加了 readString 、writeString 两个方法:
String haiku = Files.readString(Path.of("haiku.txt"));
String modified = modify(haiku);
Files.writeString(Path.of("haiku-mod.txt"), modified);
简单易用,当然,如果你有需要,你也可以将字符数组传底给 readString 方法,你也可以给 writeString 指定文件打开方式。
![]()
使用"Reader::nullReader"来处理空的 I/O 操作
你需要一个不处理输入数据的 OutputStream 时,你要怎么处理?那一个空的 InputStream 呢?Reader、Writer 呢?
在 Java 11 中,你可以做如下转换:
InputStream input = InputStream.nullInputStream();
OutputStream output = OutputStream.nullOutputStream();
Reader reader = Reader.nullReader();
Writer writer = Writer.nullWriter();
但我并不认为 null 是一个好的前缀, 我不喜欢这种意图不明确的定义。或许使用 NOOP 更好。
![]()
使用"Collection::toArray"将集合转成数组
你是如何将集合转成数组的?
// 在 Java 11 之前的版本
List list = /*...*/;
Object[] objects = list.toArray();
String[] strings_0 = list.toArray(new String[0]);
String[] strings_size = list.toArray(new String[list.size()])
第一行中,转换成了数组,但是变成了 Object,丢失了所有类型信息。那其他两个呢?它们两个使用起来非常地笨重,第一个就显得简洁得多。后者根据需要的大小创建一个数组,因此会有更好的性能(表现得更高效,详情参见 truthy),但事实上,真的会更高效吗?相反,它更慢。
我们为什么如此关心这个问题?是否有更好的办法处理它? 在 Java 11 中,你可以这么做:
String[] strings_fun = list.toArray(String[]::new);
这是集合类使用接收 IntFunction 的一个新的重载方法。也就是说,这个方法根据输入数据的长度返回一个对应长度的数组。在这里可以简洁的表示为 T[]::new。
有意思的是,toArray(IntFunction) 的默认实现总是将 0 传递给数组生成器,最开始,我应为这么做是为了更好的性能,现在我觉得,有可能是因为在某些集合的实现里面要去获取它的大小,代价是非常高的,所以没有在 Collection 中做默认实现。虽然可以覆盖像 ArrayList 这样的具体集合,但是在 Java 11 中,并没有去做,我猜是觉得不划算。
除非你已经有一个数据了,否则请使用新的方法来替换 toArray(T[]) 。当然,旧方法现在依然可以使用。
![]()
使用 'Optional::isEmpty' 而不是 'Present'
当你经常使用 Optional 的时候,特别是在与大型的没有做空检查的代码,你需要经常去检查值是不是存在。 你会经常使用 Optional::isPresent ,但是你经常会想知道哪一个 Optional 是空的。没有问题,使用 !opt.isPresent() 就可以了,但是这样对吗?
当然,那样写是没有问题的,但是那样写无法很好地理解其意思。如果你在一个很长的调用链中,想要知道它是不是空的,你就得在最前面加一个“!”。
public boolean needsToCompleteAddress(User user) {
return !getAddressRepository()
.findAddressFor(user)
.map(this::canonicalize)
.filter(Address::isComplete)
.isPresent();
}
这个“!”极易被遗忘掉。从 Java 11 开始,我们有了更好的解决方案:
public boolean needsToCompleteAddress(User user) {
return getAddressRepository()
.findAddressFor(user)
.map(this::canonicalize)
.filter(Address::isComplete)
.isEmpty();
}
![]()
使用 "Predicate::not" 来做取反
在说关于 "not" 的之前,我要说一下 Predicate 接口的 negate 方法,他返回了一个新的 Predicate —— 执行相同的测试代码,但是结果取反。不幸的是,我很少使用它:
// 打印非空字符
Stream.of("a", "b", "", "c")
// 非常丑陋 ,使用 lamba 表达式, 结果取反
.filter(string -> !string.isBlank())
// 编译错误
.filter((String::isBlank).negate())
// 强制转型,这个比lamba表达式还要丑陋
.filter(((Predicate) String::isBlank).negate())
.forEach(System.out::println);
问题是我们很少能拿到 Predicate 的引用,更常见的情况是,我想反转一个方法,但是编译器需要知道目标,如果没有目标,编译器不知道要把引用转换成什么 。所以当你使用 (String::isBlank):negate() 的时候,String::isBlank 就没有目标,编译器就会报错,虽然我们可以想办法解决它,但是成本有多大呢?
