翻译们又要失业?Facebook最新无监督机器翻译成果,BLEU提升10个点!

作者 | 琥珀
出品 | AI科技大本营(公众号ID:rgznai100)
神经机器翻译(NMT)关注的是通过 AI 在不同人类语言之间进行翻译的过程。2015 年,蒙特利尔学习算法研究所的研究人员开发出了一项新的算法模型,最终让机器给出了对应的翻译。一夜之间,像谷歌翻译这样的翻译软件质量得到了大幅度提升。
尽管此次改进非常显著,但它仍需要两种语言的句子对,例如:“I like to eat”和“me gusta comer”分别为英语和法语中的“我想要吃”。对于从乌尔都语到英语等没有句子对的语言翻译而言,翻译系统则显得无能为力。从那时起,研究人员就开始构建无需句子对也能翻译的系统,无监督神经机器翻译(UNMT)就是其一。
去年 10 月末,来自西班牙圣塞巴斯蒂安巴斯克大学(UPV)和互联网科技公司 Facebook 人工智能研究院(FAIR)的两支团队,向2018ICLR分别递交了各自的最新研究成果——无监督神经网络翻译模型。
当时,两篇论文共同表明,神经网络可以在没有平行文本的情况下学习翻译。
(链接:https://arxiv.org/abs/1710.11041;https://arxiv.org/abs/1711.00043)
这意味着该模型将突破原有的神经机器翻译(NMT)需要足够大的平行语料库的限制,创造了一种可以使用单语语料库进行训练的翻译模型,并克服了平行语料库不足的问题。 从社会学的角度讲,这将有助于我们翻译一些语言已经丢失了的文字,或者让机器去实时翻译一些稀有语言,如斯瓦西里语和白俄罗斯语。
过去一年间,不断有研究人员试图通过无监督学习用大量无标记数据训练以进一步提高系统的翻译能力。Facebook、纽约大学、巴斯克大学、索邦大学的研究团队成果显著,成功让机器在不知道“house”的西班牙对应词是“casa”的情况下翻译出来。
近日,Facebook 人工智能实验室再次公布了有关无监督神经网络翻译的最新模型,相当于用 10 万个参考译文训练过的监督模型。“在机器翻译领域,这是一个重大的发现,尽管世界上有超过 6500 种语言,但可利用的翻译训练资源池要么不存在、要么就是太小不足以运用在现有系统中。”
为了证明这一进步的价值,研究人员给出了以下陈述:“ 1 个 BLEU 点(判断机器翻译准确度的常用指标)的进步被视为该领域一项了不起的成就。我们的方法相当于有 10 个 BLEU 点的进步。” 实际上,该项研究使得很多没有平行文本的语言翻译变得更为容易,如从乌尔都语到英语的翻译。
▌研究原理
1、字节对编码:不像此前为系统提供完整单词的方式,只给系统提供单词的一部分。例如,单词“hello”可拆分为四部分,分别是“he”“l”“l”“o”。这意味系统可以学习“he”的译词,尽管系统此前从来没有见过该词。
2、语言模型:训练神经网路学习生成在语言中“听起来不错”的句子。例如,这个神经网络可能会将句子“您好嘛”改为“您好吗”。
3、反向翻译:这是神经网络学习向后翻译的另一个技巧。例如,如果想将西班牙语翻译称英语,就需要先教会神经网络从英语翻译成西班牙语,然后用它来生成合成数据,从而增加已有的数据量。
▌逐字翻译
