数据结构——栈与队列(顺序栈、链栈、循环队列、链队列)
提示:以下内容不适合零基础人员,仅供笔者复习之用。
概要:
栈是限定仅在表尾进行插入和删除操作的线性表。
队列是只允许在一端进行插入操作、而在另一端进行删除操作的线性表。
一、栈
1. 定义
栈是限定仅在表尾进行插入和删除操作的线性表。(又称后进先出的线性表)
2. 抽象数据类型

3. 栈的顺序存储结构及实现
#define MAXSIZE 20 /* 存储空间初始分配量 */
typedef int Status;
typedef int SElemType; /* SElemType类型根据实际情况而定,这里假设为int */
/* 顺序栈结构 */
typedef struct
{
SElemType data[MAXSIZE];
int top; /* 用于栈顶指针 */
}SqStack;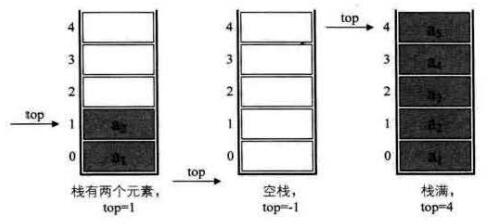
3.1 操作
#include "stdio.h"
#include "stdlib.h"
#include "io.h"
#include "math.h"
#include "time.h"
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
#define MAXSIZE 20 /* 存储空间初始分配量 */
typedef int Status;
typedef int SElemType; /* SElemType类型根据实际情况而定,这里假设为int */
/* 顺序栈结构 */
typedef struct
{
SElemType data[MAXSIZE];
int top; /* 用于栈顶指针 */
}SqStack;
Status visit(SElemType c)
{
printf("%d ",c);
return OK;
}
/* 构造一个空栈S */
Status InitStack(SqStack *S)
{
/* S.data=(SElemType *)malloc(MAXSIZE*sizeof(SElemType)); */
S->top=-1;
return OK;
}
/* 把S置为空栈 */
Status ClearStack(SqStack *S)
{
S->top=-1;
return OK;
}
/* 若栈S为空栈,则返回TRUE,否则返回FALSE */
Status StackEmpty(SqStack S)
{
if (S.top==-1)
return TRUE;
else
return FALSE;
}
/* 返回S的元素个数,即栈的长度 */
int StackLength(SqStack S)
{
return S.top+1;
}
/* 若栈不空,则用e返回S的栈顶元素,并返回OK;否则返回ERROR */
Status GetTop(SqStack S,SElemType *e)
{
if (S.top==-1)
return ERROR;
else
*e=S.data[S.top];
return OK;
}
/* 插入元素e为新的栈顶元素 */
Status Push(SqStack *S,SElemType e)
{
if(S->top == MAXSIZE -1) /* 栈满 */
{
return ERROR;
}
S->top++; /* 栈顶指针增加一 */
S->data[S->top]=e; /* 将新插入元素赋值给栈顶空间 */
return OK;
}
/* 若栈不空,则删除S的栈顶元素,用e返回其值,并返回OK;否则返回ERROR */
Status Pop(SqStack *S,SElemType *e)
{
if(S->top==-1)
return ERROR;
*e=S->data[S->top]; /* 将要删除的栈顶元素赋值给e */
S->top--; /* 栈顶指针减一(重要) */
return OK;
}
/* 从栈底到栈顶依次对栈中每个元素显示 */
Status StackTraverse(SqStack S)
{
int i;
i=0;
while(i<=S.top)
{
visit(S.data[i++]);
}
printf("\n");
return OK;
}
int main()
{
int j;
SqStack s;
int e;
if(InitStack(&s)==OK)
for(j=1;j<=10;j++)
Push(&s,j);
printf("栈中元素依次为:");
StackTraverse(s);
Pop(&s,&e);
printf("弹出的栈顶元素 e=%d\n",e);
printf("栈空否:%d(1:空 0:否)\n",StackEmpty(s));
GetTop(s,&e);
printf("栈顶元素 e=%d 栈的长度为%d\n",e,StackLength(s));
ClearStack(&s);
printf("清空栈后,栈空否:%d(1:空 0:否)\n",StackEmpty(s));
return 0;
}
3.2 两栈共享空间
用一个数组来存储两个栈。如图,两个栈有两个栈底,让一个栈的栈底为数组的始端,即下标为0处,另一个栈的栈底为数组的末端,即下标为数组长度n-1处。这样,两个栈如果要增加元素,就是两端点向中间延伸。

