从零开始学深度学习二:神经网络
本课程笔记来源于深享网课程《深度学习理论与实战TensorFlow》
2.1学习的种类
学习的种类主要分成以下三类:监督学习、非监督学习和强化学习三种。接下来,将分别对这三种学习进行介绍。
监督学习:
对已经标记的训练样本进行学习,然后对样本外的数据进行标记预测。如常见的分类垃圾邮件问题就是常见的监督学习,我们需要对训练样本的邮件进行标记(就是每一封邮件都要人为去指定,然后通过学习,模型对新来的邮件判断其是否是垃圾邮件)。
非监督学习:
对没有标记过的训练样本进行学习,发现其中的结构性知识。如我们可以对商店中的顾客进行聚类,将他们分成不同的细分市场。
强化学习:
可以理解为一个机器人不断依据环境做决策,然后环境根据决策进行奖励或惩罚,机器人将根据环境给予的反馈来学习的方式。我们可以以小时候我们被妈妈打的情况为例进行说明;我们放学回家没有做作业就出去玩,然后就被妈妈教训了,第二次还是这样,又被妈妈教训了,第三次我们会根据前两次的反馈知道我们应该先做作业然后出去玩,然后妈妈奖励你了一根糖果,第四次你就会先做作业,这就是一个强化学习的过程举例。
2.2线性模型
线性模型在我们的实际生活中有非常广泛的应用。举例来说,我们每天学习4个小时,考试可以得到8分,那么如果每天学习五个小时呢,这个问题就可以通过线性模型来进行预测。

一元线性回归
一元线性模型非常简单,这里我们以医院线性回归为例进行说明。假设我们有变量 x i x_{i} xi和目标 y i y_{i} yi,每个 i i i对应一个数据点,我们希望建立一个模型 y i ^ = w x + b \widehat{y_{i}}=wx+b yi =wx+b
其中 y i ^ \widehat{y_{i}} yi 是我预测的结果,我们希望通过 y i ^ \widehat{y_{i}} yi 来拟合目标 y i y_{i} yi,通俗来讲就是找到这个函数拟合 y i y_{i} yi,使其误差最小,即最小化: 1 n ∑ i = 1 n ( y i ^ − y i ) 2 \frac{1}{n}\sum_{i=1}^{n}\left ( \widehat{y_{i}}-y_{i}\right )^{2} n1i=1∑n(yi −yi)2
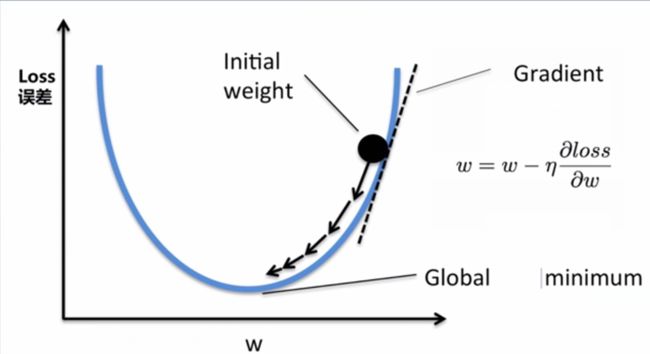
为了找到这个函数,我们首先给定一个初始的 w w w和 b b b,然后通过这个初始 w w w和 b b b来计算出预测的结果,以此来优化 w w w和 b b b,即梯度下降法。
多项式回归模型
在一元线性回归的基础上,我们进一步考虑多项式回归模型,根据上面给出的线性回归模型 y i ^ = w x + b \widehat{y_{i}}=wx+b yi =wx+b这是一个关于 x x x的一次多项式,这个模型比较简单,没法拟合比较复杂的模型,所以我们可以使用更高次的模型,比如 y i ^ = w 0 + w 1 x + w 2 x 2 + w 3 x 3 + . . . \widehat{y_{i}}=w_{0}+w_{1}x+w_{2}x^{2}+w_{3}x^{3}+... yi =w0+w1x+w2x2+w3x3+....这样就可以拟合更加复杂的模型,这就是多项式模型,这里运用的 x x x的更高次。同理还有多元回归模型,其他都一样,只是除了使用 x x x,还有更多的变量如 y y y, z z z等。
2.3梯度下降
首先我们来讨论什么是梯度,梯度就是导数,比如 f ( x ) = x 2 f\left ( x \right )=x^{2} f(x)=x2在 x = 1 x=1 x=1处的梯度就是2.
对于更一般的情况,如果有多个变量,那么梯度就是对每个变量的导数,比如 f ( x , y ) f\left ( x,y \right ) f(x,y)的梯度就是 ( ∂ f ∂ x , ∂ f ∂ y ) \left ( \frac{\partial f}{\partial x},\frac{\partial f}{\partial y} \right ) (∂x∂f,∂y∂f)
我们可以称其为grad f ( x , y ) f\left ( x,y \right ) f(x,y)或者 ▽ f ( x , y ) \bigtriangledown f\left ( x,y \right ) ▽f(x,y).具体某一点( x 0 x_{0} x0, y 0 y_{0} y0)的梯度就是 ▽ f ( x 0 , y 0 ) \bigtriangledown f\left ( x_{0},y_{0} \right ) ▽f(x0,y0)
下图即为 f ( x ) = x 2 f\left ( x \right )=x^{2} f(x)=x2这个函数在 x = 1 x=1 x=1处的梯度;
从集合意义上讲,一个点的梯度值就是这个函数下降最快的地方,具体来说,对于函数 f ( x ) = x 2 f\left ( x \right )=x^{2} f(x)=x2,在点( x 0 x_{0} x0, y 0 y_{0} y0)处,沿着梯度 ▽ f ( x 0 , y 0 ) \bigtriangledown f\left ( x_{0},y_{0} \right ) ▽f(x0,y0)的方向,函数下降的最快,也就是说沿着梯度下降的方向,我们能更快的找到函数的极大值点,或者反过来沿着梯度的反方向,我们能更快的找到函数的最小值点。
利用梯度下降法,我们可以通过反复迭代找到最合适的 w w w和 b b b,这一部分已在之前的文章
梯度下降法三种形式BGD、SGD、MBGD比较中给出详细介绍,在此不再赘述。