Java的字符编码问题一语道破(GBK,UTF-8,ISO-8859-1)
转载自网络
0
如果你是纯小白,那么请先阅读我的编码总结,对编码有了最基础的认识后,进行本篇文章的阅读,我可以保证你可以对Java这块会出现的编码的问题都可以自行一一解决,而且不需要借助google或者百度,全部都可以自己思考解决
1
我们从一个Java乱码的实例来抛出这个问题。
实例场景:
要求使用Java读取一个 GBK 格式的文件,使用BufferedReader的readLine读取后发现控制台输出乱码
GBK文件内容如下图所示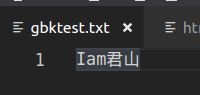
在使用Java程序读取之前,我们先来分析这个文件的二进制内容,这里先向再看这篇文章的人特别强调一点,那就是分析乱码的时候,请务必从二进制出发!虽然你会发现控制台,数据库,文件的内容输出根据编码情况变来变去的,搞的你天花乱坠,但是二进制文件是万变不离其宗的!
我们使用linux的hexdump来获取二进制数据
1 2 3 |
zazalu@zazalu-ThinkPad-E480:~/app/JavaProjectWithIDEA/MySpider/src/main/resources$ hd gbktest.txt 00000000 49 61 6d be fd c9 bd |Iam....| 00000007 |
得到了49 61 6d be fd c9 bd,这是我们这个文件的十六进制表示,随后我们逐个转换为二进制如下(不足8位的我在最前面补0了,8bit = 1byte)
1 2 |
49 61 6d be fd c9 bd 01001001 01100001 01101101 10111110 11111101 11001001 10111101 |
[注意]: 可以对照这张码表来看看hexdump程序对不对,我自己对照过了,君是befd,山是c9bd,没问题。前面的英文直接对照ASCII码表即可,都吻合!
到这里我们就知道了Iam君山这句话的GBK二进制数据表示就是01001001 01100001 01101101 10111110 11111101 11001001 10111101
2
接下来我们使用BufferedReader的readLine来读取这个片段,来重现一种乱码出现的情况!
java程序如下:
1 2 3 4 5 6 7 |
File file = new File("gbktest.txt");
try(BufferedReader bufferedReader = new BufferedReader(new FileReader(file))){
String s = "";
while ( (s = bufferedReader.readLine()) != null ){
System.out.println(s);//控制台输出 Iam��ɽ
}
}
|
这个程序读取gbktest.txt的内容并且打印到了标准输出上,也就是控制台上。
为了方便后续的讨论,我将这个程序在执行过程中存在的不同版本的字节流命名如下:
-
gbktest.txt本身的字节流,一串GBK字节流,二进制表示如下:
01001001 01100001 01101101 10111110 11111101 11001001 10111101,我们称它为GBK流 -
BufferedReader使用readLine获得到了一串字符串据s,Java的字符串内部使用Unicode编码(内码)存储,我们称它为
Unicode流 -
控制台获取s的内容打印到标准输出上的字节流,由于标准输出我这边是UTF-8编码,所以我们称它为
UTF-8流
为了理解第三节的讨论,你必须要对下面的知识点有清醒的认识
- java的String内部使用16位空间存储字符,也就是Unicode字符
- UTF-8不会一口气转换成GBK,中间必须使用Unicode字符来过渡
3
接下来我一步步来透彻的讲解这些代码发生了什么
- bufferedReader.readLine(),bufferedReader内部默认使用UTF-8编码来读取,比对Unicode表来转换字节到字符(网上可以查到),使用read,一次只读取一个字节,最后拼成一串char数组返回,所以按照它的读取规则,我们的
GBK流会被如下解析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
01001001 01100001 01101101 10111110 11111101 11001001 10111101
|
V
对照UTF-8表,发现是I,然后在Unicode的总表上查阅I字符怎么表示,最终填入char[0] = 'U+0049' 也就是'I'
01001001 01100001 01101101 10111110 11111101 11001001 10111101
|
V
对照UTF-8表,发现是a,然后在Unicode的总表上查阅a字符怎么表示,最终填入char[1] = 'U+0061' 也就是'a'
01001001 01100001 01101101 10111110 11111101 11001001 10111101
|
V
对照UTF-8表,发现是m,然后在Unicode的总表上查阅m字符怎么表示,最终填入char[2] = 'U+006D' 也就是'm'
01001001 01100001 01101101 10111110 11111101 11001001 10111101
|
V