形成的新数组:0、1、2、……n-2、n-1
使用场景:两个栈的空间需求有相反关系时,即一个栈增长另一个栈缩短时。(就像买股票,有人买入就定有人卖出)
使用前提:两个具有相同数据类型的栈。
关键:top1和top2是栈1和栈2的栈顶指针,只要他两不相见,两个栈就可以一直使用。
结构分析
- 空栈:栈1为空时,top1=-1。栈2为空时,top2=n。
- 满栈:极端情况下,栈2为空,则栈1 的top1=n-1时,栈1满了;反之,栈1为空,则栈2的top2=0时,栈2满了。一般情况下,两个栈见面时,即top1+1=top2时,可认为栈满。
结构代码:
#define MAXSIZE 20 /* 存储空间初始分配量 */
typedef int Status;
typedef int SElemType; /* SElemType类型根据实际情况而定,这里假设为int */
/* 两栈共享空间结构 */
typedef struct
{
SElemType data[MAXSIZE];
int top1; /* 栈1栈顶指针 */
int top2; /* 栈2栈顶指针 */
}SqDoubleStack;
/* 插入元素e为新的栈顶元素,stackNumber用于判定是栈1还是栈2 */
Status Push(SqDoubleStack *S,SElemType e,int stackNumber)
{
if (S->top1+1==S->top2) /* 栈已满,不能再push新元素了(防止溢出) */
return ERROR;
if (stackNumber==1) /* 栈1有元素进栈 */
S->data[++S->top1]=e; /* 若是栈1则先top1+1后给数组元素赋值。 */
else if (stackNumber==2) /* 栈2有元素进栈 */
S->data[--S->top2]=e; /* 若是栈2则先top2-1后给数组元素赋值。 */
return OK;
}
/* 若栈不空,则删除S的栈顶元素,用e返回其值,并返回OK;否则返回ERROR */
Status Pop(SqDoubleStack *S,SElemType *e,int stackNumber)
{
if (stackNumber==1)
{
if (S->top1==-1)
return ERROR; /* 说明栈1已经是空栈,溢出 */
*e=S->data[S->top1--]; /* 将栈1的栈顶元素出栈 */
}
else if (stackNumber==2)
{
if (S->top2==MAXSIZE)
return ERROR; /* 说明栈2已经是空栈,溢出 */
*e=S->data[S->top2++]; /* 将栈2的栈顶元素出栈 */
}
return OK;
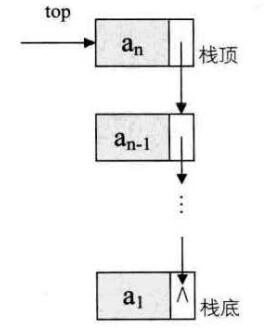
}4. 栈的链式存储结构及实现
状态分析:
基本不存在栈满(溢出)的情况,除非内存已没有可用空间,此时计算机系统已近崩溃。
链栈为空,top=NULL;
结构代码:
/* 链栈结构 */
typedef struct StackNode
{
SElemType data;
struct StackNode *next;
}StackNode,*LinkStackPtr;
typedef struct
{
LinkStackPtr top;
int count;
}LinkStack;进栈:
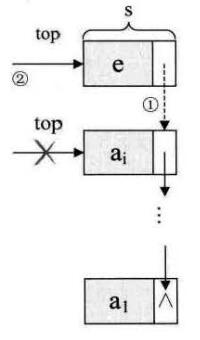
/* 插入元素e为新的栈顶元素 */
Status Push(LinkStack *S,SElemType e)
{
LinkStackPtr s=(LinkStackPtr)malloc(sizeof(StackNode));
s->data=e;
s->next=S->top; /* 把当前的栈顶元素赋值给新结点的直接后继,见图中① */
S->top=s; /* 将新的结点s赋值给栈顶指针,见图中② */
S->count++;
return OK;
}
/* 若栈不空,则删除S的栈顶元素,用e返回其值,并返回OK;否则返回ERROR */
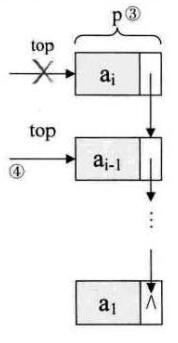
Status Pop(LinkStack *S,SElemType *e)
{
LinkStackPtr p;
if(StackEmpty(*S))
return ERROR;
*e=S->top->data;
p=S->top; /* 将栈顶结点赋值给p,见图中③ */
S->top=S->top->next; /* 使得栈顶指针下移一位,指向后一结点,见图中④ */
free(p); /* 释放结点p */
S->count--;
return OK;
}5. 顺序栈和链栈的对比
相同点:时间复杂度上一样,均为O(1)。
不同点:空间性能上
顺序栈
优点:存取时定位方便。
缺点:需要事先确定一个固定的长度,可能会存在内存空间浪费的问题。
链栈
优点:对栈长度无限制。
缺点:要求每个元素都有指针域,增加了内存开销。
综上,如果栈的使用过程中元素变化不可预料,有时很小有时非常大,那么最好使用链栈。反之,如果它的变化在可控范围内,建议使用顺序栈会更好一些。
二、队列
1. 定义
只允许在一端进行插入操作,而在另一端进行删除操作的线性表。
2. 抽象数据类型

