python爬虫自动下载网页链接
需求分析
今天遇到一个简单的需求,需要下载澳大利亚电力市场NEM日前市场的发电商报价数据(http://nemweb.com.au/Reports/Current/Next_Day_Offer_Energy/),页面观感是这样的:
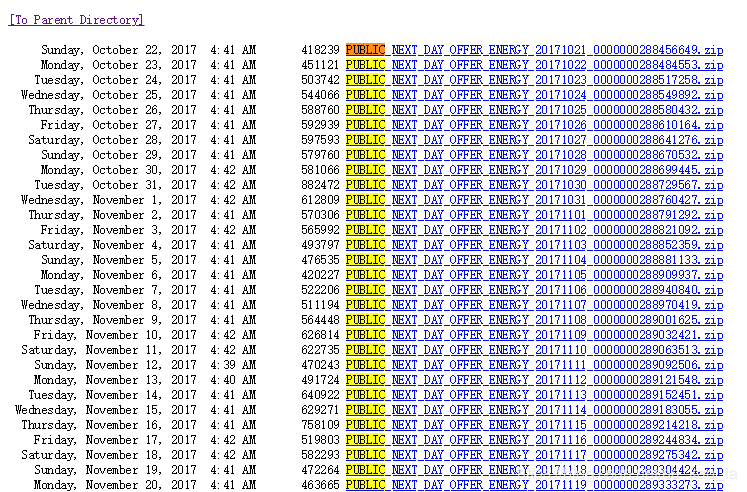
Ctrl + F 一下,看到一共有395个zip链接。于是就想着用python爬虫自动下载。这个网页很简单,没有验证码,甚至不需要登录,因此自动下载的python代码也很简单。
步骤
爬取链接主要是如下3步:
1. 第一步是爬取网页内容,保存在一个字符串content中
content的观感是这样的
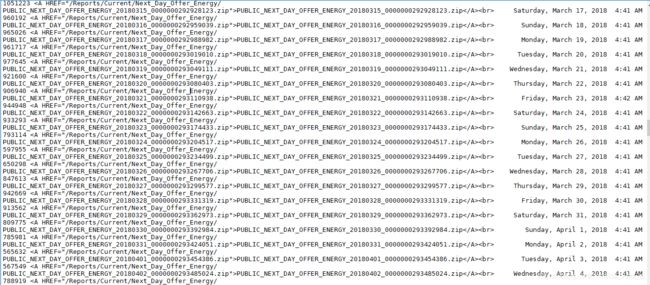
从中可以看到链接是以'PUBLIC_NEXT_DAY_OFFER_ENERGY_(\d*)_(\d*).zip'的形式出现的,而且出现了两遍。
2. 第二步是构造正则表达式,从content中匹配下载链接
正则表达式构造为'(PUBLIC_NEXT_DAY_OFFER_ENERGY_(\d*)_(\d*).zip)',re.findall会返回一个三元tuple,分别是 (整个匹配到的字符串,第一个(\d*),第二个(\d*)). 由于上面提到了链接出现了两遍,所以可以用list转set来去重。
3. 第三步是遍历链接的set,下载链接
这一步就很trivial了,唯一要注意的是如果下载下来的文件所在的目录不存在,要提前作判断,建新目录。
结果
Done!
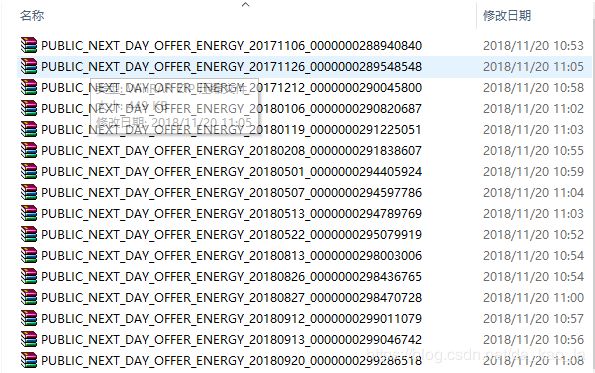
源代码
"""
Created on Tue Nov 20 09:50:26 2018
@author: weiyx15
Automated downloading all data links from
http://nemweb.com.au/Reports/Current/Next_Day_Offer_Energy/
"""
import urllib.request# url request
import re # regular expression
import os # dirs
# parent url
url = 'http://nemweb.com.au/Reports/Current/Next_Day_Offer_Energy/'
# regular expression
pattern = '(PUBLIC_NEXT_DAY_OFFER_ENERGY_(\d*)_(\d*).zip)'
# pull request
headers = {'User-Agent', 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36'}
opener = urllib.request.build_opener()
opener.addheaders = [headers]
content = opener.open(url).read().decode('utf8')
# match regex and drop repetition
raw_hrefs = re.findall(pattern, content, 0)
hset = set(raw_hrefs)
# make directory
if not os.path.exists('./auto_download'):
os.makedirs('auto_download')
# download links
for href in hset:
link = url + href[0]
print(link)
urllib.request.urlretrieve(link, os.path.join('./auto_download', href[0]))