HDFS-3.1.2 在W10系统下配置
环境配置
- jdk 1.8.212 (一定要1.8, 很重要!!!)
- hadoop 3.1.2
- Windows 10
https://github.com/TheLastArcher/HDFS-Configuration
先下载这个压缩包 把bin etc 俩文件夹覆盖hadoop-3.1.2 下就可以了;
我的hadoop -3.1.2 放在D:/hadoop-3.1.2; (主要和变量路径配置有关 bin,etc 关系不大)
打开cmd
输入d:
然后 start-all

会得到四个 一直存在的term
看看jps

来俩网站测试
http://localhost:8088/
http://localhost:9870/
有问题的直接下面评论
然后就是maven 模式写Java代码了
下个 IDEA 挺好用的
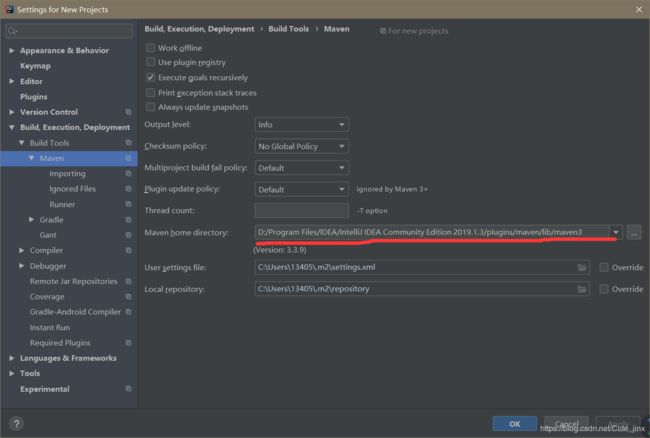
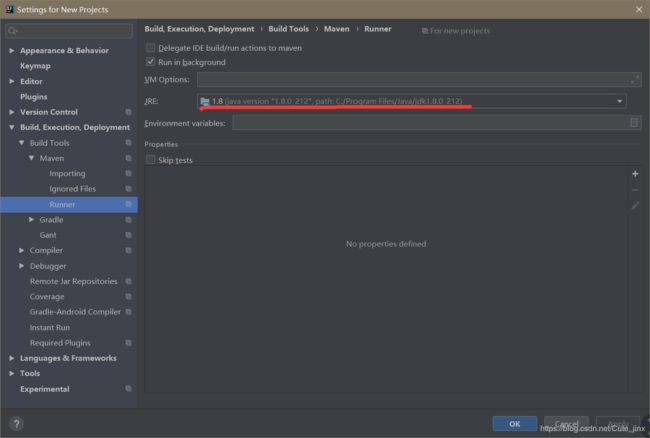
然后