3. 循环队列
3.1 队列顺序存储的不足
插入元素时间复杂度为O(1),删除时是O(n),因为后面的所有元素要向前移;
引入front指针和rear指针,前者指向队头元素,后者指向队尾元素的下一个位置。如图:

若a1,a2出队,此时队头有空闲,队尾插入元素会导致“假溢出”,如图:

此时,引入循环队列的概念:把队列的头尾相接的顺序存储结构称为循环队列。
由于rear可能比front大,也可能小,所以尽管它们只差一个位置就是满的情况,但也可能是相差整整一圈。所以若队列的最大尺寸为QueueSize,那么队列满的条件是(rear+1)%QueueSize == front。考虑到rear>front和rear
3.2 代码实现
3.2.1 循环队列的顺序存储结构
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
#define MAXSIZE 20 /* 存储空间初始分配量 */
typedef int Status;
typedef int QElemType; /* QElemType类型根据实际情况而定,这里假设为int */
/* 循环队列的顺序存储结构 */
typedef struct
{
QElemType data[MAXSIZE];
int front; /* 头指针 */
int rear; /* 尾指针,若队列不空,指向队列尾元素的下一个位置 */
}SqQueue;3.2.2 循环队列初始化
/* 初始化一个空队列Q */
Status InitQueue(SqQueue *Q)
{
Q->front=0;
Q->rear=0;
return OK;
}3.2.3 循环队列求长度
/* 返回Q的元素个数,也就是队列的当前长度 */
int QueueLength(SqQueue Q)
{
return (Q.rear-Q.front+MAXSIZE)%MAXSIZE;
}3.2.4 入队
/* 若队列未满,则插入元素e为Q新的队尾元素 */
Status EnQueue(SqQueue *Q,QElemType e)
{
if ((Q->rear+1)%MAXSIZE == Q->front) /* 队列满的判断 */
return ERROR;
Q->data[Q->rear]=e; /* 将元素e赋值给队尾 */
Q->rear=(Q->rear+1)%MAXSIZE;/* rear指针向后移一位置, */
/* 若到最后则转到数组头部 */
return OK;
}3.2.5 出队
/* 若队列不空,则删除Q中队头元素,用e返回其值 */
Status DeQueue(SqQueue *Q,QElemType *e)
{
if (Q->front == Q->rear) /* 队列空的判断 */
return ERROR;
*e=Q->data[Q->front]; /* 将队头元素赋值给e */
Q->front=(Q->front+1)%MAXSIZE; /* front指针向后移一位置, */
/* 若到最后则转到数组头部 */
return OK;
}4. 链队列
4.1 定义
队列的链式存储结构,其实就是线性表的单链表,只不过它只能尾进头出而已,简称为链队列。为了操作方便,我们将头指针指向链队列的头结点,队尾指针指向终端结点。
