解读MixNet: Mixed Depthwise Convolutional Kernels
最近刚出的paper,来自于谷歌大脑:
https://arxiv.org/pdf/1907.09595.pdf
动机:为了探索到底多大的kernel size 能够实现高的准确率?
通过做了一个以深度可分离卷积 在MobeilNet上为基准的实验
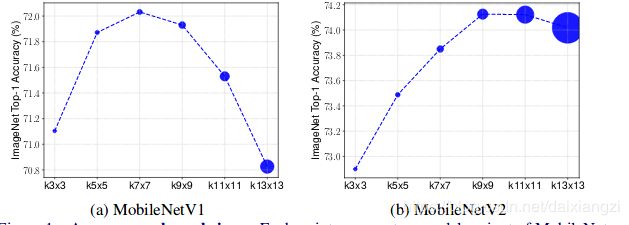
不同的网络最好结果对应着不同的kernel size.。large kernel size can capture more detail information,but cost ,small kernel size can capture edge structure information。
基于此提出了mixed depthwise convolution

普通的深度可分离卷积是把输入通道channel大小为M,分成M组,然后对每组用同样的kernel size 进行卷积计算。
但是,这里提出的MDconv 是把输入通道channel大小为M,分成C组,然后对每组用不同的的kernel size 进行卷积。
总之是:不同的kernel size 提取的特征不一样,这里相当于做了一个特征融合。
可以被考虑作为Depthwise Convolution 的替代模块。
这里是利用 tensorflow实现的MDconv
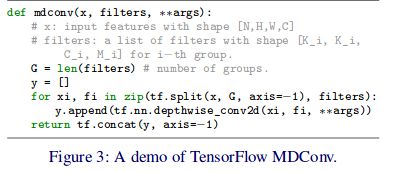
MDConv设计原则
Kernel size per Group:
从3*3开始,每一组增加2,即第i组的kernel size 为2i+1。
比如,4-group MDConv always uses kernel sizes {3x3, 5x5, 7x7,9x9}.
Channel Size Per Group:
这里提出了两种方法:
第一种:等分,就是每组分同等数量的filters。
第二种:指数分割,第i组将会拥有2^(-i) 的filters。
比如,4-group MDConv with total filter size 32, the equal partition will divide the channels into (8,8, 8, 8), while the exponential partition will divide the channels into (16, 8, 4, 4)
Dilated Convolution:
加入空洞卷积在减少参数量的情况下,增大了感受野。
结果分析:
注:mdconv(35)表示使用了3*3,5*5两种kernel 。
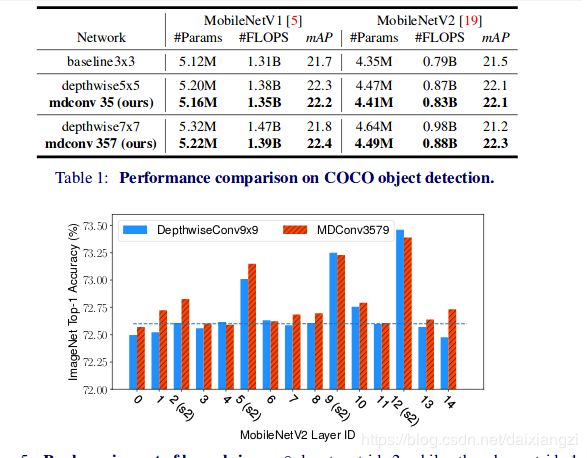
表一:
mdconv通常在实现和普通的Depthconv差不多准确率的情况下,参数量和浮点运算有相对的减少。
表二:
s2:表示stride 为2,其他则stride为1.
在大多数情况下,mdconv 的效果还是比depthconv的要好,但是对于某些stride为2的层,大的kernel size似乎更有效果
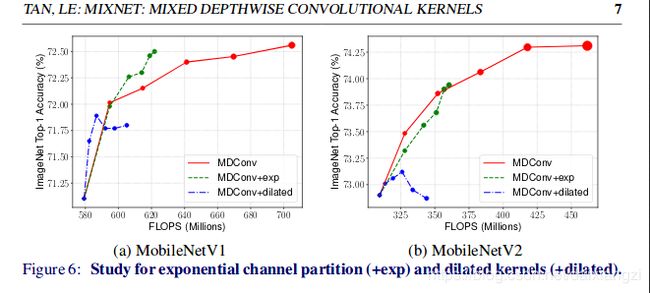
不同的网络,方法叠加效果不同。
最后一部分是利用NAS搜索出了一个MixNet网络结构。
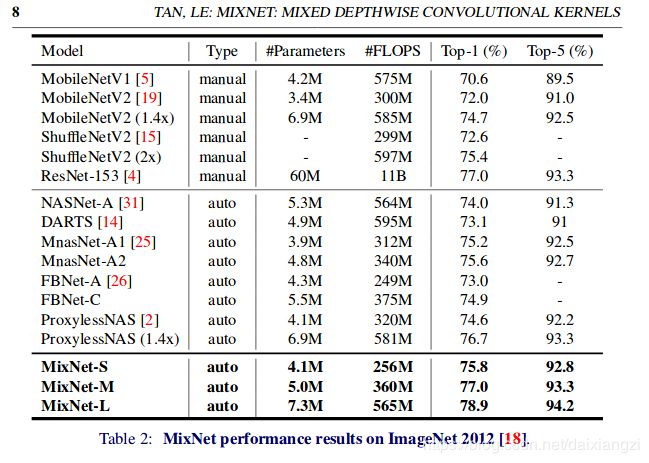
在imageNet做了对比实验。准确度相对于其他同等容量的网络都有提升。

FLOPS 对比
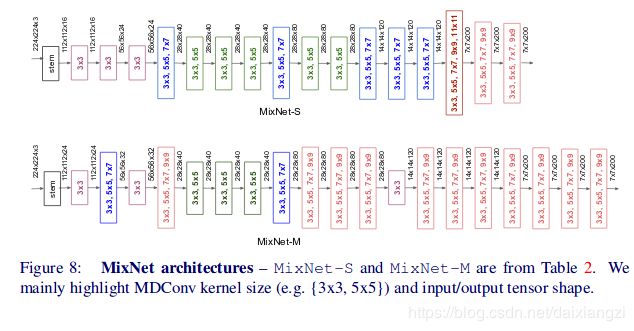
MixNet-S,MixNet-M结构。

迁移学习性能