再然后
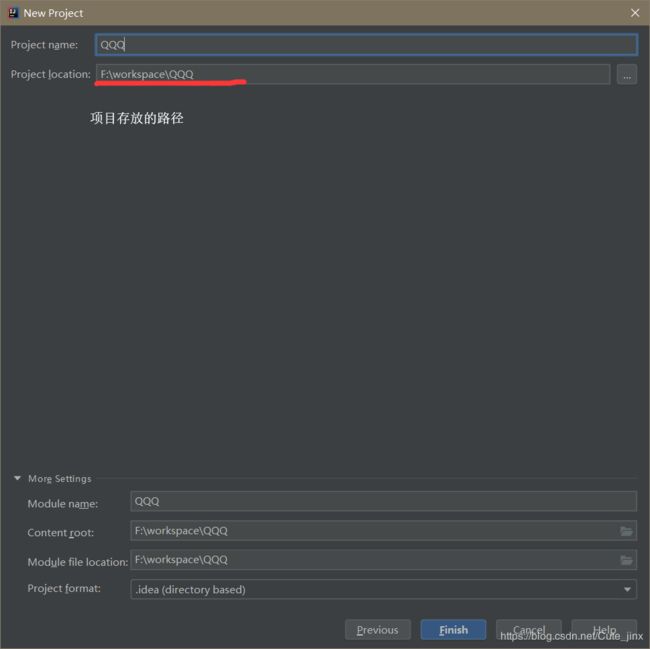
然后就建完了
打开下面这东西

敲上红框内代码 然后 点import changes

接下来 IDEA会自动下载所有的依赖文件 会好几分钟 ,如果是第一次的话,
下载完后,以后的依赖建立就不用下载,会很快就 idex 到了
然后就得到这些依赖了
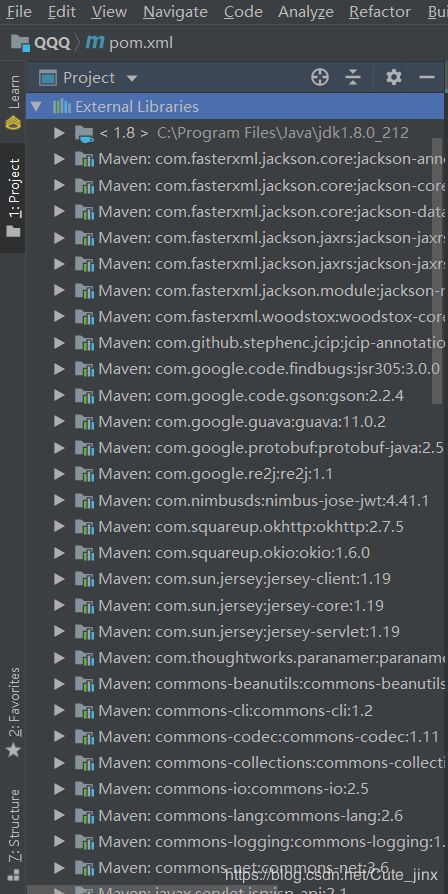
接下来D:\hadoop-3.1.2\etc\hadoop 下的 
这俩文件放在
直接复制粘贴就好
然后到此为止 环境就建好了,可以写java代码了
附带一张代码 和一丁点的数据,注意:数据是GB级别的txt文件 仅供参考
数据:
10001,2007-02-20 00:02:27,121.423167,31.165233, 7,116,3
10001,2007-02-20 00:05:36,121.423167,31.165233, 7,116,3
10001,2007-02-20 00:08:45,121.423167,31.165233, 7,116,3
10001,2007-02-20 00:11:55,121.423167,31.165233, 7,116,3
10001,2007-02-20 00:15:04,121.423167,31.165233, 7,116,3
10001,2007-02-20 00:21:22,121.423167,31.165233, 7,116,3
10001,2007-02-20 00:24:31,121.423167,31.165233, 7,116,3
10001,2007-02-20 00:37:08,121.423167,31.165233, 7,116,3
10001,2007-02-20 00:40:17,121.423167,31.165233, 7,116,3
10001,2007-02-20 00:43:26,121.423167,31.165233, 7,116,3
10001,2007-02-20 00:46:35,121.423167,31.165233, 7,116,3
10001,2007-02-20 00:49:44,121.423167,31.165233, 7,116,3
10001,2007-02-20 00:52:53,121.423167,31.165233, 7,116,3
10001,2007-02-20 00:56:02,121.423167,31.165233, 7,116,3
10001,2007-02-20 00:59:11,121.423167,31.165233, 7,116,3
10001,2007-02-20 01:05:29,121.423167,31.165233, 7,116,3
10001,2007-02-20 01:08:38,121.423167,31.165233, 7,116,3
10001,2007-02-20 01:11:47,121.423167,31.165233, 7,116,3
10001,2007-02-20 01:14:57,121.423167,31.165233, 7,116,3
10001,2007-02-20 01:18:06,121.423167,31.165233, 7,116,3
10001,2007-02-20 01:21:15,121.423167,31.165233, 7,116,3
10001,2007-02-20 01:24:24,121.423167,31.165233, 7,116,3java 里面导入的地址和导出地址都要写这样的地址
hdfs://localhost:9000/data/input/hdfs://localhost:9000/clear2/output2代码
package mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.LinkedList;
import java.util.*;
public class DataClear {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// 设置任务名称
Job job = new Job(conf, "Rec_Clear");
job.setJarByClass(DataClear.class);
// map类
job.setMapperClass(ClearMapper.class);
// map输出k-v数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 结果数据输出类型
job.setReducerClass(ClearReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 输入路径
FileInputFormat.addInputPath(job, new Path("hdfs://localhost:9000/data/input/"));
// 输出路径
String outputPath = "hdfs://localhost:9000/clear2/output2";
FileOutputFormat.setOutputPath(job, new Path(outputPath));
// 提交作业 判断退出条件(0正常退出,1非正常退出)
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static class ClearMapper extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String [] split = line.split(",");
int len = split.length;
if(len == 7){
Text k = new Text(split[0]);
context.write(k,new Text(split[1]+","+split[2]+","+split[3]));
}
}
}
public static class ClearReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
String str = new String();
for(Text x:values){
str += x.toString();
str += "\n";
}
context.write(key, new Text(str));
}
}
}
See You .