对照UTF-8表,发现不对,UTF-8码表规则不允许用10开头!(UTF-8码表规则在下面附上,请自己比对)
针对这种情况,转换规则里存在一种机制,会把不允许的字节全部自动变成一个叫"[置换字符](https://en.wikipedia.org/wiki/Specials_(Unicode_block)#Replacement_character"的东西!UTF-8的置换字符为�,在Unicode总表上查出来,所以char[3] = 'U+FFFD' 也就是'�'
01001001 01100001 01101101 10111110 11111101 11001001 10111101
|
V
对照UTF-8表,和上面情况一样,发现不允许11111开头!所以char[4] = 'U+FFFD' 也就是'�'
01001001 01100001 01101101 10111110 11111101 11001001 10111101
| |
V V
对照UTF-8表,发现是第一个字节110开头第二个字节10开头,符合utf-8双字节表示的情况!所以一口气读取2个字节,转换成Unicode码为`U+027D`.所以char[5] = 'U+027D' 也就是'ɽ'1
2
3
4
5
6
7
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx所以综上所述,我们的String s的内容的Unicode码为U+0049 U+0061 U+006D U+FFFD U+FFFD U+027D
这串Unicode的码就是我们读取后java底层保存的真正内容!也就是Iam��ɽ
从这里我们其实已经得到了答案,那就是BUfferedReader的这种读取方式直接就把我们的源文件流内容完全变掉了,变成了一串新的东西,错就错在它读取的时候按照UTF-8的规则来转换,把本来应该双字节双字节为单位读取的二进制数据,’翻译’成了另一个样子!
4
那么我们现在的关键问题是,这串Unicode码能不能通过简单的方式转换为没有乱码的样子?
在网上流行的方法会让你这么做:
1
System.out.println(new String(s.getBytes("ISO-8859-1"),"GBK"));//这个在一些例子里可以成功实现快速转换,但是在我们这个例子是行不通的!为什么?下面解释类比到我们这个例子里,也许就是这么做
1
System.out.println(new String(s.getBytes("UTF-8"),"GBK"));//输出 Iam锟斤拷山可以看到输出变成了’Iam锟斤拷山’,和我们本来的意思不一样了!所以它虽然看上去变成中文了,但是实际上依旧是乱码!下面依旧一步步来给你解释为什么会这样!
首先s.getBytes("UTF-8"),这个代码的意思是将字符串s的Unicode码(内码)转换为UTF-8码,返回一个byte[],如下
1
2
3
4
5
6
由于UTF-8很多是三字节的,用二进制表示会太长不已阅读,这里就用十六进制表示下,你可以自己转
Unicode:
U+0049 U+0061 U+006D U+FFFD U+FFFD U+027D
使用UTF-8码表翻译Unicode,得到如下二进制数据:
01001001 01100001 11001001 11101111 10111111 10111101 11101111 10111111 10111101 11001001 10111101所以我们得到的byte数组内容就是01001001 01100001 11001001 11101111 10111111 10111101 11101111 10111111 10111101 11001001 10111101
其次new String(s.getBytes("UTF-8"),"GBK")的第二个参数会用GBK的字节读取规则来转换这个byte[],把它变成Unicode码最后存在字符串s中,如下所示:
1
2
3
4
5
6
7
8
byte[]:
01001001 01100001 11001001 11101111 10111111 10111101 11101111 10111111 10111101 11001001 10111101
先转换为GBK
0049 0061 006D EFBF BDEF BFBD C9BD
然后转换为Unicode存储至String中
I a m 锟 斤 拷 山所以我们通过这个方式转换后,得到了输出为Iam锟斤拷山
[小节]: 所以单纯使用System.out.println(new String(s.getBytes("UTF-8"),"GBK"));这种方式来教别人转换是有点误导向的。这种方式的本来意思就是用前者的编码将Unicode转换为UTF-8格式的Byte[],然后再用GBK的码表把这个Byte数组转换为Unicode! 这个过程的作用简直就是搞笑!这个代码也是让我哭笑不得。但是也有些情况用这个代码可以实现快速的转换,比如System.out.println(new String(s.getBytes("ISO-8859-1"),"GBK"));,这是因为ISO-8859-1是8位的编码格式,它正好把一个中文对半拆分成了2个字符,由于是对半的,所以转换为byte数组的时候,结果是一样的,就可以歪打正着的还原回去了!真的哭笑不得
5
本次的编码课题就到此结束了,有问题的小伙伴可以在下面评论,看不多评论是因为你没有使用科学上网工具
参考:GBK码表
参考:Unicode字符对应所有的编码如何表示的网站,很好用
参考:在线进制转换工具
参考:Unicode码表
参考:UTF-8码表