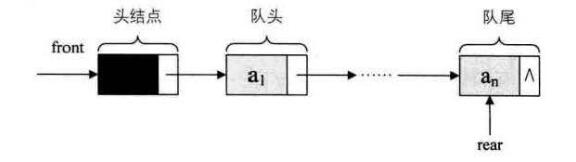
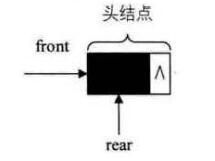
空队列时,front和rear都指向头结点。
链队列的结构:
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
#define MAXSIZE 20 /* 存储空间初始分配量 */
typedef int Status;
typedef int QElemType; /* QElemType类型根据实际情况而定,这里假设为int */
typedef struct QNode /* 结点结构 */
{
QElemType data;
struct QNode *next;
}QNode,*QueuePtr;
typedef struct /* 队列的链表结构 */
{
QueuePtr front,rear; /* 队头、队尾指针 */
}LinkQueue;4.2 操作
4.2.1 入队
入队操作,就是链表尾部插入结点。

/* 插入元素e为Q的新的队尾元素 */
Status EnQueue(LinkQueue *Q,QElemType e)
{
QueuePtr s=(QueuePtr)malloc(sizeof(QNode));
if(!s) /* 存储分配失败 */
exit(OVERFLOW);
s->data=e;
s->next=NULL;
Q->rear->next=s; /* 把拥有元素e的新结点s赋值给原队尾结点的后继,见图中① */
Q->rear=s; /* 把当前的s设置为队尾结点,rear指向s,见图中② */
return OK;
}头结点的后继结点出队,将头结点的后继改为它后面的结点。若链表除头结点外只剩一个元素时,则需将rear指向头结点。

/* 若队列不空,删除Q的队头元素,用e返回其值,并返回OK,否则返回ERROR */
Status DeQueue(LinkQueue *Q,QElemType *e)
{
QueuePtr p;
if(Q->front==Q->rear)
return ERROR;
p=Q->front->next; /* 将欲删除的队头结点暂存给p,见图中① */
*e=p->data; /* 将欲删除的队头结点的值赋值给e */
Q->front->next=p->next;/* 将原队头结点的后继p->next赋值给头结点后继,见图中② */
if(Q->rear==p) /* 若队头就是队尾,则删除后将rear指向头结点,见图中③ */
Q->rear=Q->front;
free(p);
return OK;
}5 循环队列和链队列的比较
时间上,基本操作都是常数时间,即O(1),不过,循环队列是事先申请好空间,使用期间不释放,而对于链队列,每次申请和释放结点会存在一些时间开销,如果入队出队频繁,则两者还是略有差异。
空间上,循环队列必须有固定的长度,所以就有了存储元素个数和空间浪费的问题。而链队列不存在这样的问题,尽管它需要一个指针域,会产生一些空间上的开销,但也可以接受。所以在空间上,链队列更加灵活。
总之,在可以确定队列长度最大值的情况下,建议用循环队列,如果无法预估队列的长度,则用链队列。
6 总结
其中,循环队列是为了避免数组插入和删除数据时需要移动数据而引入的。
参考:
《大话数据结构》