惊艳!基于RNN的AI写词机竟能写出如此优秀的情诗!
七夕至。各位同学今晚需要加班不?

如果不加,又没什么人需要陪,看我的安排!
近日,TinyMind的诗词达人秀上出现了一枚优秀的AI写词机,这小AI擅长宋词创作,行云流水,妙笔生花,以独特的文风与智慧艳压全场!咱们先围观几首~~
♥爱情♥
只有一川烟月,不管青鸿一梦,何处是高楼。老子不堪见,明日隔江风。
我们不难发现小宋在情场中干脆利落,不拖泥带水,专一且霸道!
♥蓦山溪♥
莺来多息。不似花枝处。妙力不知春,更不见、江南一片。
不怜花柳,容尽一年春,花外下,水风深,谁是相思处。
黄台池外,一断无人到。天草不知人,对一里、黄昏千片。
一年心事,谁似旧人愁,情易遣,泪花前,寂寞花前减。
可能在七夕这天,小宋更感孤独,旧事涌上心头,“谁似旧人愁”,多情总被无情恼,“情易遣,泪花前”,怕是在去年七夕小宋被放生了。。
这首词通篇虽不如人类作品的剧情连贯,但细细品味每一句,都能让人看到灵性~!
“天草不知人,对一里、黄昏千片”,黄昏千片,这样的神搭配,请收下我的膝盖!
♥满江红♥
风雨凄凉,又还是、一番春色。
春又老、春风吹柳,满庭花落。
花影未禁春又老,柳丝袅袅胭脂薄。
问几年、春色入东风,春无力。
花不尽,春无力。
春不住,花无力。
想东君、莫放春衫,为谁偷惜。
一笑相思千万斛,一杯一醉君须说。
问何时、一醉醉中仙,从今日。
本是悲愤基调,在小宋笔下更多是无奈。“花影未禁春又老,柳丝袅袅胭脂薄。”如果说这是AI的杰作,你会跟我一样首先质疑吧?最后一句更是为通篇的"无奈"找到了出口,“一醉醉中仙,从今日。”谁敢说上下文没有连贯性,请你承包小宋一年的酒钱!
作为新一代AI诗词创作界扛把子,小宋的作品是源源不断层出不穷的。咱们先赏析到此,下面大戏来了!
你想拥有这样一个灵魂写词机吗?!作者(TinyMind用户名:HataFeng)已将代码模型公开啦!!!下面请跟我手把手学会造一个写词机!!至于2号,3号会是什么性格,你定~

小宋的模型基于循环神经网络来搭建
模型主要结构:词嵌入 + 多层LSTM
词嵌入采用:skip-gram + dropout
循环神经网络采用:多层LSTM + dropout
输出层采用:softmax
参数共享采用:softmax层和词向量层参数共享
损失采用:交叉熵、平均损失
优化采用:SGD
评价方法采用:复杂度(perplexity) 公式:
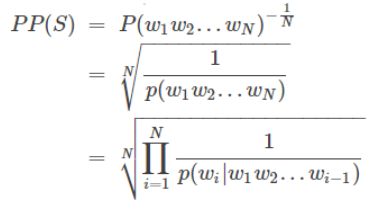
代码运行:
准备数据:sc.train 和 sc.vocab (已上传到tinymind 地址:https://www.tinymind.com/HataFeng/datasets/songci)
运行环境:
windows 或 tinymind 支持GPU或者CPU Tensorflow 1.4 python3.6 本地windows运行:
Cd code_path
python train.py --num_layers=2 --Optimizer="SGD" --learning_rate=0.1 --dataset="sc.train"
预测命令
python inference.py --train_dir="G:/test_data/songci/output/CT500_10_SGD"
代码框架:
数据预处理模块
模型模块
预测模块
模块说明:
数据预处理模块
整理数据
编码
训练模块
1.输入层:minibatch 词嵌入 + dropout
2.处理层:网络结构采用多层LSTM + dropout
3.输出层:softmax
4.Lost:交叉熵
5.优化:SGD或者adam
6.评价:复杂度。
预测结构:
1.输入层:词嵌入
2.处理层:网络结构采用多层LSTM + dropout
3.输出层:softmax
4.Lost:交叉熵
5.输出:top3 label 进行预测输出
代码说明文档
preprefile.ipynb 用空格对单词进行分割(切词后如下: 酒 泉 子 ( 十 之 一 ))
prefile.ipynb 按升序生成词表
encode.ipynb 将文本转化为单词编码(编码后如下:72 297 50 27 99 137 7 28 2)
train.py 训练程序
inference.py 预测模块
训练模块关键代码说明:
# 定义使用LSTM结构为循环体结构且使用dropout的深层循环神经网络
# NUM_LAYERS 网络深度层数
# HIDDEN_SIZE 神经元数量
dropout_keep_prob = LSTM_KEEP_PROB if is_training else 1.0
lstm_cells = [
tf.nn.rnn_cell.DropoutWrapper(
tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE),
output_keep_prob=dropout_keep_prob)
for _ in range(NUM_LAYERS)]
cell = tf.nn.rnn_cell.MultiRNNCell(lstm_cells)
.....
# 将输入单词转化为词向量
#skip-gram模型
inputs = tf.nn.embedding_lookup(embedding, self.input_data)
# 对输入数据进行dropout
if is_training:
inputs = tf.nn.dropout(inputs, EMBEDDING_KEEP_PROB)
....
# 收集LSTM不同时刻的输出
outputs = []
state = self.initial_state
with tf.variable_scope("RNN"):
for time_step in range(num_steps):
if time_step > 0: tf.get_variable_scope().reuse_variables()
cell_output, state = cell(inputs[:, time_step, :], state)
outputs.append(cell_output)
output = tf.reshape(tf.concat(outputs, 1), [-1, HIDDEN_SIZE])
if SHARE_EMB_AND_SOFTMAX:
weight = tf.transpose(embedding)
else:
weight = tf.get_variable("weight", [HIDDEN_SIZE, VOCAB_SIZE])
bias = tf.get_variable("bias", [VOCAB_SIZE])
logits = tf.matmul(output, weight) + bias
# 分类输出
self.predictions = tf.nn.softmax(logits, name='predictions')
# 真实分布与预测分布的交叉熵
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=tf.reshape(self.targets, [-1]),
logits=logits)
self.cost = tf.reduce_sum(loss) / batch_size
self.final_state = state
# 梯度优化
print("FLAGS.Optimizer:", FLAGS.Optimizer)
if FLAGS.Optimizer == "adam":
print("use adma Optimizer learning_rate:", LEARNING_RATE)
optimizer = tf.train.AdamOptimizer(learning_rate=LEARNING_RATE)
else:
optimizer = tf.train.GradientDescentOptimizer(learning_rate=LEARNING_RATE)
# 训练步骤
self.train_op = optimizer.apply_gradients(zip(grads, trainable_variables), global_step=self.global_step)
天意事,谁堪得。
非易事,欢难说。
新一代AI杰出作家小宋想与小冰一比高低,请问你皮克谁?
更多关于小宋的诗词及详细说明请参考:
https://www.tinymind.cn/codes/97
想动手造写词机的同学请下载数据集:
https://www.tinymind.cn/articles/719
点击♥阅读原文♥,查看小宋的前世今生~