这里有一个简单的解决方案,不需要你使用实例方法 negate ,而使用 Java 11 中新的静态方法。
Predicate.not(Predicate) :
Stream.of("a", "b", "", "c")
// statically import `Predicate.not`
.filter(not(String::isBlank))
.forEach(System.out::println);
完美!
![]()
使用 "Pattern:asMatchPredicate" 处理正则表达式
你有一个正则表达式,想要基于它做一些过滤,你要怎么做?
Pattern nonWordCharacter = Pattern.compile("\\W");
Stream.of("Metallica", "Motörhead")
.filter(nonWordCharacter.asPredicate())
.forEach(System.out::println);
我非常开心,我能找到这种写法,这是 Java 8 的写法,很不幸,我错过了。
在 Java 11 中,有另外一个方法:Pattern::asMatchPredicate
它们有什么不同呢?
-
asPredicate 会检查字符串或者其字串是否符合这个正则(他的行为像 s -> this.matcher(s).find() )
-
asMatchPredicate 只会检查整个字符串是否符合这个正则(他的行为像 s -> this.matcher(s).matchs())
举个例子:你现在有一个验证手机号的正则表达式,但是这个正则表达式并不包含开始符 ^ 和结束符 $。下面代码的执行逻辑并不符合你的预期:
prospectivePhoneNumbers.stream()
.filter(phoneNumberPatter.asPredicate())
.forEach(this::robocall);
发现了它的错误了吗?"y u want numberz? +1-202-456-1414"会通过过滤检测,因为它包含了一个合法的手机号。但是使用 asMatchPredicate 就不能通过,因为整个字符串并不符合正则。
![]()
结语
上面就是 11 个不为人知的瑰宝,如果你看到这儿,那么恭喜你,通过了本次学习
1. 字符串
-
Stream lines()
-
String strip()
-
String stripLeading()
-
String stripTrailing()
-
boolean isBlank()
-
String repeat(int)
2. 路径
-
static Path of(String, String...)
-
static Path of(URI)
3. 文件
-
String readString(Path) throws IOException
-
Path writeString(Path, CharSequence, OpenOption...) throwsIOException
-
Path writeString(Path, CharSequence, Charset, OpenOption...)throws IOException
4. I/O 流
-
static InputStream nullInputStream()
-
static OutputStream nullOutputStream()
-
static Reader nullReader()
-
static Writer nullWriter()
5. 集合:T[] toArray(IntFunction)
6. 可选项:boolean isEmpty()
7. 断言:static Predicate not(Predicate)
8. 正则表达式:Predicate asMatchPredicate()
原文:https://blog.codefx.org/java/java-11-gems/
作者:Nicolai Parlog,《The Java Module System》作者。
译者:罗昭成
推荐阅读:
-
5G 爆发前夕,这些科技巨头们聚在一起“密谋”了些什么?!
-
为什么越来越少的人用 jQuery?
-
写了 300000 行基础设施代码,我学到了这五条经验
-
老码农冒死揭开行业黑幕:如何编写无法维护的代码
-
2018最后一战:25天编程PK赛!
-
想让马云成为你的老大?揭秘阿里面试情景
-
通证简史|从日进斗金到夹缝求存, 细数Token的前世今生
-
如何用 Python 实现选择排序?

![]()