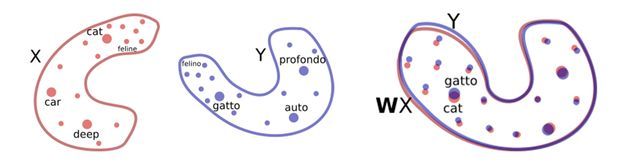
让系统学习双语词典,将一个单词与其他语言的合理翻译联系起来,即系统学习每种语言中的单词嵌入。
训练嵌入词以预测跟给定上下文中单词近似的单词,可以发现很多有趣的语义结构。例如,“kitty”的近义词是“cat”,而“kitty”的嵌入词与“animal”相近,却与“rocket”相差很远。
此外,不同语言的嵌入词有相似的领域结构,这在于世界各地的人都拥有相同的物理环境。例如,英语中的单词“cat”和“furry”之间的关系类似于它们在西班牙语中的相应翻译(“gato”和“peludo”),因为这些单词的频率和其上下文是相似的。
鉴于这些相似之处,研究人员建议使用对抗训练,以推导出一个相当准确的双语词典,无需访问任何平行文本,便可实现逐字翻译。
▌句子修正
不过,研究人员还是建议无监督的方式进行逐字翻译,也有可能造成单词丢失,或无序甚至是错误。所以,接下来,需要在已知大量单词数据的基础上进行编辑,对不流畅或不符合语法结构的句子进行修正。
另外,研究人员还给出以下两种方法,一个是基于神经网络的系统(NMT),一个是基于短语的系统(PBSMT)。虽然任何一种方法都可以提高翻译质量,但二者并用将产生更新的显著效果。
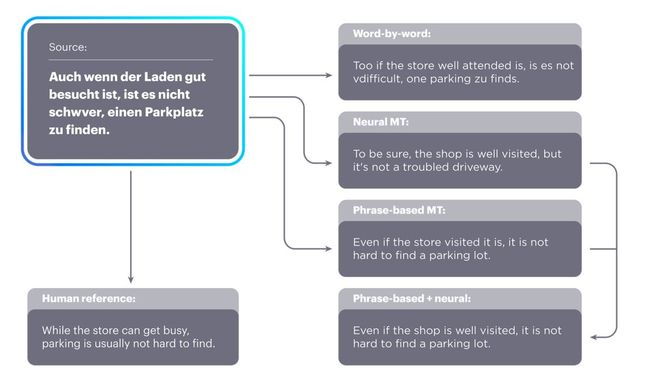
据了解,PBSMT(Facebook统计机器翻译)是 FAIR 此前的研究成果。该系统学习每种语言中短语的概率分布,并教会另一个系统旋转第二组的数据点以匹配第一组的数据点。
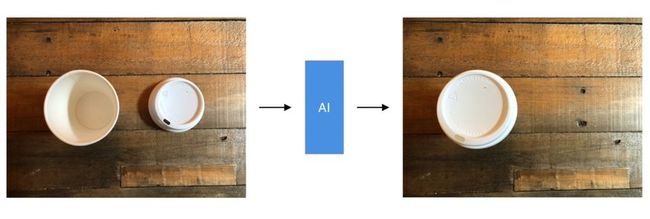
以一个比较形象的方式展示:假设有两个图像,一个是杯子与盖子彼此相邻,另一个是盖子在杯子上。该系统将学习如何在没有盖子的情况下,在图像周围移动像素以生成有盖子的图像。
目前,Facebook 人工智能实验室将免费开放代码,方便开发者获取搭建系统。
▌写在最后
要知道,多数现有的 AI 模型是通过“监督学习”训练而成的,这也意味着必须耗费大量的人力对样本数据进行标记与分类。尽管强化学习与生成式对抗网络的出现从一定程度上解决了这一问题,但数据标记仍是目前阻碍 AI 系统发展的最大障碍。
参考链接:
https://code.fb.com/ai-research/unsupervised-machine-translation-a-novel-approach-to-provide-fast-accurate-translations-for-more-languages/
——完——
AI科技大本营现招聘内容运营实习生,有意者请将简历投至:[email protected],期待你的加入!
工作要求:
熟练使用微信、今日头条等平台发布文章,并负责其他对外推广渠道的内容铺建,用户管理以及互动;
追踪AI领域动态,协助AI内容生产;
能保证每周三天的工作时间。
工作地点:
北京市朝阳区酒仙桥路10号院恒通商务园仙桥路10号院恒通商务园

AI科技大本营在线公开课第15期
◆
机器学习专场
◆
时间:9月6日 20:00-21:00
形式:线上直播+社群答疑
添加小助手微信csdnai,备注:机器学习
邀你加入课程交流群,即有机会获得定制T恤或者技术书籍
